Clear Sky Science · zh
基于目标引导的对比语言-图像预训练用于零样本目标识别
为拥挤的天空与海面配备更聪明的“眼睛”
现代安防与灾难响应系统依赖于高空与海上摄像头来发现飞机、舰船及其他关键目标。但在场景复杂、数据稀缺且设备型号不断更新的情况下,教会计算机分辨战斗机与客机、军舰与货船,出乎意料地困难。本文提出了 OG‑CLIP,一种新型 AI 系统,旨在通过将大规模先验知识与对关键目标更精准的视觉关注相结合,识别那些从未被明确训练过的军用与民用目标。
为何传统 AI 常常失准
大多数图像识别系统依赖于大量带标签的图片:每张图像对应一个固定的类别列表,如“猫”或“车”。在国防与遥感等专业领域,这种做法行不通——数据敏感、标注需要专家、装备种类繁多。较新的视觉-语言模型(如 CLIP)将图像与网络上收集的简短文字说明配对,使其能够识别以文字描述的新概念。然而在军事影像中,这些模型仍面临挑战:说明往往含糊,云层和海浪等背景占据了大量像素,且内部特征在不同硬件上运行时缺乏灵活性。OG‑CLIP 针对这三类问题提出了解决方案。
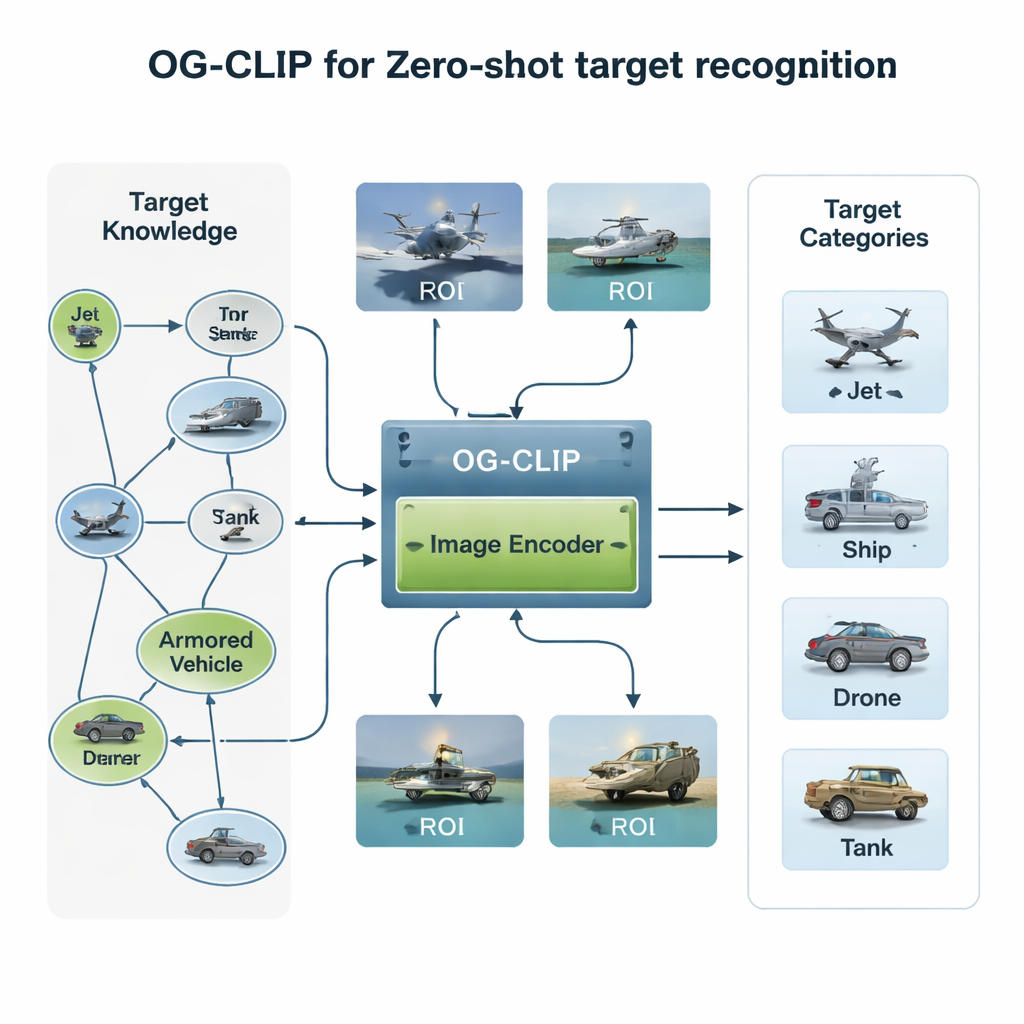
构建富含知识的训练世界
OG‑CLIP 的第一个要点是精心构建的训练语境。作者汇集了一个包含 5,000 种目标类型的数据库——涵盖战斗机、轰炸机到军舰与民用飞机——并将其组织为详尽的知识图谱。每条目包含结构化事实,例如射程、重量与武器配置,来源于公开的国防参考资料、百科与技术文档。随后他们从公共数据集、网络搜索、既有内部档案乃至游戏引擎生成的模拟场景收集了约一百万张图像。为保证数据可靠性,他们先用现有模型对图像进行聚类以发现异常,再由专家复核并过滤错误标签。最后,使用先进的视觉-语言工具将知识图谱转化为丰富的自然语言描述,使系统学到的不仅是“这是一架喷气机”,还包括“单通道客机带向上弯曲的翼梢小翼”或“飞翼形态的隐身轰炸机”等更细致的描述。
教会模型忽略噪声
第二项创新在于模型的“视线”所在。在许多卫星或航拍图像中,真实的舰船或飞机仅占画面中的一小块,周围被占据像素的天空、海面或地形干扰。OG‑CLIP 增加了一个感兴趣区域(ROI)模块,模仿人类只看关键目标而非整张画面的行为。一个先进的分割工具自动勾勒出图像中可能的目标,生成突出目标并弱化背景的软掩码。这些掩码连同原始图像一起输入模型的视觉骨干,从而使注意力自然而然地集中在诸如机翼形状、甲板布局或船体轮廓等区别性特征上。该即插即用的设计可在不重写核心架构的情况下加入现有系统,为其提供更“目标引导”的视角。

