Clear Sky Science · zh
基于视觉感知的深度学习Transformer用于通过特征提取对绘画和摄影进行分类
这对日常图像为何重要
在任何人只需几次点击就能生成逼真图像的时代,辨别一张图像是实拍照片、传统绘画,还是完全由算法创作,变得越来越困难。本研究探讨了现代人工智能如何自动区分人类创作的绘画与相机拍摄的照片,甚至能识别 AI 生成的图像,帮助保护艺术市场、档案与线上用户免受混淆与伪造之害。
艺术、照片与机器生成图像的兴起
在屏幕上,绘画与摄影乍看相似,但它们携带着非常不同的视觉指纹。绘画往往呈现可见的笔触、程式化的色彩与更抽象的构图,而照片通常包含更清晰的细节与自然光效。与此同时,新的图像生成器正以日益精湛的技巧模仿这两种媒介。博物馆、画廊、藏家与数字平台越来越需要能够快速且可靠判定图像类型的工具,既用于艺术品鉴定,也用于管理大量合成内容。
一种教机器“看”的新流程
研究者构建了一个基于视觉 Transformer 的完整图像分析流程,这是一种最初为处理语言而开发、现已适配图像任务的深度学习模型。他们在一个公开的 Kaggle 数据集上训练该系统,该数据集包含 1,361 幅绘画和 3,747 张照片,代表了多样的场景与风格。每张图像首先被标准化:调整尺寸、轻度裁剪,然后通过翻转、小角度旋转、亮度变化和去噪等增强,使模型能见到多种现实变体。经过这些准备后,视觉 Transformer 会将每幅图像划分为小补丁,并学习图像不同部分在整幅画面中的相互关系。 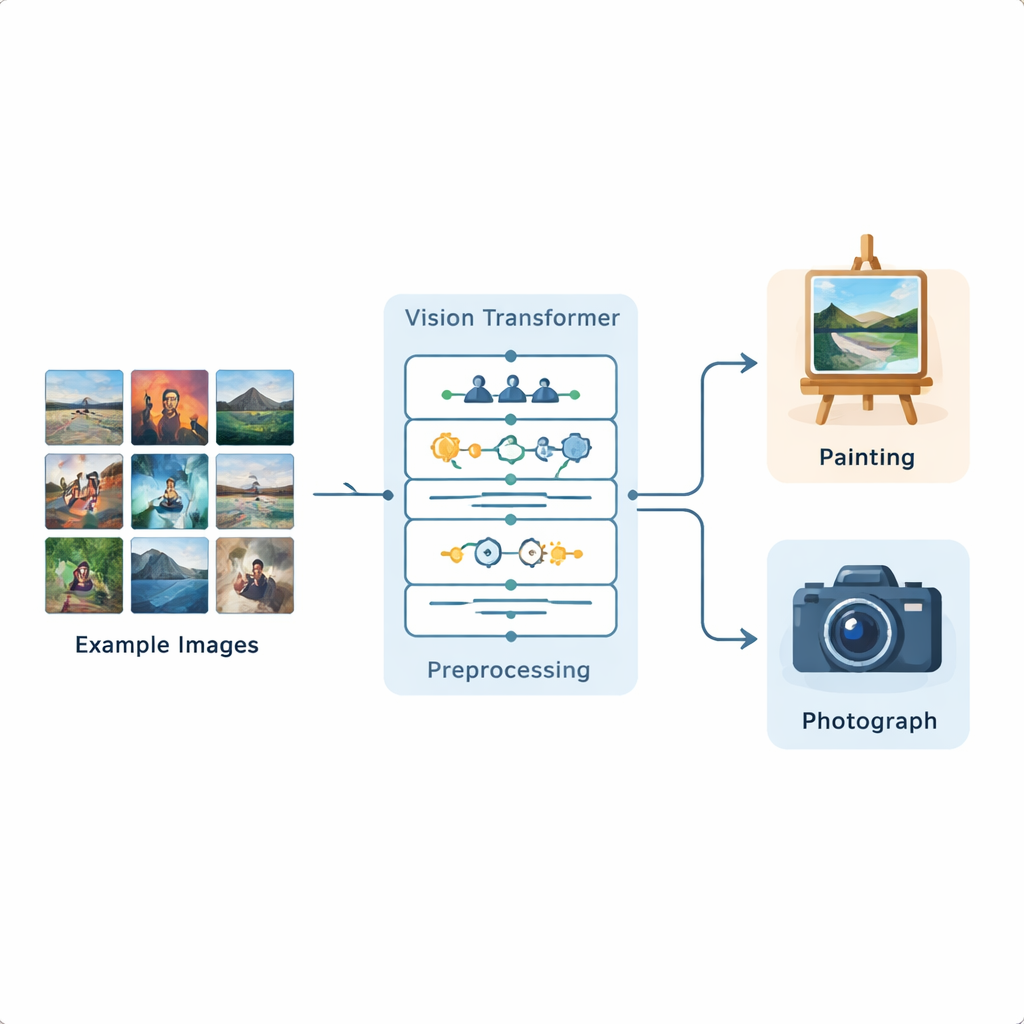
模型如何关注恰当的细节
不同于早期主要关注局部模式的神经网络,视觉 Transformer 使用一种“注意力”机制来决定图像中哪些部分对当前任务最重要。它实际上会为每个补丁评估应当对其他补丁关注的强度。这使其更善于察觉全局结构:色彩在画布上的流动、光线如何照射场景、或纹理的重复方式。为了验证模型并非盲目猜测,作者还应用了一种名为 Grad-CAM 的可视化方法,高亮出影响每次判定的具体区域。对于绘画,这些高亮通常集中在笔触纹理和程式化区域;对于照片,则汇聚在细微边缘、真实表面与光照过渡处。 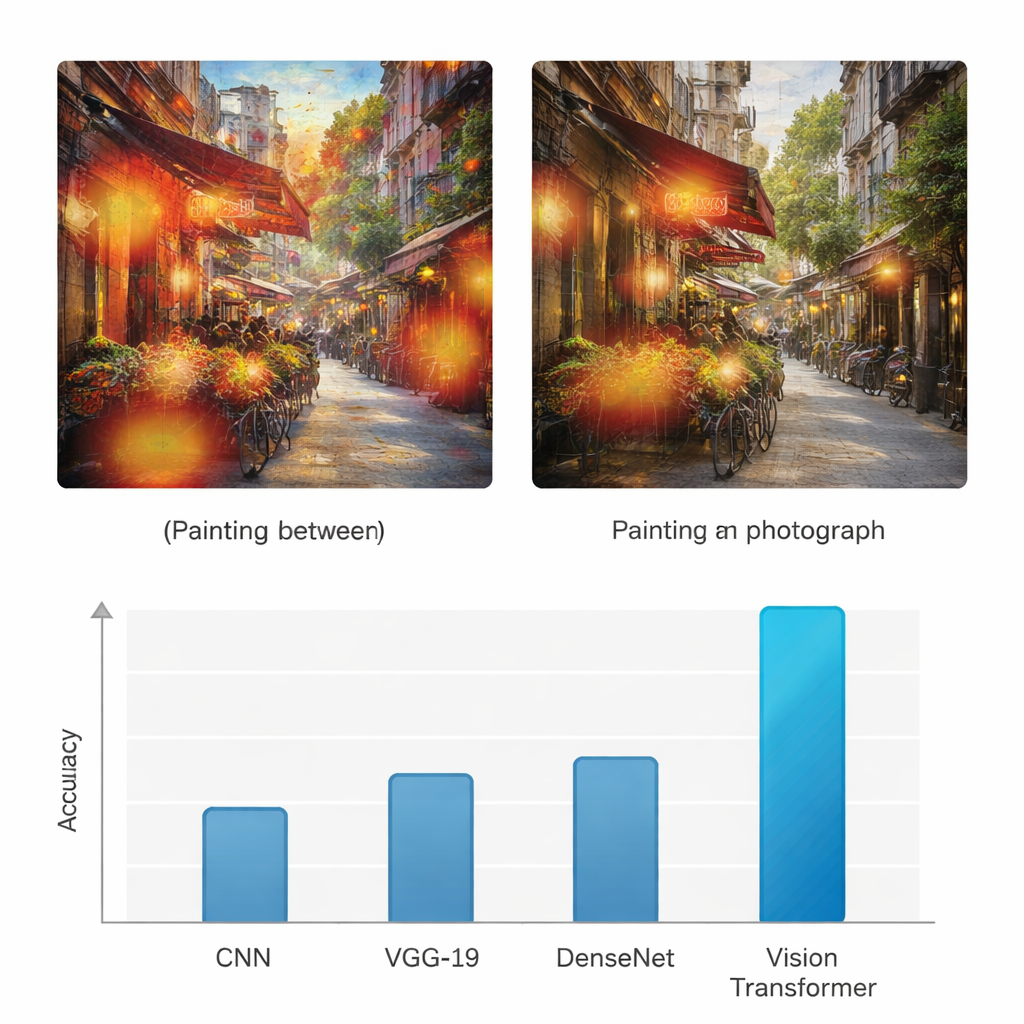
