Clear Sky Science · zh
用于解释性的多参数优化信念规则库以预测学生表现
为何预测成绩与每个人相关
成绩单看起来很简单,但塑造学生成绩的力量远非如此。学校越来越多地依赖计算模型来及早发现有困难的学生并指导支持。然而,许多这些模型是“黑箱”的:它们可能很准确,但连教师和家长也无法看到预测的依据。本文提出了一种新的方法,旨在在高准确性与易于理解之间取得平衡,以便教育工作者能够信任并据此采取行动。
更聪明地解读信号
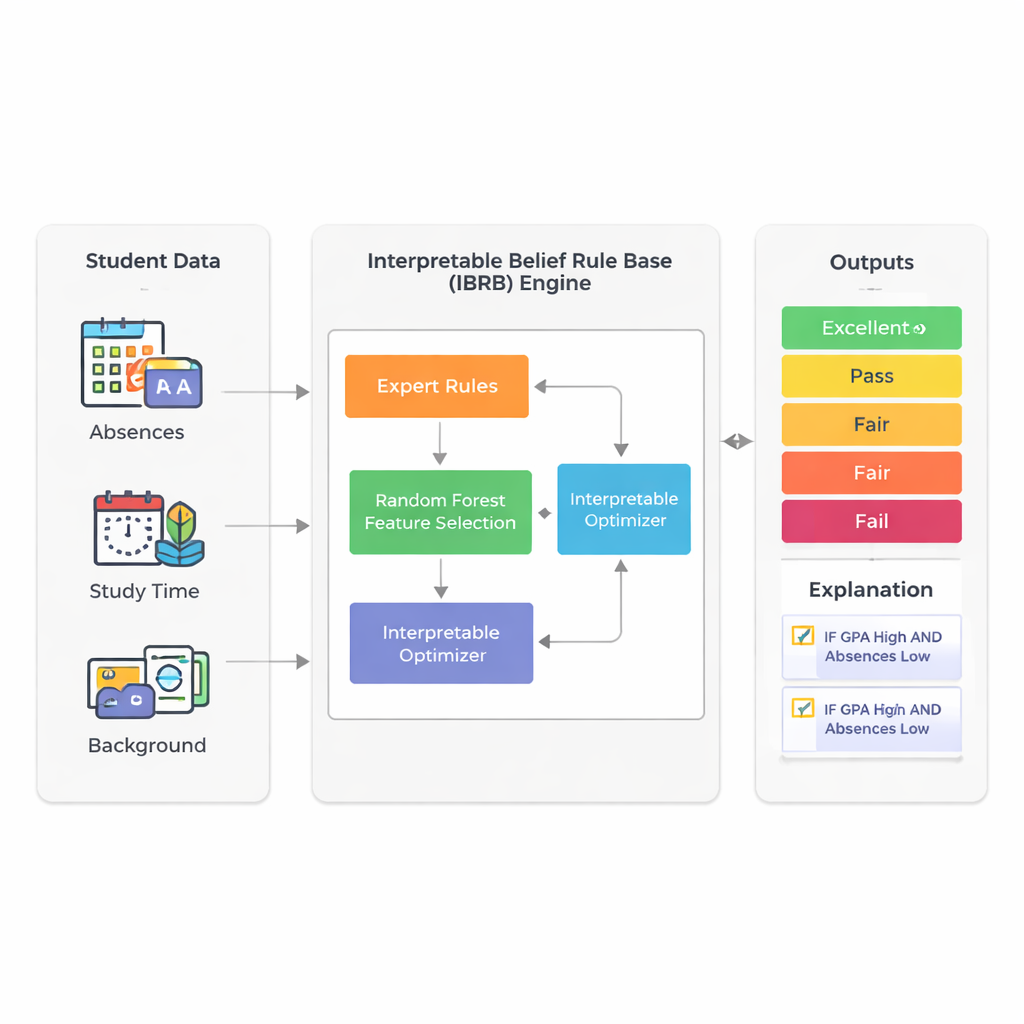
该研究聚焦于使用学校已有的信息来预测学生最终的表现:平均绩点(GPA)、缺勤次数、学习时间、背景以及家庭和活动因素。研究者不是依赖不透明的深度学习系统,而是基于一种称为信念规则库的方法。在这种框架下,专家撰写的规则很像教师可能说的话:“如果 GPA 很高且缺勤很少,那么该学生很可能表现良好。”每条规则都对可能的结果(例如优秀、良好、通过、一般或不及格)赋予一定的信念度。这使得推理过程可见,并且原则上可向非专家解释。
在不丢失含义的情况下驯服复杂性
基于规则的系统面临的一个主要挑战是:当包含许多学生属性时,规则数量会失控——每增加一个因素都会成倍扩大可能的规则数。为避免这种“规则爆炸”,研究者首先使用随机森林(一种广泛使用的决策树集成方法)来衡量哪些特征对预测表现最重要。在他们来自公开来源、包含2392名学生的真实数据集中,GPA 和缺勤次数约占模型预测能力的73%。通过有意仅保留这两个输入,最终模型保持紧凑且更容易解释,同时仍反映了大部分学生表现的变异。
构建人们能理解的规则
新模型(称为 IBRB-m)的核心是精心构建的25条规则,结合了不同水平的 GPA 与缺勤情况,并为五个表现类别赋予信念度。作者形式化了“可解释性”对这种模型意味着什么。他们的要求包括:每个参考级别(例如“低 GPA”)必须覆盖一个清晰且相互区分的范围;规则库必须覆盖所有现实的输入组合;规则权重和属性权重等参数应具有通俗易懂的含义;系统的内部计算必须以透明且数学一致的方式转换信息。在这些传统条件之上,他们还加入了教育领域的特定准则,强制模型的预测遵循常识性的形式——例如,避免出现学生同时被判断为既极有可能优秀又极有可能不及格的荒谬情况。
