Clear Sky Science · zh
使用人口统计、人体测量和人格特征的机器学习对大学生食物成瘾的预测
为什么我们与食物的关系会失去控制感
很多人会开玩笑说自己“对巧克力或快餐上瘾”,但对一些人来说,对食物的渴望和失控感是严肃且令人痛苦的。大学生尤其脆弱,需应对压力、新的自由以及不断变化的身体。本研究提出了一个及时的问题:计算机程序能否通过简单的背景信息、身体测量和人格特征,学会识别哪些学生面临较高的食物成瘾风险?如果可以,我们或许有一天能更早发现问题,并在饮食习惯演变为长期健康问题之前提供针对性的支持。
从多角度审视学生群体
研究人员与伊朗阿瓦士的210名大学生合作,年龄在18至35岁之间。每位学生提供了年龄和教育水平等基本信息,报告身高和体重以便计算身体质量指数(BMI),并完成了标准人格问卷。他们还接受了一份简短的耶鲁食物成瘾量表筛查,该量表用于判断某人是否对高度美味的食物表现出类似成瘾的模式,例如强烈的渴望、减少摄入的尝试失败或明知有负面后果仍继续进食。只有30名学生符合食物成瘾的标准,而180名不符合,这反映出此类问题在总体中占比相对较小。
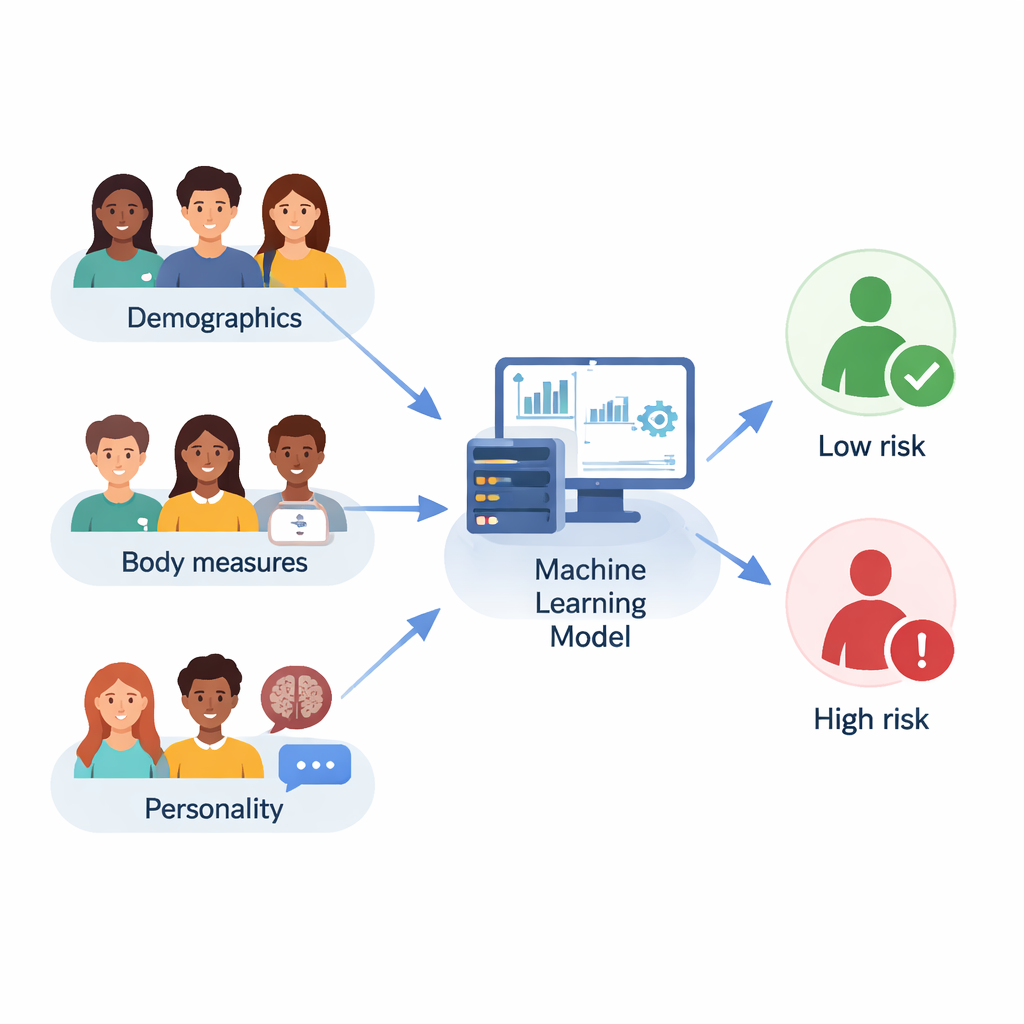
平衡不均衡的数据并训练智能模型
由于被归为食物成瘾的学生数量远少于非成瘾者,数据集存在不平衡。这种不平衡会误导计算模型,大多数情况下预测为多数组而忽视高风险少数群体。为应对这一点,团队采用了两种数据处理技巧。首先,他们应用了一种称为Tomek链接的方法,谨慎地移除那些位于多数组与少数组之间、容易混淆的多数组样本。然后他们使用SMOTE生成少数组的真实感合成样本以平衡数量。只有训练数据经过了这些处理;一组未作修改的独立测试数据被保留用于检验模型在新、未见学生上的表现。
测试多种算法
研究者没有依赖单一数学方法,而是比较了十种不同的机器学习模型,从逻辑回归和k近邻等简单方法到更先进的“集成”方法,例如随机森林、梯度提升、LightGBM和CatBoost。他们还尝试了十二种特征选择策略来决定哪些问题和测量最具信息量,并使用交叉验证与自动化搜索来调整每个模型的参数。总体表现通过若干指标评判,包括准确率(模型预测正确的频率)、F1分数(在捕捉真实病例与减少误报之间的平衡)以及ROC曲线下面积,后者衡量模型将高风险与低风险个体区分开的能力。
