Clear Sky Science · zh
将优化与机器学习相结合以估算泥质砂岩储层中的含水电阻率和含油饱和度
这对能源与环境为何重要
石油天然气公司依赖井筒内测量来判断碳氢化合物的分布及一个油气藏是否值得开发。在许多储层中,尤其是富含粘土和粉砂的那些,测量结果往往难以解释,因此工程师可能低估了实际的油气储量。本研究提出了一种新方法,通过将基于物理的优化与现代机器学习结合,从现有数据中挤出更可靠的信息,从而有可能提高采收率并减少对昂贵岩心样本的需求。
泥质岩石的问题
世界上许多碳氢化合物储层属于“泥质砂”—由砂粒、孔隙流体和导电性粘土矿物混合而成。这些粘土会扭曲用于估算孔隙中水与烃类比例的电性测量。为较干净砂层开发的经典工具和图表假定岩层结构简单且粘土含量低。在泥质砂中,这些假定失效,常使岩石看起来比实际更为含水,从而导致工程师放弃那些可能实际上含有大量油气的层段。
把稀疏测量变成可靠锚点
作者们着眼于一个关键量:含水层电阻率,它描述孔隙水的导电性。如果该值不准,之后的每一个含水饱和度估算都会偏移。他们没有依赖少量实验室测量或主观的图解法,而是把问题表述为一个优化任务:寻找一个使基于物理的泥质砂模型与井中实测电阻率最佳匹配的单一含水电阻率值。他们测试了多种搜索算法,并显示诸如Powell和Nelder–Mead之类的简单无导数方法在与来自挪威北海和埃及西部沙漠11口井的岩心与含水样本数据比较时,能够以非常小的误差恢复真实的含水电阻率。
为机器学习创建“伪岩心”测井
一旦得到这个优化的含水电阻率,同一物理模型被用来计算沿井连续的含水饱和度剖面。该剖面被视为高质量、受物理约束的标签——一种存在于每个深度点而不仅限于少数采样层段的“伪岩心”。研究人员随后将常规测井曲线(如伽马射线、中子孔隙度、密度和深部电阻率)输入多种机器学习模型。这些模型包括基于树的集成(随机森林、XGBoost、CatBoost)、支持向量机以及若干神经网络结构,其中包括能够识别随深度演化模式的循环网络LSTM。谨慎的预处理、异常值筛查和归一化有助于确保模型学习到真实的地质关系而非噪声。
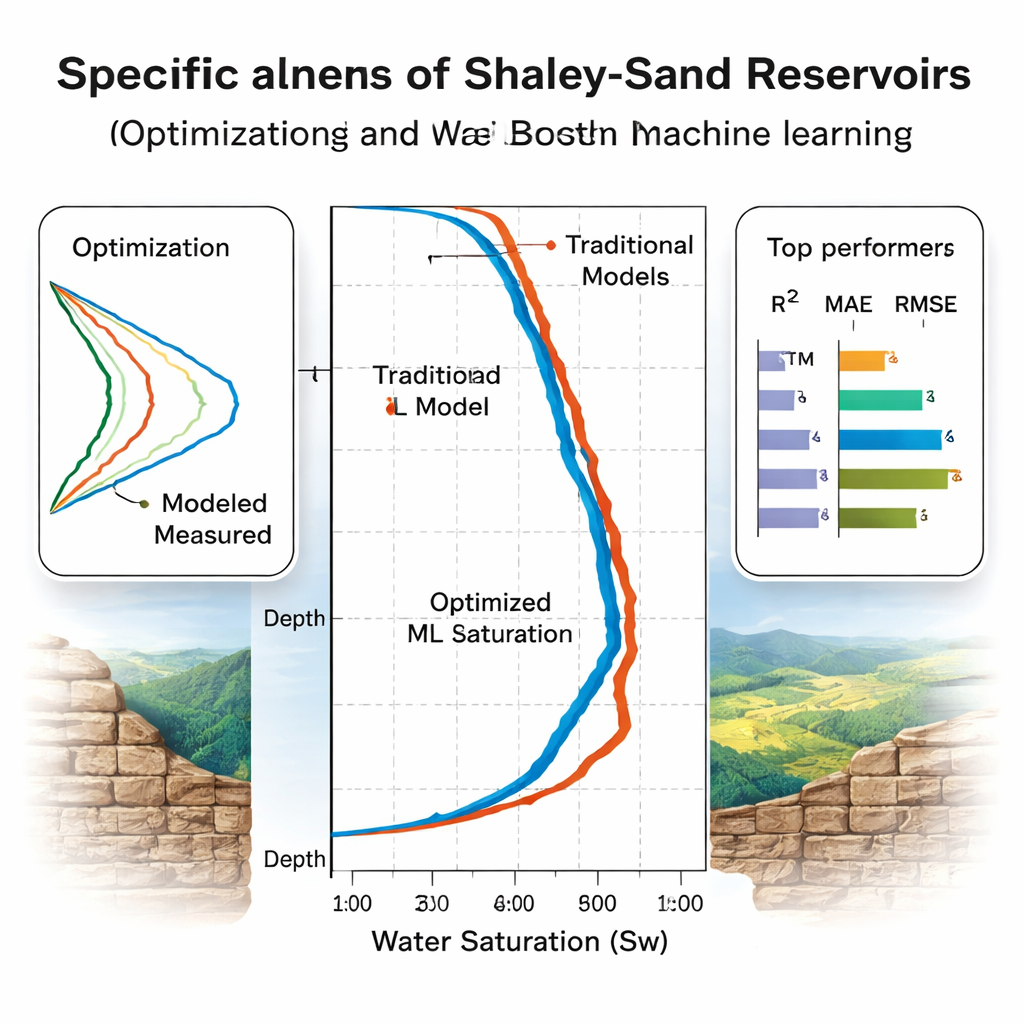
哪些模型真正具有泛化能力?
团队分两阶段评估模型。首先,他们在八口北海井上采用五折交叉验证来调参和排序,发现随机森林在常规准确度评分上似乎占优。更具说服力的测试是随后对三口“盲测”井的评估,其中包括两口来自地质上不同的埃及盆地且从未用于训练的井。在这里,一些模型表现下滑:随机森林的表现下降,表明对原始盆地存在过拟合。相比之下,梯度提升树(CatBoost和XGBoost)以及LSTM和经贝叶斯正则化的神经网络保持了较高的准确度,能解释超过93%–94%的含水饱和度变异且误差适中。使用现代可解释性工具SHAP的特征重要性分析确认,模型最依赖的输入是与物理一致的量,如电阻率、孔隙度和泥质体积。
通俗的结论
对非专业读者而言,关键思想是作者先用物理方法清理并锚定问题,然后再引入机器学习。通过让优化算法找到最佳拟合的含水电阻率并将其转化为密集且遵从物理的训练集,他们规避了稀少且昂贵的岩心数据这一常见瓶颈。结果表明,这种“先优化、后机器学习”的方法可以在未用于训练的新盆地中也提供可信的泥质储层含水与含烃比例估算。在实际层面上,这有助于运营方更可靠地勘绘产层、减少不必要的取心并改进原地油气量估算——所有这些都通过更智能地利用已有数据来实现。
引用: Hameedy, M.A.E., Mabrouk, W.M. & Metwally, A.M. Integrating optimization and machine learning for estimating water resistivity and saturation in shaley sand reservoirs. Sci Rep 16, 6342 (2026). https://doi.org/10.1038/s41598-026-36133-w
关键词: 泥质砂岩储层, 含水饱和度, 含水层电阻率, 测井学中的机器学习, 储层表征