Clear Sky Science · zh
具有角点关键点提取特征的深度空洞上下文卷积生成对抗网络用于坚果分类
更智能的日常坚果分拣
从零食混合装到坚果酱,每年有数十亿颗坚果在工厂中流转,每一颗都必须按种类和质量分类。如今这项工作常由机器完成,但当坚果外观相似或拍照光照不同时时常困难。本文介绍了一种称为 DAC‑GAN 的强大全人工智能系统,能够以接近完美的准确率区分八种常见坚果,为食品行业带来更快、更便宜且更可靠的分拣方案。
为什么识别坚果如此困难
乍看之下,腰果和花生似乎容易区分。但在真实的生产线上,坚果可能倾斜、断裂、重叠或光照不足。传统计算程序依赖一些人工设计的简单特征,如颜色或平均形状,在条件变化时很容易失效。深度学习通过让计算机直接从图像中学习模式有所改善,但这些方法通常需要非常大且均衡的训练数据集。对于坚果,可能只有几千张标注照片可用,而且某些品种外观极为相似,导致错误和偏差预测。
制造更多且更好的训练图像
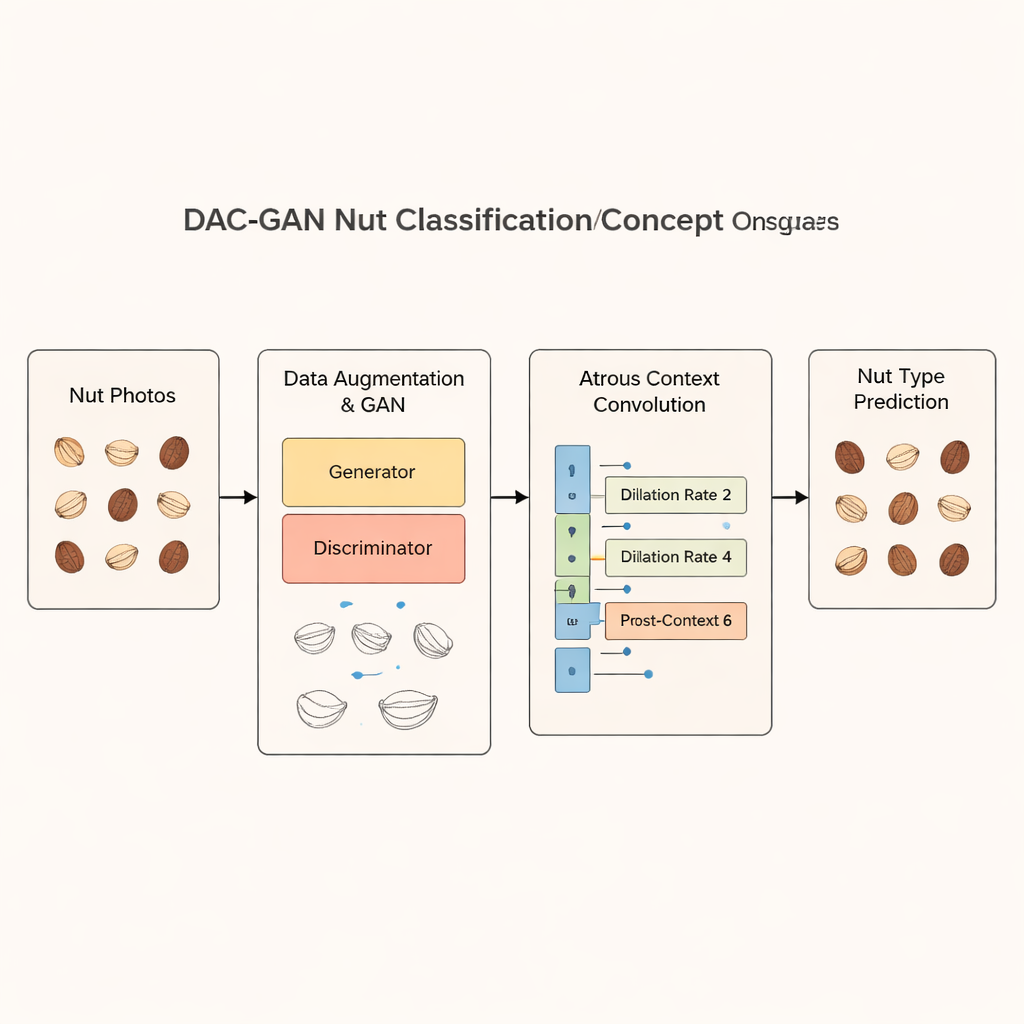
研究人员使用了一个公开的“常见坚果”图像集合,包含 4,000 张照片,均匀分布在八种坚果类别:巴西果、腰果、栗子、花生、山核桃、开心果、夏威夷果和核桃。要训练出稳健的模型,他们需要远超过此数量的样本。DAC‑GAN 通过一种称为生成对抗网络(GAN)的特殊神经网络来解决这一问题。GAN 的一部分生成器学习从随机噪声生成逼真的坚果图像,而另一部分判别器学习分辨真图与假图。随着两者的博弈,生成器变得足够擅长生成高质量、栩栩如生的合成坚果图像。将这些人工生成的图像与常规的翻转和旋转增强结合,团队将数据集扩展到超过 70,000 张图像,同时保持每个坚果类别完全平衡。
