Clear Sky Science · zh
用于MISO下行系统联合波束赋形与RIS相位优化的改进优先级DDPG算法
引领下一波无线通信的智能表面
随着我们的手机、汽车和传感器对更快、更可靠连接的需求不断增加,现有的无线网络正被推向极限。本研究探讨了一种使未来6G网络更环保且更可靠的新途径:将建筑物上的“智能”反射表面与一种能够自主学习如何以更低能耗引导无线信号的人工智能技术相结合。
把墙变成有用的信号镜
未来的6G系统必须为大量设备提供高数据率、极高可靠性和极低时延。仅靠传统基站要满足这些需求,将需要大量额外的硬件和能量。可重构智能表面(RIS)提供了一种不同的方式:在面板上布置许多微小、低功耗的单元,这些单元可以以可控的方向反射入射无线波,类似于可编程的镜面。通过精确选择这些反射的相位,RIS可以把信号绕过障碍物、增强弱链路并降低干扰,而无需主动发射功率。这为网络设计者在扩展覆盖范围和提高能效时提供了一个强大的可调手段。
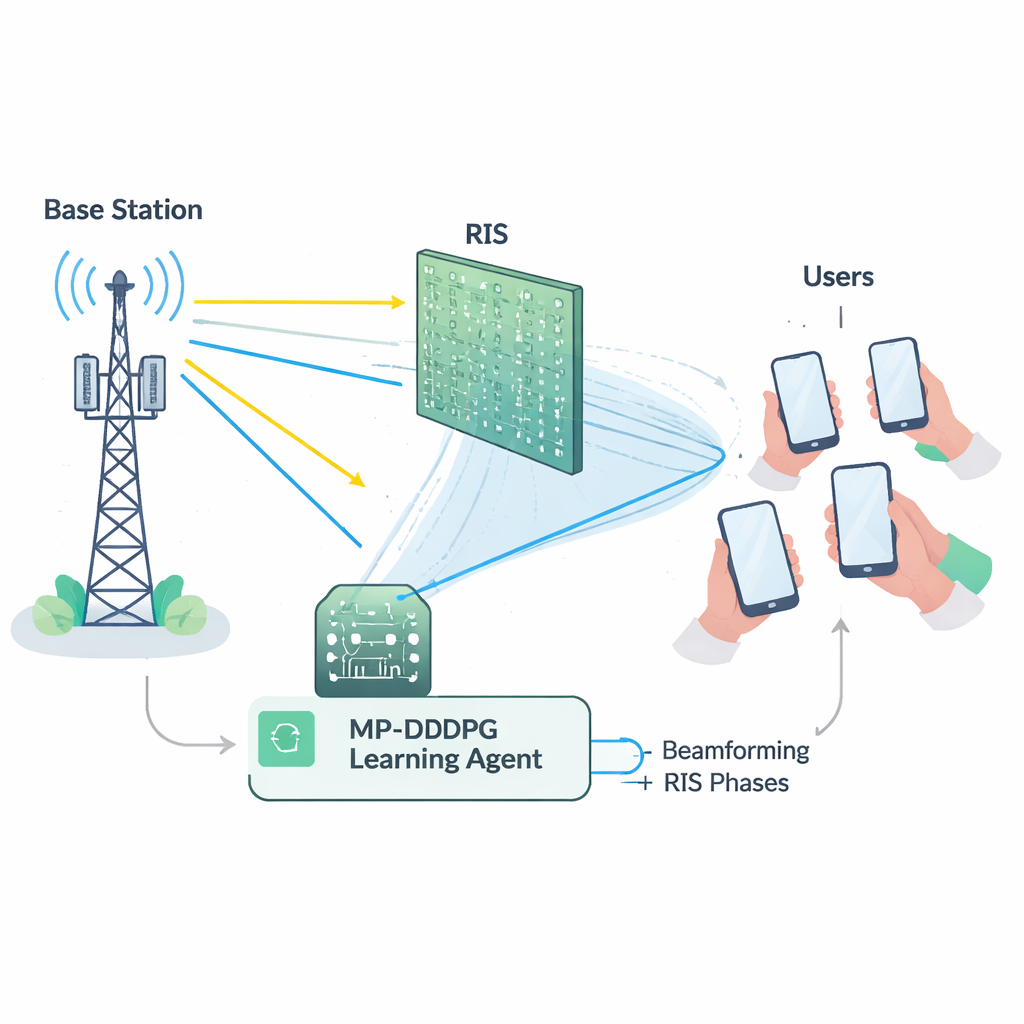
网络面临的艰难平衡
有效利用RIS并不简单。基站必须决定如何指向天线(波束赋形),而RIS必须为其众多反射单元设置相位。这些选择紧密相关,并且必须同时满足多个约束:将总发射功率控制在最大值以下、保证每个用户的最低信号质量,以及遵守RIS硬件的物理限制。从数学上讲,这一联合调优问题是高度非线性且“非凸”的,意味着传统的优化工具往往在规模扩大时变得缓慢、脆弱或陷入次优解。更何况,在实际部署中,准确测量每个无线链路的详细状态(即信道状态信息)本身也代价高且容易出错。
让AI智能体学会波束控制
为了解决这些难题,作者构建了一个基于深度强化学习的学习智能体,这是一类通过与环境反复试验摸索来发现有效策略的人工智能方法。他们的方法称为改进优先级深度确定性策略梯度(MP‑DDPG),它观察当前网络状态——包括先前的波束方向、RIS设置、接收功率和信号质量——然后选择新的波束赋形和RIS相位值。每次决策后,智能体会获得一个奖励,该奖励同时鼓励三点:降低发射功率、满足用户的服务质量目标,以及遵守基站的功率上限。经过大量模拟交互,智能体逐步学会一种在这些目标间取得平衡的控制策略,而无需显式知道无线信道的数学公式。
