Clear Sky Science · zh
基于图的自监督学习可预测非编码RNA与疾病的关联
隐匿的RNA为何影响我们的健康
我们大多数人学到的都是RNA主要用于帮助合成蛋白质。但在过去十年里,科学家发现了大量“非编码”RNA——这些分子不会翻译成蛋白,却仍然参与调控细胞功能。现在已知,其中许多分子能推动或抑制癌症及其他复杂疾病。弄清哪些非编码RNA与哪些疾病相关,可能为早期诊断或更精准的治疗方案提供新途径——但在实验室中逐一验证所有可能性几乎不现实且耗时耗力。本研究引入了一种强大的计算方法,能够在庞大的生物网络中筛选并可靠地提出最有希望的RNA—疾病连接,供实验验证。
从“垃圾”到关键的细胞角色
多年来,非编码RNA曾被视为基因活动的无关残余。我们现在知道,诸如微小RNA(microRNA)、长非编码RNA(lncRNA)和环状RNA等家族在许多关键过程里发挥协调作用,从DNA的包装到基因开关的控制以及细胞内信号传递。由于它们位于众多控制节点,即便这些RNA发生微小变化,也可能将系统推向癌症或其他疾病。临床上已经开始将它们视为潜在的生物标志物和药物靶点。挑战在于规模:存在数千种不同的RNA和数百种疾病,传统实验去逐一检验每一种可能的关联既昂贵又耗时。这正是计算预测发挥作用的地方,它能帮助缩小搜索范围。
如何解读生物网络
