Clear Sky Science · zh
在移动设备上选择实时视频增强算法的神经网络框架
口袋里的更清晰视频
从与家人的视频通话到流媒体电影以及使用增强现实应用,我们现在期待手机随时随地提供清晰、锐利的视频。然而,每台移动设备都是一场平衡:它必须在不耗尽电池或拖慢速度的前提下提升图像质量。本文探讨了一种智能决策系统,帮助手机在实时情况下自动选择“最佳”视频增强方法,在视觉质量、速度和能耗之间取得平衡。
为什么更好的视频对手机来说很难实现
现代视频增强技术可以去除噪点、提升分辨率,并增强昏暗或低对比度场景的可见性。但许多最强大的方法计算量大,这对小型处理器和有限电池来说是坏消息。移动设备必须同时权衡几个相互竞争的需求:算法运行速度、视频观感、功耗以及在低端硬件上的实现难度。在每种情况下手动在多个候选算法之间做选择既复杂又容易出错,尤其是在帧与帧之间条件不断变化时。
将人类判断与智能数学结合
作者提出了一个新的决策框架,融合了两种思想:模糊逻辑和神经网络。模糊逻辑是一种处理不精确、人类式判断的方法,例如“这个方法相当快但有点耗电”,而不是僵硬的是/否评价。神经网络则受大脑神经元连接的启发,是强大的模式识别器。在该框架中,专家们先基于四个简单标准对每种视频增强方法进行评分:处理速度、视觉质量提升、功耗和实现复杂度。这些评分并不被视为固定分数,而是作为可以表达偏好和不确定性层次的“模糊”值。
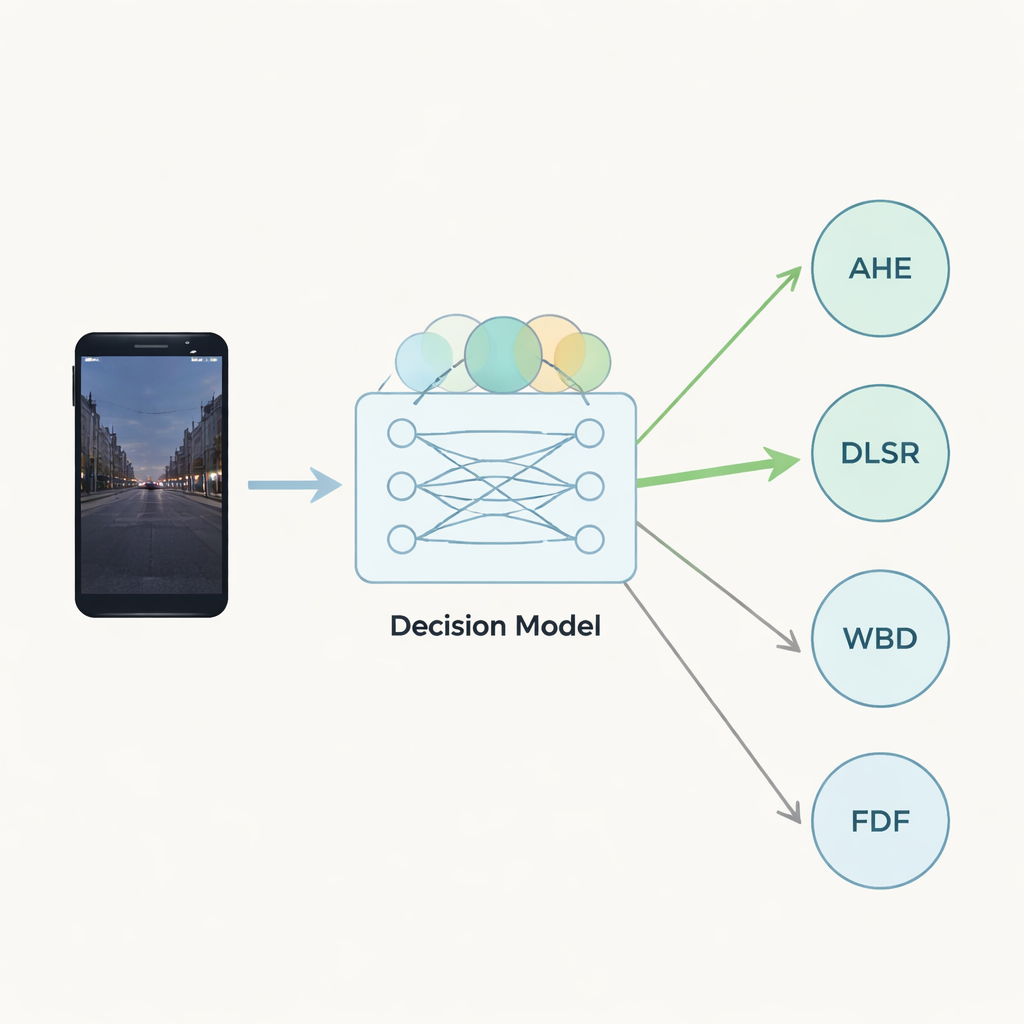
精简的分层决策引擎
为了将这些模糊评分结合起来,作者使用了一类称为Sugeno–Weber范数的数学工具。这些范数像可调节的混合器,能在捕捉相互作用的同时聚合不同的信息。来自多位专家的模糊输入首先通过一种专门的平均步骤混合到隐藏层中。第二个聚合步骤为每个候选算法产生总体得分。简单的激活函数——深度学习中常用的数学滤波器——随后将这些组合值转化为最终输出。作者比较了两种此类函数(sigmoid 与 swish),并表明它们产生的排序非常相近,这表明该决策引擎稳定且可靠。
