Clear Sky Science · zh
用于高维基因组数据精确分类的混合深度学习框架
理解基因组数据洪流
现代DNA技术一次实验就能测量数以万计的基因,这有望带来更早的疾病检测和更精准的治疗。然而,这类数据量巨大、噪声多且结构复杂,即便是强大的计算模型也常常难以找到清晰、可靠的模式。本文提出了一种专门为处理这类海量基因组数据而设计的新型人工智能(AI)系统,旨在在提高预测准确性的同时解释预测结果的成因。
基因组数据为何难以使用
基因组研究通常产生的测量数远超患者或样本数量。许多测量是无关的、冗余的,或被技术噪声扭曲。传统的机器学习方法要么需要专家手动挑选可能重要的基因,要么试图全部使用,冒着过拟合的风险——即在训练数据上表现良好但在新样本上失败。深度学习已经在图像识别等领域带来变革,能自动从原始数据中学习模式。但在基因组学中它常表现为黑箱:可能给出准确答案,却很少说明原因,这在强调透明性的医学领域限制了其应用。
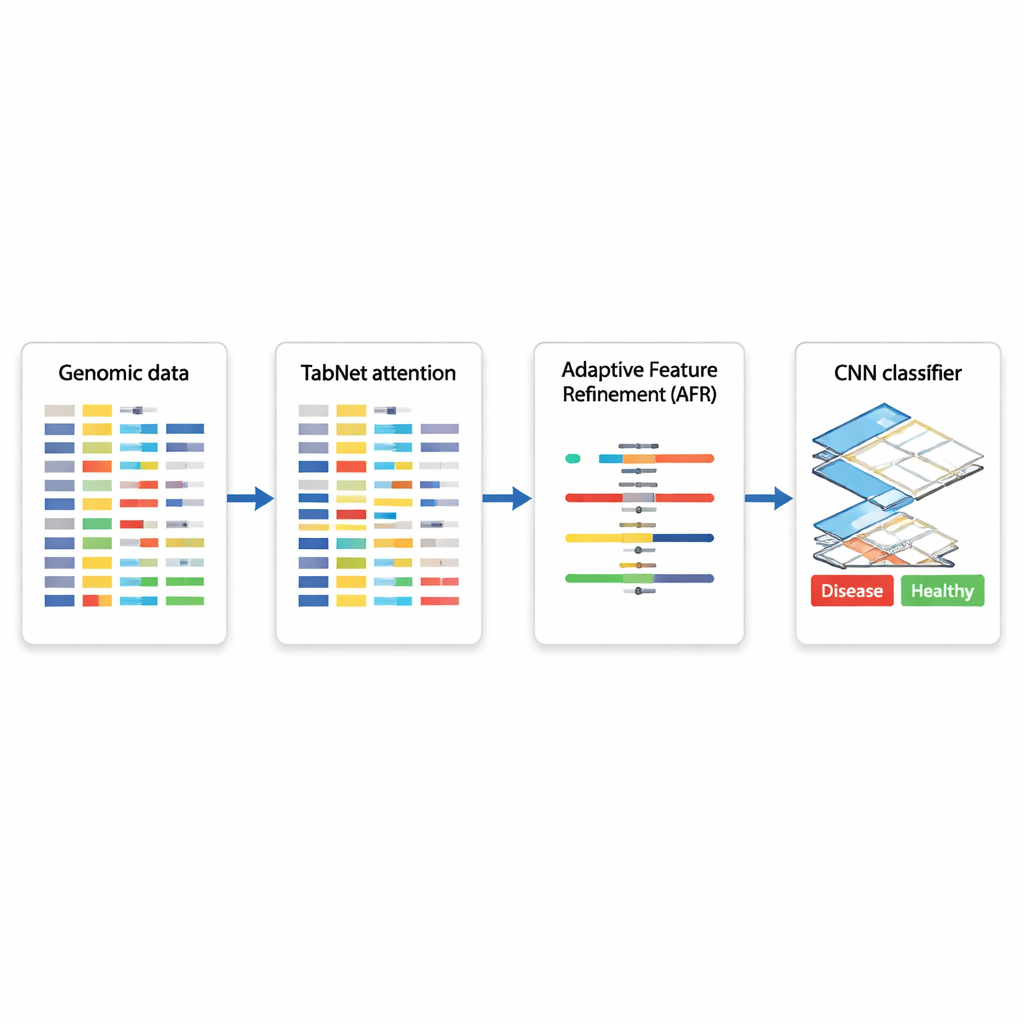
基于基因决策的混合AI蓝图
作者提出了一个由三部分专门模块串联的混合深度学习架构。首先,一个称为TabNet的组件像聚光灯一样扫描所有可用的基因组测量,学习哪些特征对给定任务最有信息量——例如区分癌变组织与非癌变组织。TabNet并不把每个基因一视同仁,而是将注意力集中在看起来最相关的稀疏子集上。接着,自适应特征精炼(AFR)层对这些被选中的信号进行重加权,强化一致且有意义的模式,同时进一步抑制噪声。最后,常用于图像分析的卷积神经网络(CNN)考察精炼后特征的局部相互作用,捕捉基因群之间可能指示特定疾病亚型或生物状态的微妙关系。
将模型付诸考验
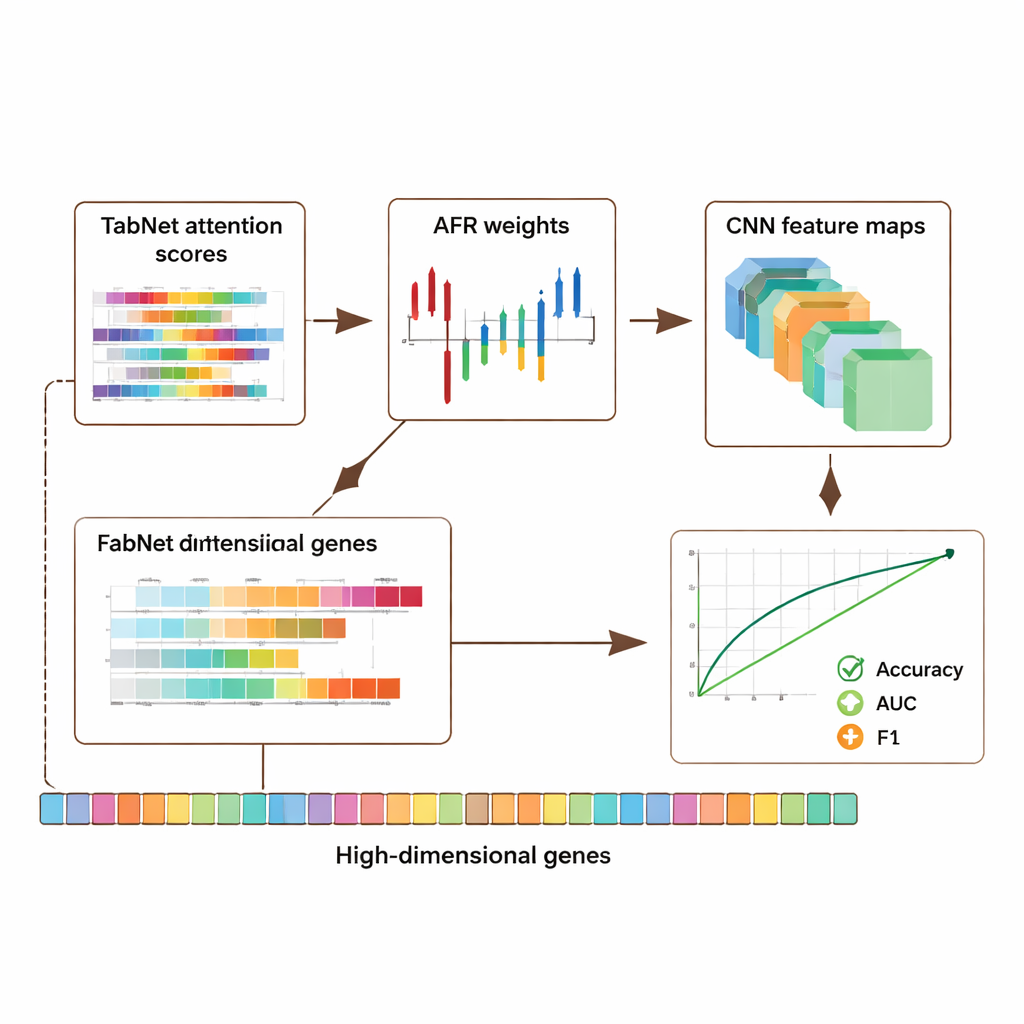