先前的计算方法尝试通过把大型数据表拆分为更简单的片段,或通过在已知示例上训练机器学习模型来预测RNA—疾病关联。这些方法有所帮助,但经常忽视RNA与疾病如何以网络的形式相互交织。现代“图神经网络”将RNA和疾病看作由连线相连的节点,类似社交网络,能够学习谁与谁相连的模式。然而,大多数图方法需要大量可靠的训练样本和精心设计的输入特征,这使得它们对缺失数据、噪声测量和过拟合敏感——在已知数据上表现良好,但在预测新关联时可能失败。
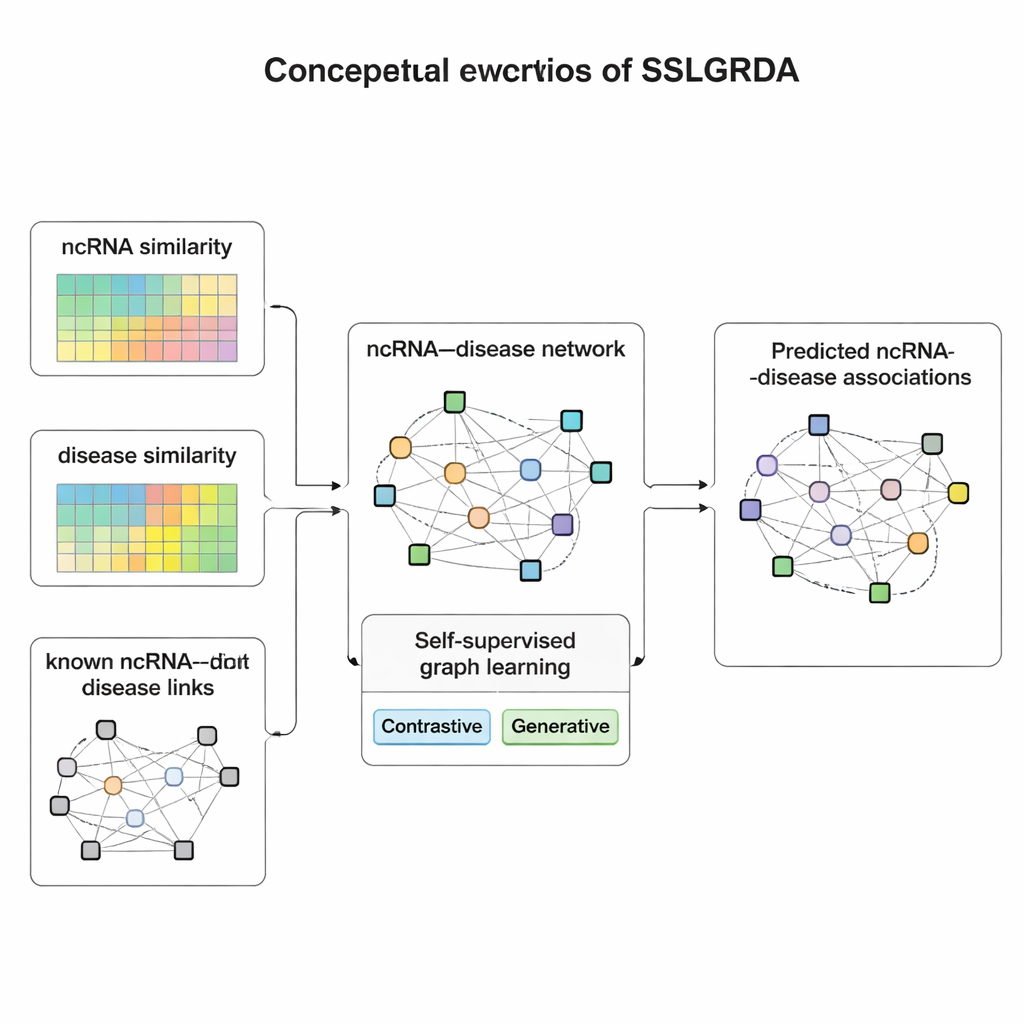
从数据中学习
作者提出了SSLGRDA,一个新的框架,使图模型能在不严重依赖标注训练数据的情况下学习有用模式。关键思想是“自监督学习”:模型不再被直接告知哪个RNA对应哪个疾病,而是基于网络的结构和属性自创练习任务。研究者构建了两类图。一类保留RNA和疾病作为不同类型的节点并由已知连接相连;另一类将它们融合为一个包含相似性信息的单一大网络——即两种RNA或两种疾病之间的相似程度,这样即便连接稀疏的条目也能获得支持性的邻居。在这些图之上,SSLGRDA采用两种自训练风格。对比策略要求模型识别同一节点的不同“视图”(例如其连接与其属性)应产生相似的内部表示,同时将不相关的节点明确区分开来。生成式策略有意隐藏部分输入特征并挑战模型去重建这些特征,促使模型捕捉更深层次的结构而非死记硬背噪声。
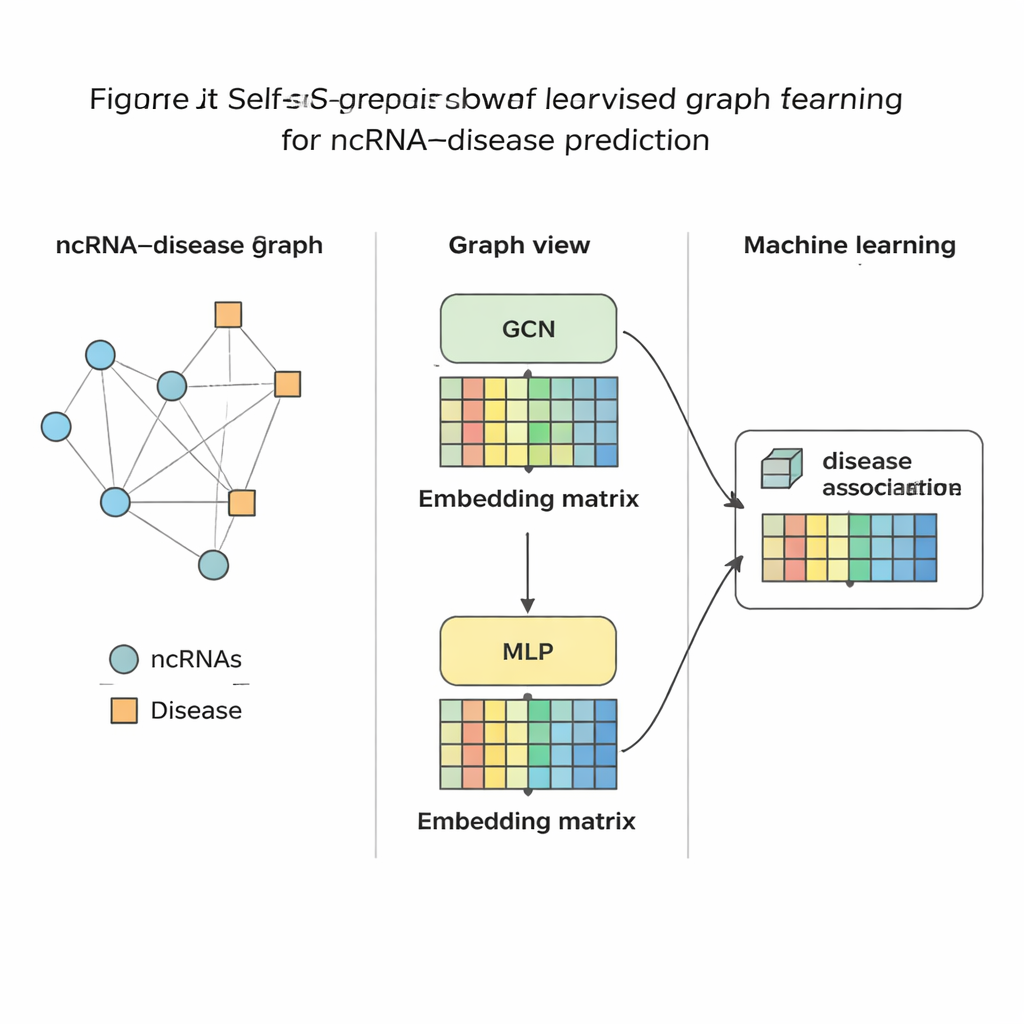
方法的实测评估
