Clear Sky Science · zh
用于少样本开放任务识别的元学习
为什么用极少的示例教会人工智能很重要
现代人工智能系统在识别人脸、动物和日常物体方面表现出色——但通常是在看到数以百万计的带标签图像之后。在许多真实情形中,例如诊断罕见疾病或发现工厂生产线上的新型缺陷,我们根本没有那么多数据。本文探讨如何训练能够仅凭少量示例就学会新视觉任务的人工智能模型,即便这些任务与模型训练时见过的内容差别很大。文章提出了一种名为 Open-MAML 的方法,旨在使这种灵活的低数据学习更可靠、更可预测。
从固定课堂练习到开放式突击测验
大多数关于“少样本学习”的研究是在高度受控的条件下评估人工智能系统。模型在训练和测试时面对的任务非常相似,例如总是要在恰好五个类别之间区分(称为“5-way”),且每个类别只有一个示例(“1-shot”)。这就像只针对五题小测并且每种题型只有一个练习样本来反复训练学生。现实部署则复杂得多:类别数量会变化,每个类别的带标签数据量也会随时间增减。作者将这种更现实的情况称为开放任务设置(open-task setting),在此情形下模型必须处理类别数和示例数都与训练时不同的任务。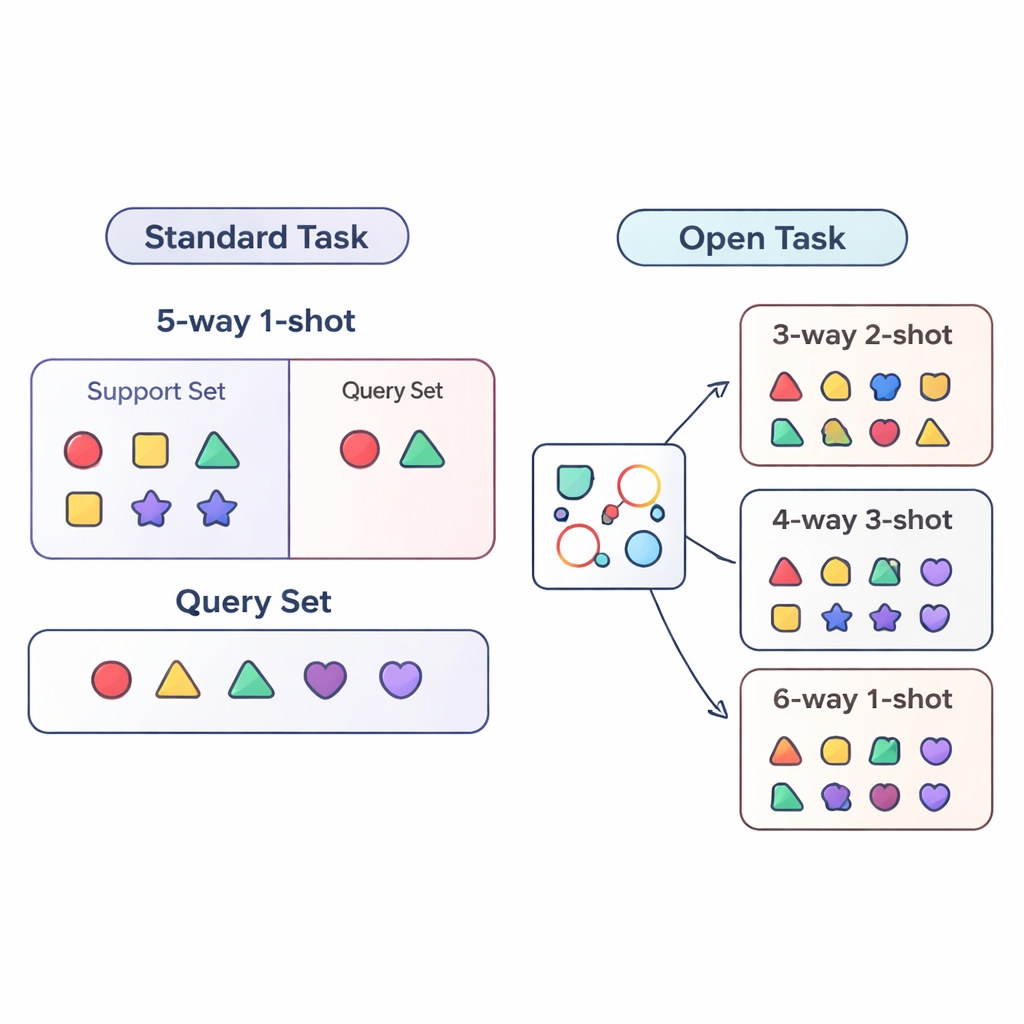
重新定义我们如何测试少样本学习者
为系统地研究这个开放任务世界,论文提出了三种评估方案。在跨类别(cross-way)方案中,仅类别数量发生变化:模型可能在五类上训练,但在三类或十五类上测试。在跨样本(cross-shot)方案中,每类示例数变化,从单张带标签图像到若干张。最难的情况是跨类别-跨样本(cross-way–cross-shot),此时类别数和每类数据量同时变化。作者还考察了视觉风格发生变化时的表现:在通用物体数据集上训练并在细粒度的鸟类数据集上测试。这些设置旨在揭示一种方法是否能真正超越单一、固定的训练范式而实现泛化。
Open-MAML 如何在运行中自适应
Open-MAML 建立在一种流行的元学习策略之上,称为模型无关元学习(MAML),其目标是训练模型使其能够通过少量梯度更新快速适应新任务。然而,标准 MAML 假设测试时的类别数与训练时相匹配,并使用固定的最终分类层。Open-MAML 引入了三项关键改进以打破这一限制。