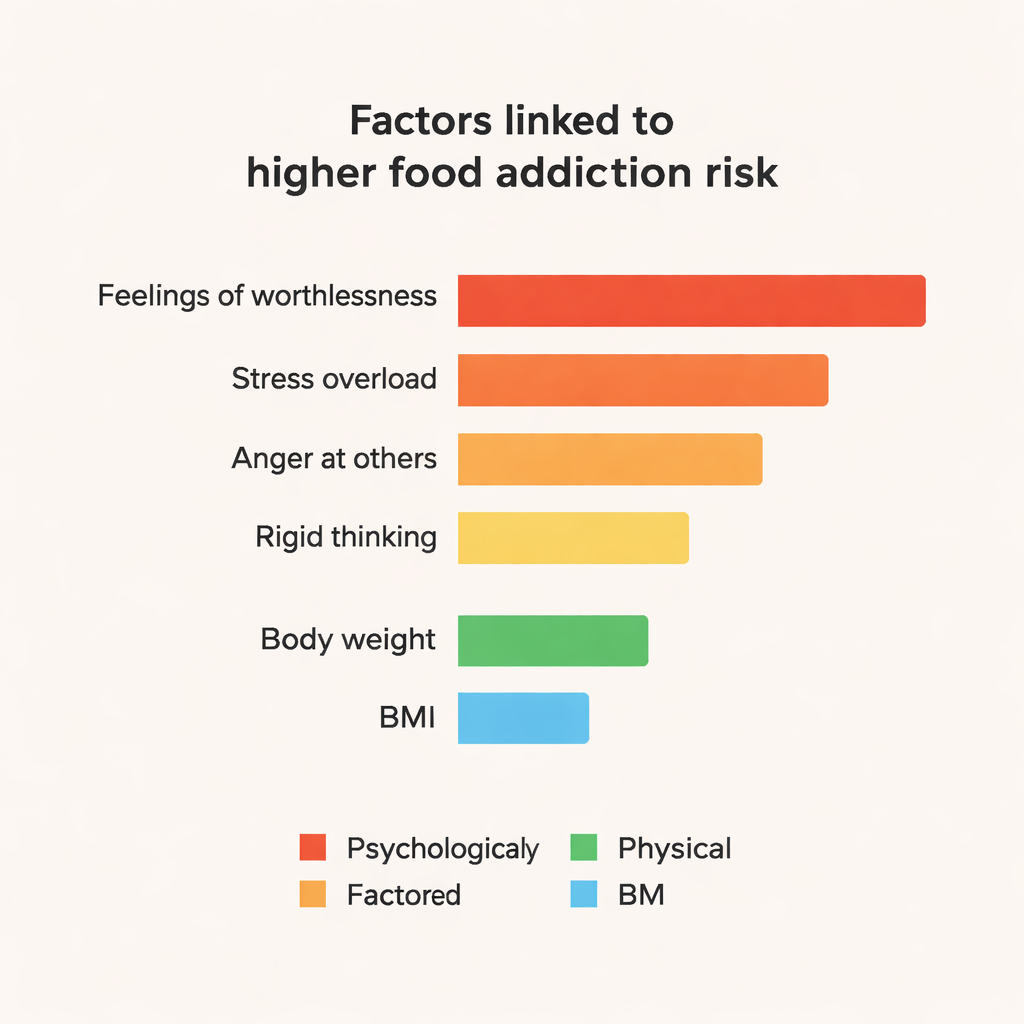
驱动预测的隐藏因素
集成模型,尤其是CatBoost和随机森林,稳定地优于更简单的方法,在这个小型数据集中达到约84%的准确率和约0.84的F1分数。为了超越“黑箱”式的预测,团队使用了一种名为SHAP的工具来探查哪些特征促使模型将某人标记为食物成瘾。突出的影响因素是心理层面的:诸如“有时我感到完全没有价值”这样的强烈陈述、在压力下感觉“崩溃”、频繁因他人对待而愤怒、情绪紧张以及僵化、缺乏弹性的思维。体重和BMI也有影响,但相比这些情绪和人格相关信号其作用较次。与积极情绪和良好组织能力相关的特质则显示出轻微的保护作用。
这对日常生活意味着什么
对普通读者而言,关键的信息是:食物成瘾并非仅仅关乎意志力或对美味零食的喜好。在这组学生的初步样本中,更深层的情绪困扰——低自尊、处理压力的困难以及紧张的人际关系——与问题性饮食紧密交织。基于基础问卷和身体测量的早期机器学习工具,能够以令人鼓舞的准确度识别这些模式。然而,作者强调他们的样本量小、基于自我报告且仅来自单一大学,因此结果仍属初步。经过更大规模和更多样的研究,类似模型最终可能与标准临床评估并行使用,以提示那些可能需要在情绪与饮食管理方面获得支持的年轻人。
引用: Rahimnezhad, A., Mortazavi, S.T., Behdarvand, Y. et al. Machine learning prediction of food addiction in university students using demographic, anthropometric and personality traits. Sci Rep 16, 6745 (2026). https://doi.org/10.1038/s41598-026-36162-5
关键词: 食物成瘾, 大学生, 人格特征, 机器学习, 情绪性进食