在将每个RNA和疾病提炼为紧凑的数值指纹后,研究人员训练了一个标准的机器学习分类器来判断它们之间是否可能存在关联。作者在涵盖三类主要RNA类型和数百种疾病的九个不同数据集上评估了该方法。总体而言,他们在混合(同质)图上采用的对比自监督变体表现最佳,优于多种现有工具,包括强有力的图基线方法。该方法不仅在全局测试中获得更高准确率,而且在以单一RNA或单一疾病为中心检索时,也能将正确的配对排在靠前位置——这对现实应用至关重要,因为生物学家常从单一癌症出发,询问应研究哪些RNA。他们还展示了相同思想可以良好转移到其他生物医学网络,例如微生物与疾病或药物之间的连接网络。
从预测到潜在疗法
为证明其实用价值,团队将SSLGRDA应用于寻找参与乳腺癌、结肠癌及其他若干疾病的新非编码RNA。许多排名靠前的建议随后在独立数据库或科学报告中得到证实,支持模型识别生物学上有意义模式的能力。对非专业读者而言,结论是:这项工作提供了一种更聪明的方式,从日益增长的复杂生物数据中挖掘出隐藏的疾病线索。通过自动学习RNA与疾病如何聚类和相互作用,像SSLGRDA这样的自监督图方法可以引导实验室研究者走向最有希望的目标,可能加速从原始数据到更好诊断和治疗的路径。
引用: Wu, Q., Tang, S. Self-supervised learning on graphs predicts non-coding RNA and disease associations. Sci Rep 16, 5231 (2026). https://doi.org/10.1038/s41598-026-36030-2
关键词: 非编码RNA, 疾病关联, 图神经网络, 自监督学习, 计算生物学