超越早期图像识别方法
为了检验该方法是否真正带来价值,研究将视觉 Transformer 与三种广泛使用的深度学习架构进行了比较:一种标准的卷积神经网络(CNN)、VGG-19 网络与 DenseNet。所有模型在相同数据集上训练与测试,并使用准确率、精确率、召回率与 F1 分数等常见指标进行评估,这些指标在两类判定中对正确识别与错误进行平衡。尽管基线网络的准确率处于 70% 中段到 80% 中段范围,视觉 Transformer 对绘画与照片均达到了 95% 的准确率,同时具有相似高的精确率与召回率。作者还进行了多项统计检验,以确认该提升并非偶然,表明基于 Transformer 的模型在重复试验与不同评估标准下都更可靠。
这对艺术、信任与技术意味着什么
研究结果表明,现代 Transformer 模型可以作为强大且可解释的工具,用于将绘画与照片区分开来,并标记模仿任一媒介的 AI 生成图像。对非专业读者而言,结论是计算机现在能检测到诸如笔触、表面平滑度或光照渐变等微妙线索——这些线索即便细心的人类观察者也可能忽视——并且可以在大规模场景中执行此类识别。此类系统可帮助画廊与藏家核验作品、协助策展人和档案员整理海量数字藏品,并支持在线平台对合成内容进行标注或过滤。随着图像生成器不断模糊现实与虚构的界限,诸如本文所示的方法为维护我们对所见之物的信任提供了切实可行的途径。
引用: Yu, L. Visual perception based deep learning transformers for classifying paintings and photographs through feature extraction. Sci Rep 16, 5326 (2026). https://doi.org/10.1038/s41598-026-36298-4
关键词: AI 生成图像, 艺术鉴定, 图像分类, 视觉 Transformer, 数字艺术分析