Clear Sky Science · zh
带有残差连接的深度Inception神经网络用于泰米尔手写字符识别
在数字时代保存手写文字
从古老的棕榈叶手稿到日常笔记,泰米尔语的书写遗产很大一部分仍以纸张形式存在。将这些丰富的手写页面转换为可搜索的数字文本,对于保存文化、支持教育和构建更好的语言技术至关重要。本文介绍了一种名为 TamHNet 的新计算机视觉系统,它可以以近乎完美的准确率读取泰米尔手写文本,即便字形彼此间非常相似也能分辨。
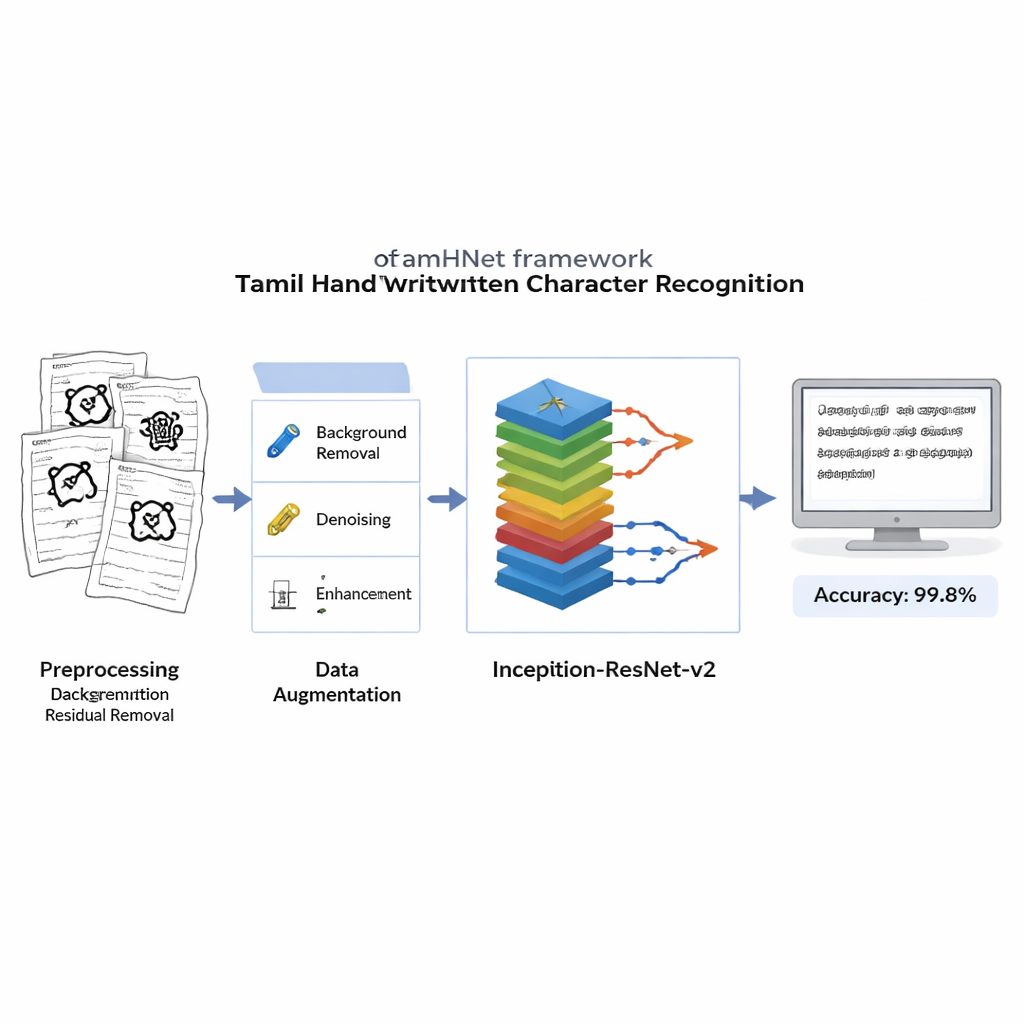
为什么泰米尔字母对计算机很难
泰米尔语有超过8000万人使用,采用包含247个字符的书写系统,包括元音、辅音以及两者的许多组合。许多字母仅由细小的卷曲或额外笔画区分,且书写者在书写每个字符时差异很大。像 எ/ஏ 或 ஒ/ஓ 这样的对看起来乍一眼几乎相同,而像 ல 和 வ 这样的字符也容易相互混淆。早期的计算机程序乃至现代的机器学习系统常常在这些细微差别上遇到困难,导致单词识别错误和文献数字化不可靠。
构建真实世界的手写数据集
为了在现实条件下训练和测试他们的系统,研究人员创建了一个新的泰米尔孤立字符数据集,采集自1000名大学生的手写样本。他们没有依赖合成或计算机生成的图像,而是收集了真实的笔迹字符,涵盖12个元音、18个辅音和214个常见组合。团队细致地对这些样本进行了标注,并将数据集公开发布,以便其他研究组进行方法比较和后续工作。通过将字符组织为104个基础符号来覆盖全部247个字符,他们在减少冗余的同时仍然表示了真实手写中出现的所有形态。
清理、拉伸与扩充图像
在任何学习开始之前,每张扫描图像都会被清理以去除噪声背景、污迹和不均匀的光照,同时保留定义字符的细微笔画。图片被转换为清晰的黑白图像并调整为标准尺寸,使计算机以相同方式看到每个样本。为了使系统对不同的书写习惯具有鲁棒性,作者对图像施加受控的变形:他们微调图像中的关键点并应用平滑扭曲,生成每个字符的新版本,这些版本在人类看来仍属于同一字母。这个扩展的训练集帮助模型在字符被倾斜、压缩或以不寻常的比例写出时仍能识别它们。
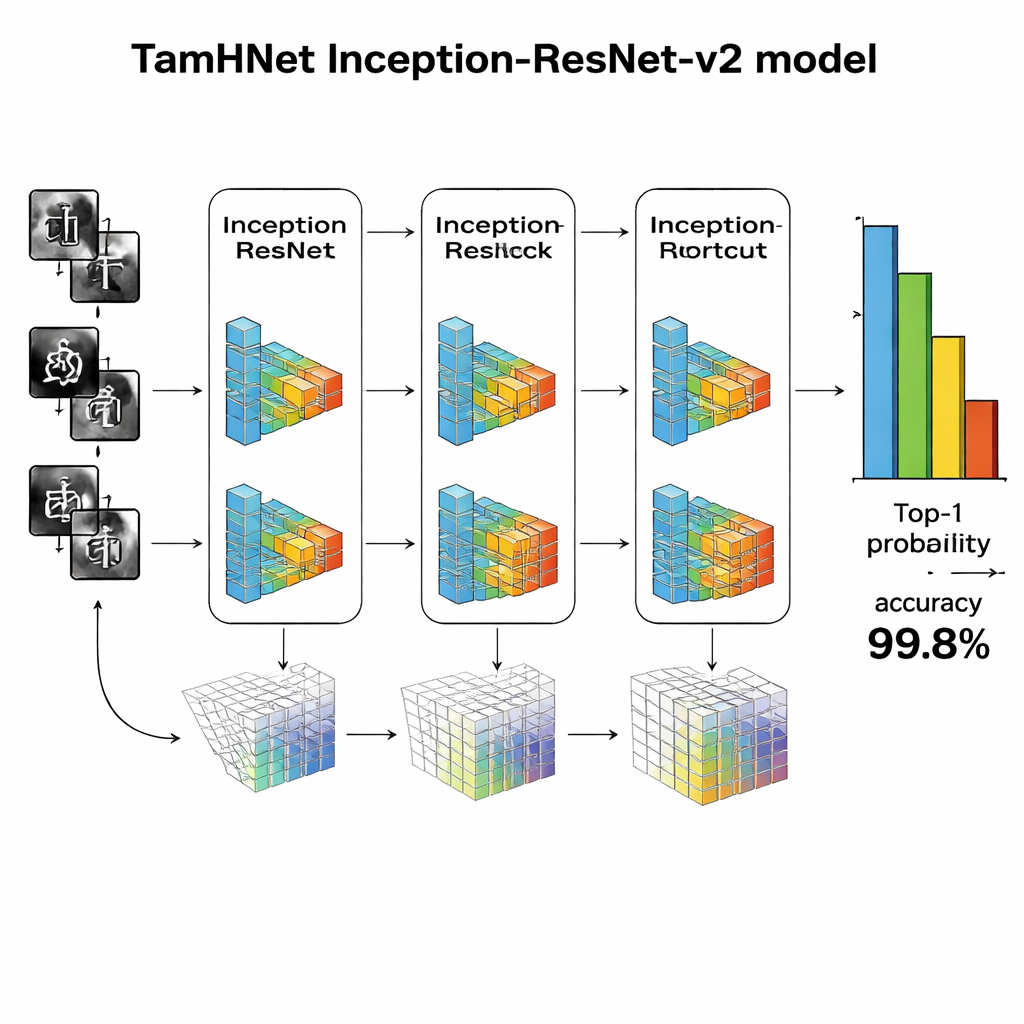
能够学习细微差别的深度网络