该框架在三个主要公共资源上进行了评估:来自癌症基因组图谱(TCGA)的乳腺癌数据集、来自基因表达综合数据库(GEO)的单细胞黑色素瘤数据集,以及来自ENCODE项目的表观基因组数据集。这些集合合计包含数千个样本和每个样本数万条特征,覆盖基因活性和DNA上的化学标记。在所有数据集上,这一混合模型优于若干先进方法,使分类准确率以及关键评价指标如受试者工作特征曲线下面积(AUC)和F1分数提高约5–8个百分点。更重要的是,这些提升并未以牺牲透明性为代价:模型能够输出来自TabNet的注意力图和来自CNN的激活图,突出每次预测中最具影响力的基因和区域。
在准确性、隐私与信任间取得平衡
由于基因组数据高度个人化,作者还研究了在保留有用信号的同时保护隐私的方法。他们引入了一种自适应隐私机制,对高度敏感的特征添加更多噪声,对其他特征添加较少噪声,并结合对选定输入的掩码处理。测试表明,即使在引入中等程度噪声的情况下,模型仍保持较强的准确性和判别能力,随着保护强度的提高,性能呈平滑下降。同时,可解释的注意力和激活模式常常指向已知参与癌症与免疫调控的基因,表明系统并非仅仅记忆数据,而是在捕获具有生物学意义的信号。一项消融研究——系统性地移除架构的部分组件——证实了每个模块,尤其是AFR层,对性能都有可测量的贡献。
对未来医学的意义
通俗地说,这项工作提供了一种更智能的方法,从庞大的基因组表格中筛选出与疾病相关的模式,同时指出表格中哪些条目最为重要。通过将有针对性的特征选择、慎重的特征精炼与模式识别相结合,混合模型提高了预测准确性,计算上可控,并提供了临床医生和生物学家可以解读的可视化线索。尽管仍需在更广泛、多样化的患者群体中进行更多测试,此类框架有望帮助发现新生物标志物、细化疾病亚型,并支持精准医学中的临床决策工具——将对DNA的AI分析更进一步推向现实应用。
引用: Swain, M.K., Kamila, N.K., Jena, L. et al. Hybrid deep learning framework for accurate classification of high dimensional genomic data. Sci Rep 16, 5919 (2026). https://doi.org/10.1038/s41598-026-36128-7
关键词: 基因组深度学习, 癌症生物标志物发现, 可解释的人工智能, 精准医学, 隐私保护基因组学