教模型关注坚果细节
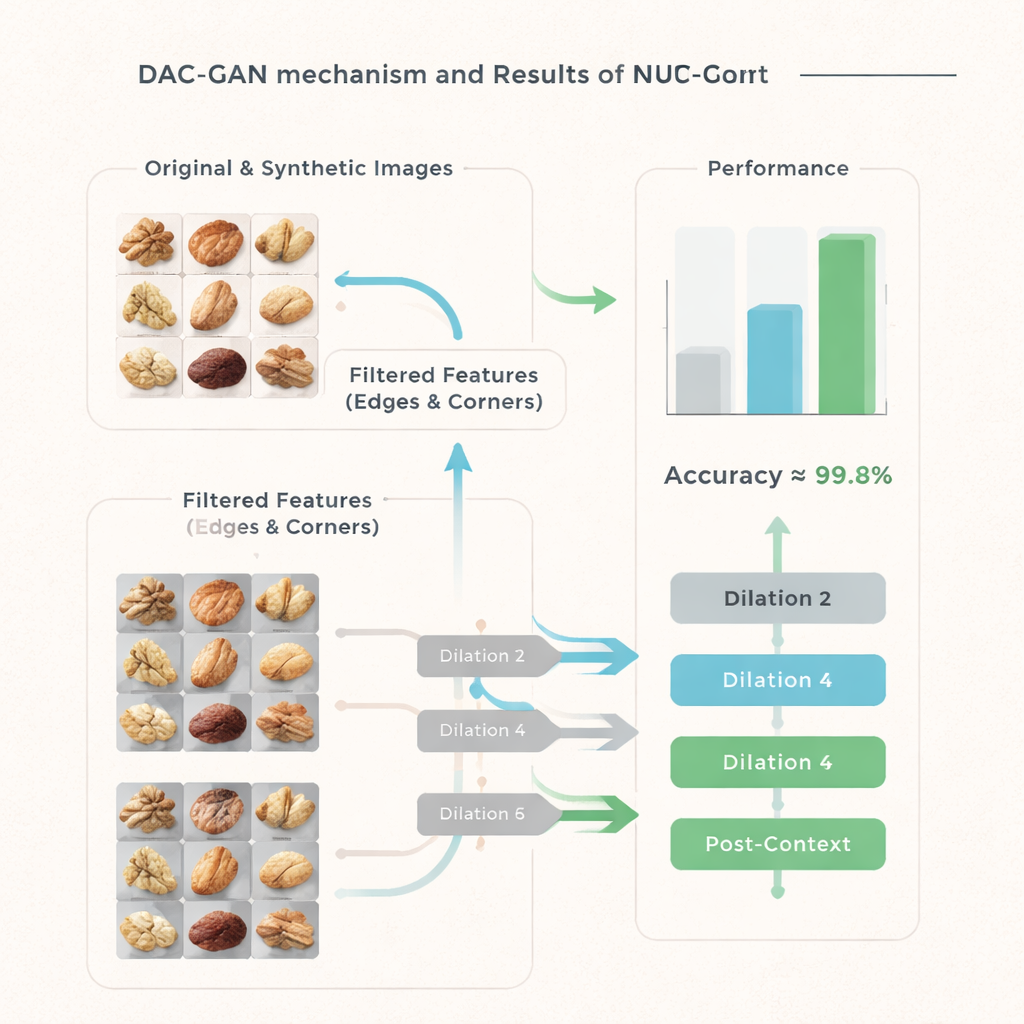
仅仅增加图像数量还不够;模型还必须关注正确的视觉线索。DAC‑GAN 引入了一个滤波步骤,将坚果照片转换为灰度图像,然后提取明显的轮廓、边缘和独特的角点。这些“角点关键点特征”捕捉到坚果形状弯曲处或表面纹理变化的位置,这些细节常常能区分不同品种。额外的滤波器还强调整体果仁轮廓和内部纹理模式。系统不是将原始照片直接输入分类器,而是使用这些锐化后的特征图像,从而突出几何形状和纹理,同时弱化干扰性的背景和颜色变化。
在多尺度上观察整个坚果
DAC‑GAN 的核心是对一种称为空洞(或扩张)卷积技术的改进。深度网络中的普通卷积层一次只看小块图像。空洞卷积通过拉开采样点的间距,使模型在不丢失分辨率的情况下获得更广的视野。作者在这一核心操作周围加入了“前置上下文”和“后置上下文”模块,它们总结整张图像并将该摘要反馈回该层。通过以不同空洞率运行三个这样的卷积,网络学会同时捕捉坚果表面的细小沟槽和整体轮廓,然后将这些视角结合为丰富的、具有上下文感知的表示,最后再做出判断。
效果如何?
