Clear Sky Science · zh
将方言替换作为一种对抗性方法来评估阿拉伯语自然语言处理的稳健性
为什么日常阿拉伯语会让智能计算机困惑
如今许多应用可以读取阿拉伯语文本来判断情感、归类新闻或回答问题。然而,这些系统大多从现代标准阿拉伯语(MSA)中学习,而真实的语言使用者在日常交流中常常混用地区方言。本文展示了仅将句子中一个词替换为埃及或海湾阿拉伯语,就能欺骗最先进语言模型的做法,这对依赖阿拉伯语人工智能的客户服务、媒体监测或网络安全等场景提出了警示。
一种语言,多种话语
阿拉伯语并非单一、统一的说法。MSA在学校、新闻和官方文书中使用,但日常对话依赖于如埃及语和海湾阿拉伯语等方言。这些变体在词汇、词形甚至句子结构上存在差异。例如,“现在”这样的简单词在不同地区有非常不同的形式。对人类读者而言,这些差异自然且易于理解;但对于几乎完全以MSA训练的计算模型,方言词汇可能显得陌生,把一条明确的句子变成令人困惑的内容。
把方言当作对AI的压力测试
为了探查阿拉伯语语言模型的脆弱性,作者设计了一个简单的两步测试。首先,反复查询模型以找出句子中对其决策影响最大的单词——通常是强烈的形容词、关键动词或主题名词。其次,用一个大型、经过精细调优的“方言化”模型将该单词替换为对应的埃及或海湾阿拉伯语形式。句子的其余部分保持不变,且对人类读者而言意义仍然相同。这使得被更改的句子成为现实的对抗性示例:一个微小、看起来自然的调整,旨在在不改变预期意思的情况下欺骗系统。
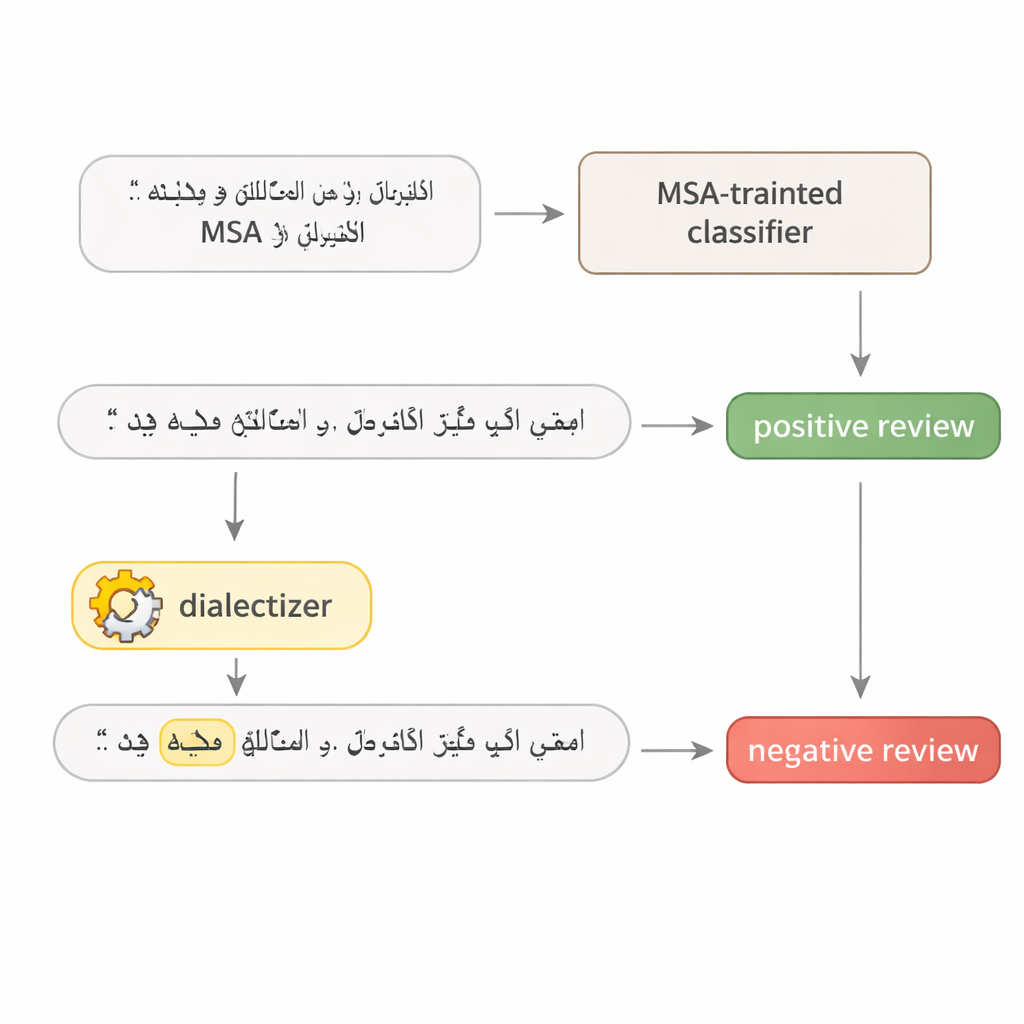
用酒店评论和新闻报道来检验
研究针对四个知名的深度学习模型发起攻击:两个大型变换器模型(AraBERT 与 CAMeLBERT)和两个较小的网络(一个卷积模型和一个双向LSTM)。它们在两个主要的MSA数据集上训练:用于情感分析的酒店评论和用于主题分类的新闻文章。从每个测试集抽取了1280个示例并应用方言替换程序。尽管每句只更改一个词,影响却十分显著。在酒店评论上,AraBERT在干净文本上的准确率为94%,但在海湾替换后降至约72%,在埃及替换后降至约65%。CAMeLBERT降幅更大,分别约为63%和55%。新闻分类器也受影响:卷积模型约损失18到22个百分点,LSTM也表现出类似的下降。