首先,它采用动态分类器构建(dynamic classifier construction):当新任务的类别比以往更多时,通过复制现有输出单元的平均值来创建额外的输出单元,为模型提供一个中性但合理的初始点。其次,它根据任务的类别数和示例数调整内部学习率,从而在数据稀缺或充足时都能保持适应稳定。第三,它增加了一种名为 AdaDropBlock 的正则项,该方法在训练期间临时屏蔽特征图中的连续区域,促使模型利用更多元的视觉线索,而不是过拟合于小而脆弱的细节。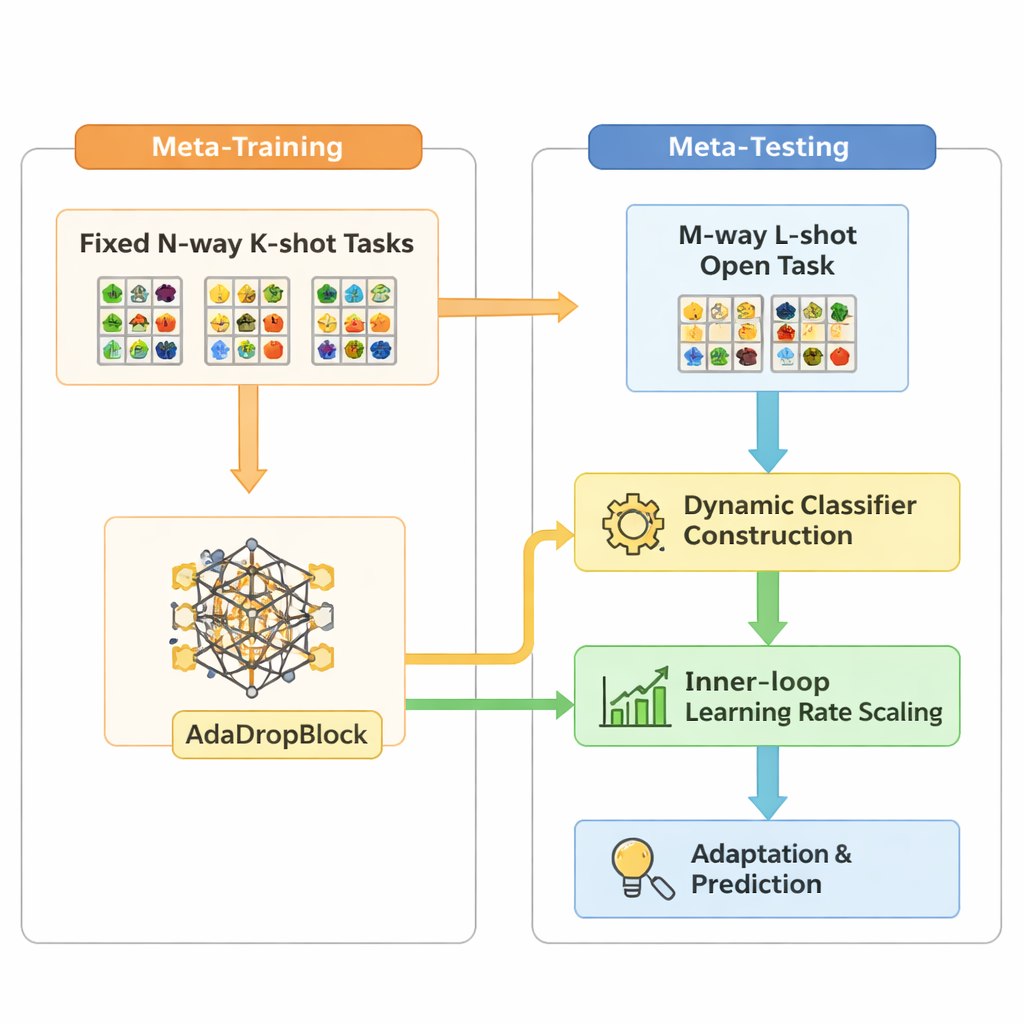
将灵活学习付诸考验
研究人员在标准少样本基准和新的开放任务场景下评估了 Open-MAML,并与若干知名基线方法进行了比较。这些基线包括针对每个任务从头训练的模型、使用强大预训练特征提取器加上微调分类器的模型,以及基于度量的方法(根据图像到类别“原型”的距离进行分类)。所有方法都使用相同的骨干网络,以保证差异来自学习策略而非架构。在数以万计的测试任务中,Open-MAML 一贯取得更高的准确率——当仅类别数或示例数变化时,通常高出 1–7 个百分点;当两者同时变化时,高出 3–6 个点。在类别更多、样本更多或转向鸟类数据集等更难的设置中,这些优势更为明显,表明其自适应机制在复杂且陌生的情形下确实有助益。
这对现实世界的人工智能系统意味着什么
对普通读者来说,关键结论是,一旦离开实验室的舒适区,并非所有少样本学习器都表现一致。在单一、固定的基准上表现出色的方法,可能在类别数量或带标签数据量发生变化时表现不佳。Open-MAML 表明,通过明确为这些结构性变化做准备——允许分类器增减规模、根据任务规模调整学习率、以及以任务无关的方式正则化特征——人工智能系统能更好地应对在实际应用中会遇到的不断变化的条件。在医学影像、卫星监测或工业检测等领域,类别集合和标签可用性持续波动,这种开放任务下的鲁棒性可能会使少样本学习在精心策划的研究基准之外更具可用性。
引用: Han, X., Shi, D., Wang, Z. et al. Meta-learning for few-shot open task recognition. Sci Rep 16, 5624 (2026). https://doi.org/10.1038/s41598-026-36291-x
关键词: 少样本学习, 元学习, 开放任务识别, 图像分类, 泛化