TamHNet 的核心是一种强大的深度学习架构,称为 Inception-ResNet-v2,最初用于通用物体识别。作者对该网络进行了适配和微调,以专门应对泰米尔手写。模型通过多层处理将原始像素逐步转换为更高层次的模式,例如边缘、曲线和字符部件。称为残差连接的特殊捷径连接稳定了训练过程,帮助网络关注相似字母间的小但关键的差别。作者并非一次性调整所有内部参数,而是选择性地“解冻”最有用的层并针对该任务进行调优。他们使用一种称为 Adam 的优化技术,该方法会自动调整每个参数变化的速率,使网络能够有效地从复杂且有时杂乱的手写中学习。
系统的识别效果如何
研究人员使用标准的识别质量度量在新数据集上评估 TamHNet。该系统在104个字符类别上达到约99.8%的准确率,优于基于支持向量机、传统卷积网络及其他先进深度学习设计的多种早期方法。详细测试显示,即便是形状极其相似的字母在大多数情况下也能被正确区分,统计曲线证实模型很少将一个字符误判为另一个。与以往的工作相比,这在泰米尔手写字符识别的可靠性上是一项明显的进步。
对读者和档案的意义
对非专业读者而言,最重要的结论是计算机在读取泰米尔手写方面变得显著更好。像 TamHNet 这样的系统可以为将大量笔记本、历史手稿和手写表单转换为可搜索数字文本的工具提供支持,所需的人为校对也很少。尽管当前模型尚未涵盖某些以点为特征的符号和旧有的书写变体,作者也提出了将其扩展到古代书写风格的计划。在实践层面,这项研究让我们更接近对泰米尔文献进行大规模、准确数字化的目标,有助于保护文化遗产并让书面知识更易为后代获取。
引用: Periyasamy, H., Natarajan, S. & Amirtharajan, R. Deep inception neural network with residual connections for Tamil handwritten character recognition. Sci Rep 16, 6053 (2026). https://doi.org/10.1038/s41598-026-36330-7
关键词: 泰米尔手写字符识别, 光学字符识别, 深度学习, Inception-ResNet, 数字化保存