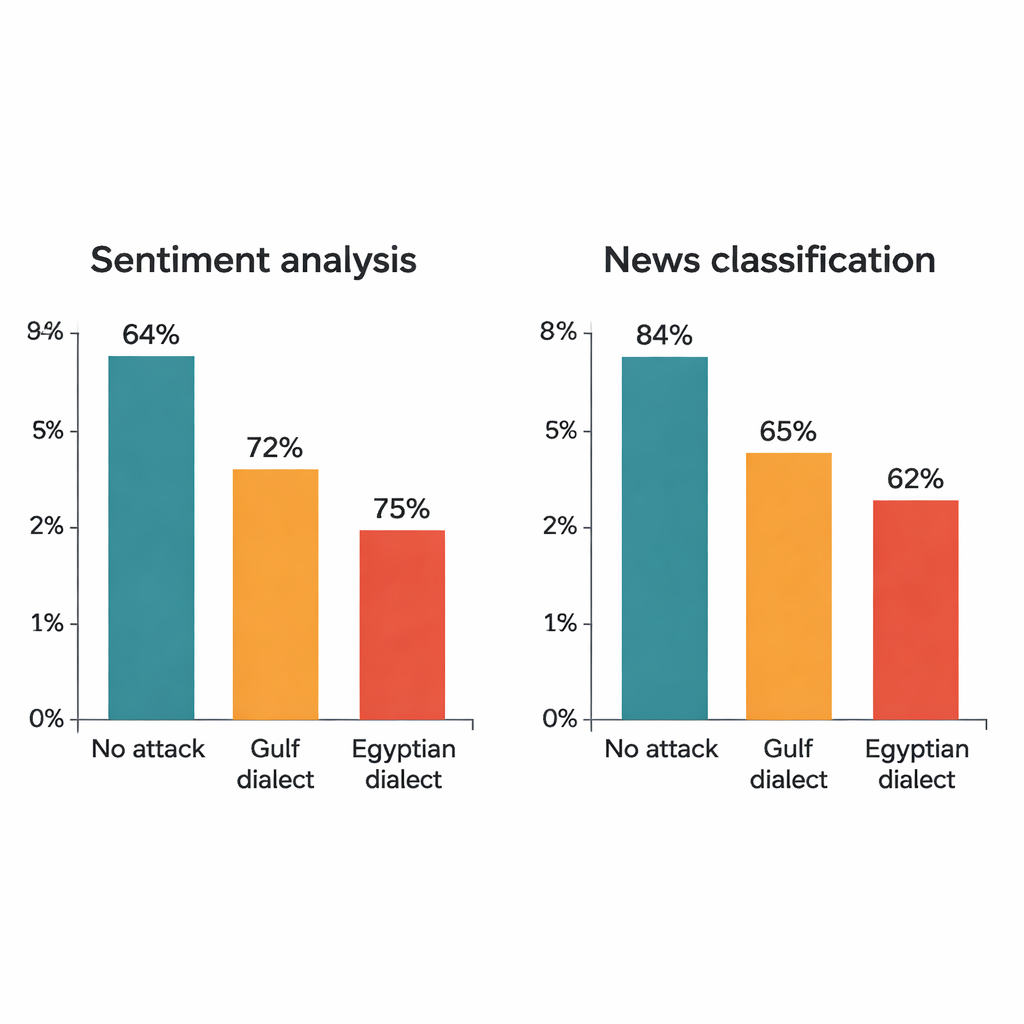
模型内部出了什么问题
深入观察发现,最脆弱的词与人们实际如何阅读文本是一致的。在酒店评论中,近一半被针对的词是带有明显情感倾向的形容词,如“好”或“糟糕”。在新闻文章中,被选中的大多是指示主题的名词和人名,如政治、体育或金融相关词。当这些触发词被替换为方言形式时,仅以MSA训练的模型常常无法识别它们。变换器模型尤其脆弱:它们对子词片段的依赖以及对少数高权重词元的注意,使得单个方言词就足以颠覆预测。较小的模型因在句子中分配注意力更均匀,虽然也会被欺骗,但略显更稳健。
埃及语与海湾语:方言并不相同
实验还表明,埃及阿拉伯语比海湾阿拉伯语更容易使模型失灵。语言学研究支持这一点:海湾变体在词汇和结构上常常更接近MSA,而埃及阿拉伯语则更多吸收了历史接触和其他语言的独特形式。因此,海湾替换有时与MSA原词相似到模型还能应对,而埃及替换更可能落在模型未见过的范畴之外。统计检验证实,观察到的性能下降并非随机——它们反映了当前系统处理阿拉伯语双语体(diglossia)时的系统性盲点。
这对阿拉伯语人工智能意味着什么
对普通用户而言,结论很简单:现有的阿拉伯语人工智能很容易被平常的方言词混淆,即便人类读者能完全清楚地理解文本。酒店评论中一个方言词就可能把模型的判断从积极改为消极,或错误标注新闻报道的主题。对研究者和开发者来说,信息是明确的:需要构建“意识到双语体”的系统,在训练中同时包含MSA和地区方言,并在评估稳健性时使用像方言替换这样的现实压力测试。在此之前,任何假设“阿拉伯语仅等同于MSA”的应用在实际环境中都面临严重误判的风险。
引用: Alshemali, B. Dialectal substitution as an adversarial approach for evaluating Arabic NLP robustness. Sci Rep 16, 5996 (2026). https://doi.org/10.1038/s41598-026-36252-4
关键词: 阿拉伯语自然语言处理, 方言变体, 对抗性样本, 情感分析, 文本分类