Clear Sky Science · zh
ADAT 新型时间序列感知自适应 Transformer 架构用于手语翻译
弥合沟通鸿沟
对于数以百万计的聋人和听力障碍者来说,去看医生或观看天气预报等日常事务往往比应有的更困难,仅仅因为熟练的手语口译员稀缺。本文提出了一种名为 ADAT 的新型人工智能系统,它能比许多现有系统更准确、更高效地将手语视频转换为书面句子,推动我们更接近可在手机、平板和医院电脑上实现的实时、广泛可用的手语翻译。
为什么手语对计算机来说很难
手语是富有表现力且复杂的语言,拥有自身的语法,并且依赖的不仅仅是手部动作。面部表情、身体姿态以及微妙的时序都会改变一句签语的含义。现代翻译系统常采用一种称为 Transformer 的强大 AI 结构,擅长理解书面或口语中的长句子。但面对高速视频——每秒 30 到 60 帧——这些系统可能变得缓慢,并且难以捕捉区分不同手势的快速、细微动作。它们还需要大量计算资源和训练时间,这使得随着手语演变保持系统更新更加困难。
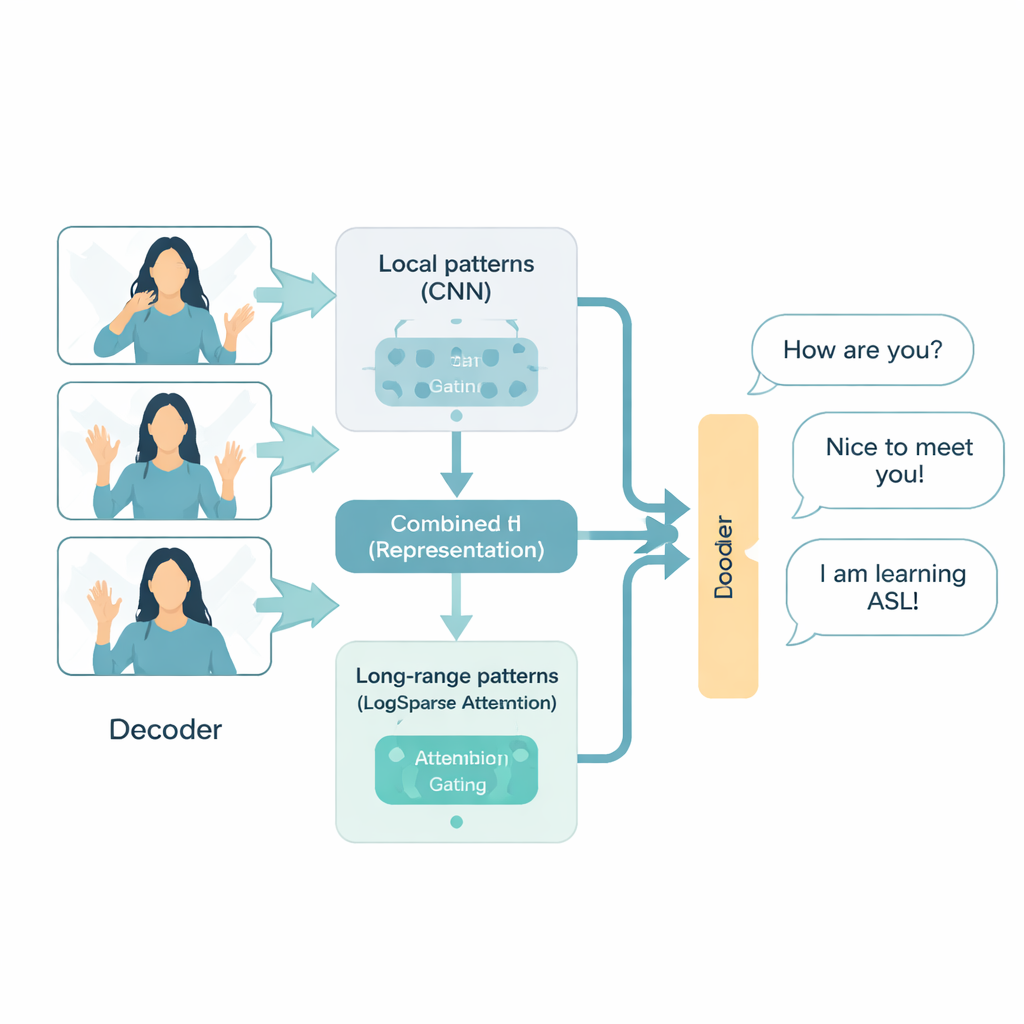
一种更聪明的手语“读法”
ADAT 架构专为手语视频设计,将其视为时间序列:随时间展开的快速视觉事件流。它结合了三个思想。第一,使用卷积神经网络这一成熟的图像技术,聚焦于局部模式,如手形和面部线索。第二,采用更高效的注意力机制,有选择地回顾视频中的关键时刻,而不是将每帧与每帧全部比较。第三,一个自适应“门”学习如何在细粒度的短期信息与更广泛的长期上下文之间进行融合,动态决定在句子不同部分哪个更重要。这些组成部分共同使 ADAT 能捕捉到既有手指的快速一掠,又有对话的整体结构,同时避免不必要的计算开销。
从手势到文字的两种途径
手语翻译通常可以分为两个主要步骤:先识别称为“词录”(glosses)的基本手语单元,然后将这些词录转换为口语或书面文本,这被称为手语→词录→文本。另一种方式是尝试直接从视频一步到位地生成文本,称为手语→文本。作者在两种方式上都测试了 ADAT,并将其与多个强力的 Transformer 基线模型(包括著名的 SLTUNET 系统)进行比较,使用了三个数据集:大型德语天气预报语料库、印度手语集合,以及作者为反映真实医患对话而创建的新美式手语医学数据集。