团队对 DAC‑GAN 进行了广泛测试。他们将其与多种知名神经网络进行比较,从经典模型如 VGG 和 ResNet 到较新的基于变换器的设计,均在有无合成数据的条件下进行测试。在准确率、精确率、召回率和综合 F1 分数方面,DAC‑GAN 一贯以大幅优势超过所有替代方案。在真实坚果图像的保留测试集中,它能在 99.83% 的情况下正确识别坚果类型,在 800 个样本中仅出现 25 处错误。即便是最具竞争力的对手模型也落后数个百分点,详细统计显示 DAC‑GAN 的优势并非偶然,而是在统计上非常稳健。
这对食品行业及其他领域意味着什么
对非专业读者来说,结论很简单:通过巧妙地创造额外训练图像并教会网络关注边缘、角点和多尺度上下文,DAC‑GAN 能将一个视觉上细微的问题几乎完美地解决。就实际应用而言,这种方法可能促成自动化坚果分拣机器,能够以极少的错误处理大批量产品,提升质量控制并减少人工劳动。由于该方法具有通用性,它也可以被改用于其他食品或甚至需要在不理想成像条件下基于细微视觉细节区分的工业零部件。
引用: Devi, M.S., Jaiganesh, M., Priya, S. et al. Deep atrous context convolution generative adversarial network with corner key point extracted feature for nuts classification. Sci Rep 16, 6409 (2026). https://doi.org/10.1038/s41598-026-36238-2
关键词: 坚果分类, 深度学习, 图像增强, 食品分拣, 计算机视觉