根据硬件自适应细节层次
第三个部分解决了一个实际但关键的问题:不同设备能够承受的细节级别不同。地面卫星站可能处理高维丰富特征,而小型无人机需要更快、更轻的计算。传统方法固定单一特征尺寸,或为不同尺寸训练多个独立模型。OG‑CLIP 则采用一种“套娃”式表示,在一个向量中打包多个细节层次的信息,类似嵌套的俄罗斯套娃。系统可以在不重新训练的情况下切取该向量的较短或较长部分——得到更粗或更细的图像描述。一个加权机制鼓励各层保留对分类最有用的信息,额外的损失项则推动各层之间保持语义一致性。
在实践中表现如何?
为评估 OG‑CLIP,研究者构建了一个包含 99 个目标类别的挑战性测试集,包括 51 种军用飞机、29 种军舰和 19 种民用或混合目标。关键点是,这些类别均未出现在训练数据中,因此系统必须依赖其学到的语言与视觉模式理解——即“零样本”测试。与若干强大的基于 CLIP 的基线方法相比,OG‑CLIP 将平均精度提高了超过 11 个百分点,整体达到 84.28%。在拥挤复杂的场景以及对相似型号之间的细微区分(如不同战斗机)上表现尤为出色,其中 ROI 模块与富知识描述给予了明显优势。消融研究表明,每个组件——知识图谱数据、ROI 聚焦和自适应表示——都带来了可量化的增益。
对现实世界监测意味着什么
对非专业读者而言,关键结论是 OG‑CLIP 朝着更可靠的安防与监测系统迈出了一步,这类系统能够从真实世界影像中更稳健地识别不熟悉的飞机与舰船,即便带标签样本稀少。通过将结构化专家知识、对兴趣目标的自动聚焦与可调节的细节层次相结合,该方法使视觉-语言 AI 更智能、更实用。除国防外,类似思路也可助力环境监测、灾害响应与工业检测系统在各种硬件上解析复杂场景。
引用: Zheng, C. Object-guided contrastive language-image pre-training for zero-shot target recognition. Sci Rep 16, 6425 (2026). https://doi.org/10.1038/s41598-026-36314-7
关键词: 零样本识别, 视觉-语言模型, 目标检测, 遥感, 知识图谱