通过聚焦关键经验更快学习
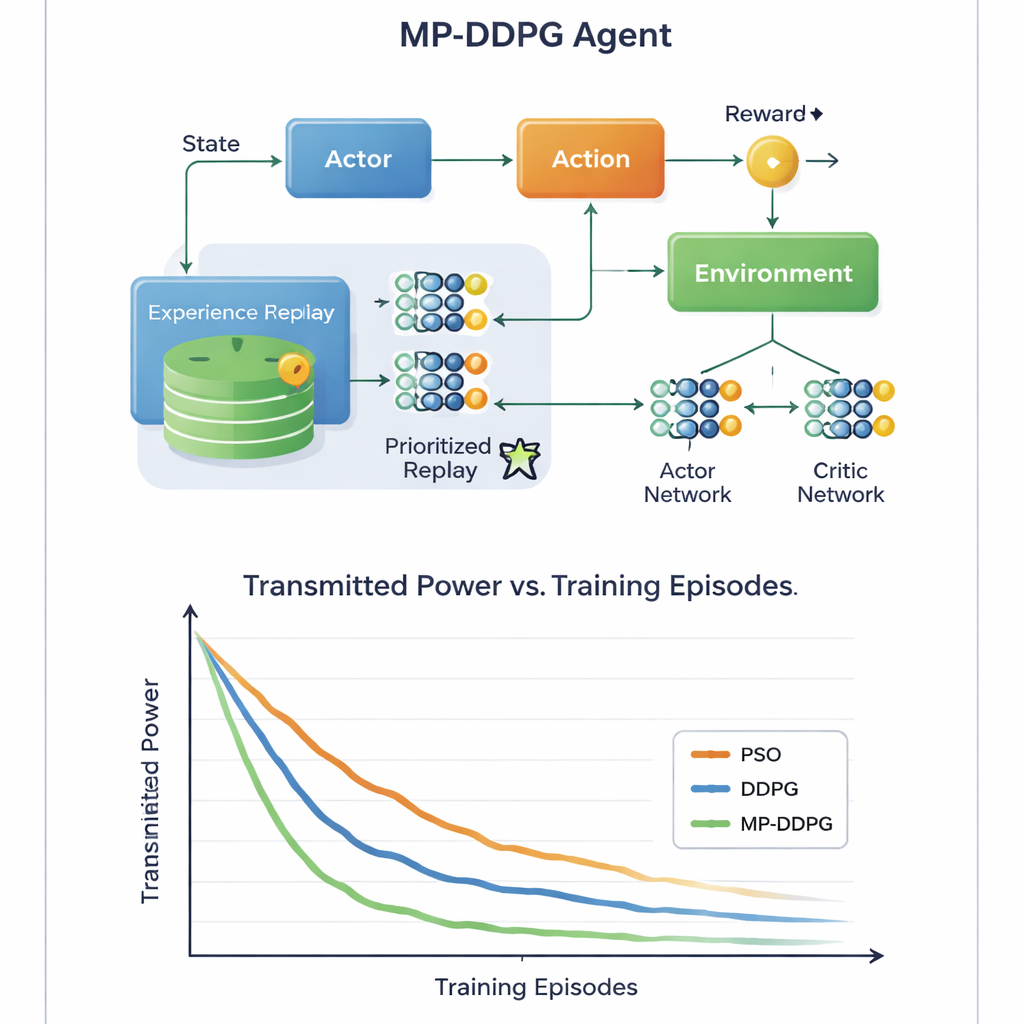
该算法的关键创新在于它如何从过去经验中学习。传统方法在训练时将大量过去情形存储起来并随机抽样,这可能既低效又缓慢。MP‑DDPG则为每个存储的经验分配优先级,该优先级既取决于其奖励,也取决于该状态与其最近邻状态的差异。既信息量大又多样的经验会被更频繁采样,而冗余的经验则被忽略。这种“改进的优先重放”使得每一步学习更有价值,加快了收敛并帮助智能体避免陷入糟糕的局部解。作者还分析了这一机制带来的额外计算开销,并表明尽管记账工作比基础方法更复杂,但更快的学习速度在实践中能够弥补这些成本。
更少硬件、更绿色的信号
通过对下行场景进行详细的计算机仿真,研究将MP‑DDPG与两种替代方法进行了比较:传统的粒子群优化方法和原始的DDPG学习算法。新方法在更少训练周期内持续达到更低的发射功率,并且在相同性能水平下使用更少的RIS单元和更少的基站天线。简单来说,网络学会从每块反射单元和每根天线中榨取更多收益。对非专业读者而言,这表明通过让AI控制器智能地同时调节基站的波束和邻近墙体上的智能表面,未来的6G网络有望以更少的能量和更少的硬件提供强大且可靠的信号,从而帮助我们的日益互联的世界变得更可持续。
引用: Shukry, S., Fahmy, Y. Modified prioritized DDPG algorithm for joint beamforming and RIS phase optimization in MISO downlink systems. Sci Rep 16, 5942 (2026). https://doi.org/10.1038/s41598-026-36179-w
关键词: 可重构智能表面, 6G无线, 深度强化学习, 波束赋形优化, 节能网络