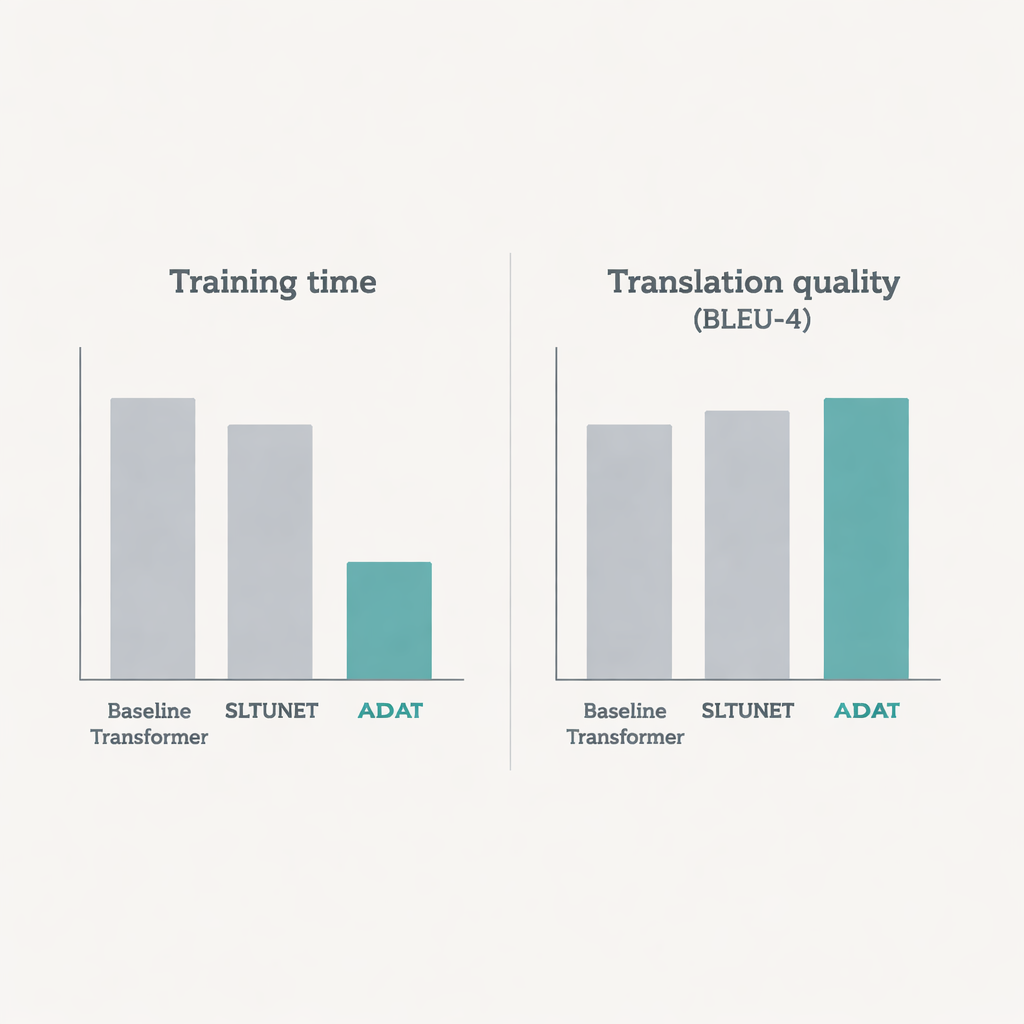
更快的训练、更清晰的翻译
在这些测试中,ADAT 在翻译质量(以标准 BLEU 分数衡量)方面要么与最优竞争模型持平,要么更胜一筹,同时训练速度明显更快。在两步的手语→词录→文本设置中,它给出了与经典 Transformer 相当或略优的分数,但平均将训练时间缩短了约五分之一。在更具挑战性的直接手语→文本设置中,ADAT 明显优于仅编码器、仅解码器和统一 Transformer 基线,通常将准确率提高约一个百分点或更多,同时训练速度也约快 20%。对底层数学的详细分析表明,ADAT 更有选择性的注意力与双路径设计大幅减少了所需的运算量,尤其是在处理长视频或高帧率视频时。
用于关键对话的新数据
为了确保这些方法能超越实验室环境,作者引入了 MedASL,这是首个聚焦医学交流的美式手语数据集。它包含 500 条独特且精心设计的句子,模拟患者与医疗专业人员之间的真实互动,并同时提供词录和文本注释。医学领域的专注很重要,因为在医院或诊所中的误解可能带来严重后果,而现有数据集很少覆盖这一领域。ADAT 在 MedASL 上表现强劲,尽管结果也显示任何系统要完全泛化到新的真实世界句子仍具有挑战性。
这对日常生活意味着什么
简而言之,这项研究表明我们可以构建既更聪明又更精简的手语翻译系统:它们训练所需的时间和计算资源更少,但更能捕捉手语的细微差别。ADAT 还不是一个可即插即用、适用于所有手语和所有情境的口译器,也仍落后于依赖大型预训练模型的系统。但通过关注对时间敏感的视频模式和效率,它为未来在日常设备上运行、支持多种手语并在医疗、应急响应与公共服务等关键场景中帮助聋人用户的实用工具指明了方向。
引用: Shahin, N., Ismail, L. ADAT novel time-series-aware adaptive transformer architecture for sign language translation. Sci Rep 16, 6551 (2026). https://doi.org/10.1038/s41598-026-36293-9
关键词: 手语翻译, 自适应 Transformer, 时间序列注意力, 医学美式手语, 可及性人工智能