让数据微调专家判断
人工专家并非总是意见一致,他们的初始规则也可能不够精确。为了在不将模型变为黑箱的前提下细化这些规则,作者设计了一种改进的优化算法,在遵守严格可解释性约束的同时搜索更好的参数值。该算法不仅调整规则权重和信念度,还调整定义诸如优秀或通过等类别的分界点。它将所有更改限制在专家批准的范围内,并强制在各个成绩之间保持合理、平滑的信念模式。实际上,计算机在把专家系统“轻推”到更高准确度的同时,不被允许发明会令有知识的教师困惑的新规则。
实际效果如何?
在 Kaggle 学生表现数据集上的测试表明,IBRB-m 模型在超过99%的情况下正确预测了最终的表现等级,优于早期的信念规则系统以及常见的机器学习工具,如神经网络、随机森林和 k 近邻。与此同样重要的是,经优化后的规则在用简单距离度量衡量时仍接近原始专家评估,这意味着每个预测背后的推理仍可以追溯并被证明是合理的。跨多次数据划分的交叉验证显示,该模型的性能稳定,并非偶然的划分幸运所致。
这对课堂意味着什么
对非专业读者而言,主要结论是可以同时拥有既强大又可理解的学生预测工具。模型不再发布神秘的风险分数,而是可以突出具体模式,例如“中等 GPA 但频繁缺勤”,并展示这些如何导致给出一般或不及格的预测。教师和辅导员随后可以据此采取有针对性的行动——例如出勤支持或学习技能辅导——同时自信地向学生和家长解释模型得出结论的原因。作者认为,如果数据驱动的系统要在促进公平和有效教育方面发挥值得信赖的作用,这种准确性与透明性的结合是必不可少的。
引用: Li, J., Zhou, W., Jiang, S. et al. The multi-parameter optimized belief rule base for predicting student performance with interpretability. Sci Rep 16, 5772 (2026). https://doi.org/10.1038/s41598-026-35950-3
关键词: 学生表现预测, 可解释的人工智能, 信念规则库, 教育数据挖掘, 可解释的机器学习