对四种视频方法的测试
该框架被应用于四种常见的移动视频增强技术。自适应直方图均衡在光照不均时提升局部对比度;深度学习超分辨率尝试用神经网络从低分辨率输入重建细节;基于小波的去噪通过多尺度分析减少噪声;频域滤波在频率域上操作以强调或抑制特定特征。每种方法都被评分、在专家之间合并并传入模糊神经网络。系统在给定专家评估下持续将深度学习超分辨率评为首选,在速度、质量、功耗和复杂度之间取得最佳总体平衡。
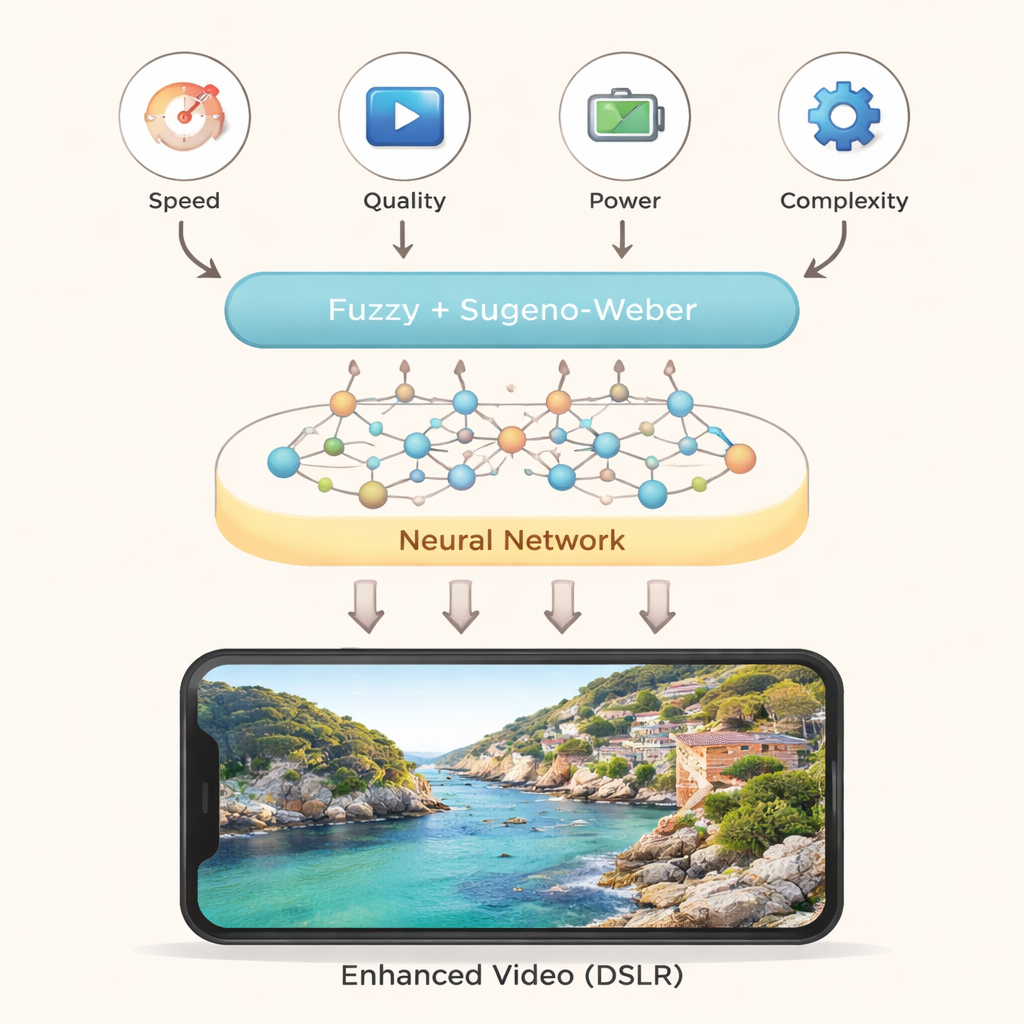
面向真实设备的稳健选择
作者还改变了关键内部参数以测试排序对调参的敏感性。尽管具体数值会略有变化,但四种方法的整体排序并未改变,这表明模型结论具有稳健性。他们随后将模糊神经方法与多种其他成熟的决策技术进行比较,发现这些方法也倾向于将深度学习超分辨率视为最佳选择。对非专业读者而言,结论很简单:通过将专家意见与一个紧凑、计算高效的神经网络谨慎融合,该框架可以帮助手机及其他小型设备在实时情况下自动选择最合适的视频增强策略——在不牺牲响应性或电池寿命的前提下,提供更清晰、更锐利的视频。
引用: Khan, M., Rahman, M.I. & Ziar, R.A. A neural network framework for selecting real-time video enhancement algorithms on mobile devices. Sci Rep 16, 5257 (2026). https://doi.org/10.1038/s41598-026-36099-9
关键词: 移动视频增强, 模糊神经网络, 深度学习超分辨率, 实时图像处理, 决策模型