Clear Sky Science · zh
HEViTPose:通过级联分组空间压缩注意力实现高精度且高效的二维人体姿态估计
教会计算机“读懂”肢体语言
从健身应用到驾驶辅助系统,许多技术如今都依赖计算机理解人如何移动。这种技能称为人体姿态估计,指的是在图像或视频中定位身体关节的位置——例如肩膀、膝盖和脚踝。挑战在于既要达到高精度,又要足够快速以在日常硬件上实现实时运行。本文提出了 HEViTPose,一种旨在在保持高精度的同时使用比许多现有系统更少计算资源的新方法。
为什么在图像中找到关节如此困难
乍看之下,定位身体关节似乎很简单:只要找到手臂和腿即可。但实际上,人会以不同大小出现、姿势各异、场景拥挤,且常常被家具或车辆等物体部分遮挡。现代姿态估计系统通常通过为每个关节生成详细的“热图”来处理这些问题,热图中亮点标记可能的位置。热图非常精确但计算代价高昂。传统系统主要依赖卷积神经网络,擅长捕捉局部模式,但为了获得跨全身的长程关系必须加深和增大模型。近年来基于变换器的模型在捕捉长程关联方面表现出色,然而它们通常需要大量数据和高计算量,使得在实时或小型设备上使用变得困难。
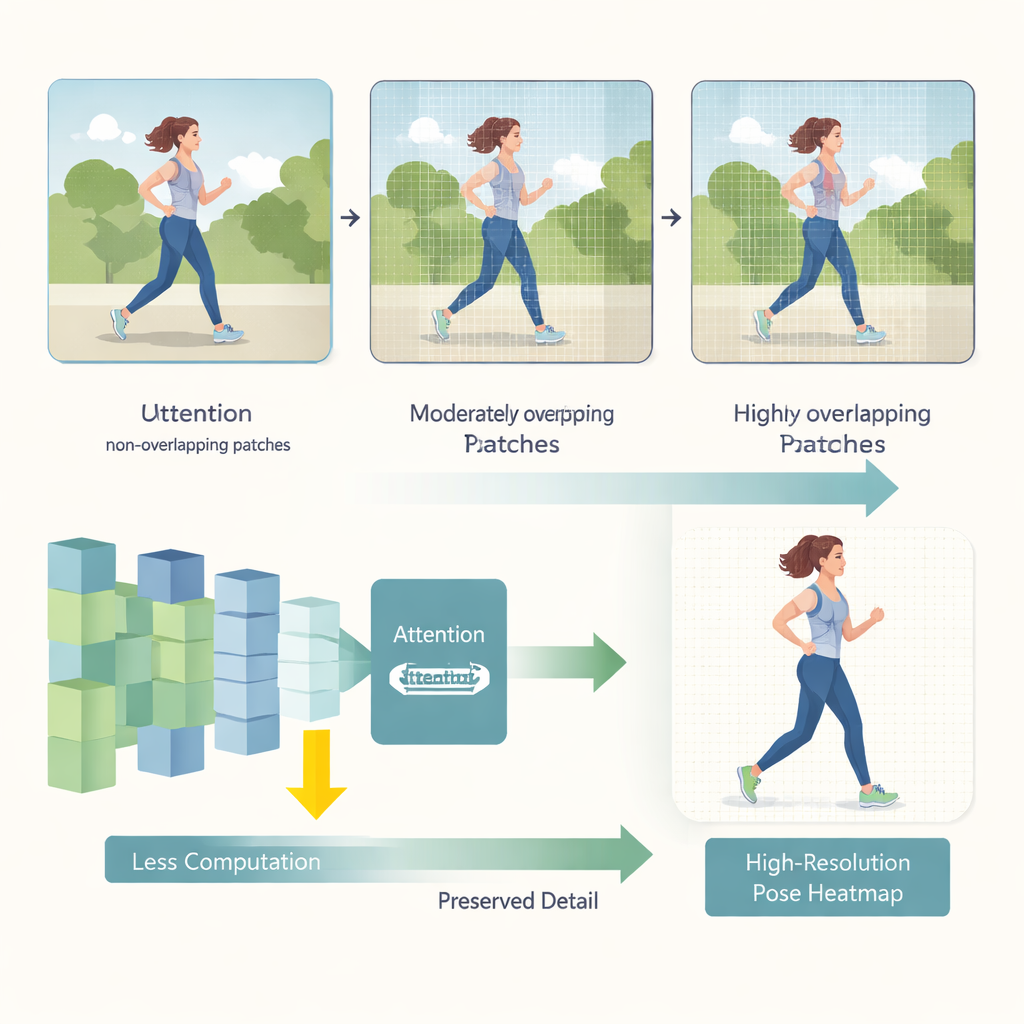
重叠视窗带来更平滑的视觉感知
HEViTPose 首先从重新思考图像如何被分块以供分析入手。早期的变换器模型通常将图像切成不重叠的小块,这会破坏相邻区域之间的视觉连续性——例如把人的手臂切在补丁边缘。HEViTPose 基于一种称为重叠补丁嵌入的思想,并提出了一个更清晰、可调的度量:补丁嵌入重叠宽度(Patch Embedding Overlap Width,PEOW)。PEOW 简单地统计相邻补丁在边界处共享的像素数。通过系统地改变这个重叠量,作者展示了适度的重叠可以让网络更好地“感知”从一个补丁到下一个补丁的颜色和形状的平滑变化。更丰富的局部连续性带来了更准确的关节定位,同时不会显著增加模型大小或计算量。
更聪明的注意力,付出更少的计算
第二个关键创新是一个名为级联分组空间压缩多头注意力(Cascaded Group Spatial Reduction Multi-Head Attention,CGSR-MHA)的新注意力模块。注意力机制告诉网络图像的哪些部分应当影响每个预测,但随着图像变大,注意力通常会带来很差的扩展性。CGSR-MHA 从三方面应对这一问题。首先,它将特征划分为若干组,使得每组只处理信息的一部分而不是一次处理全部。第二,它在每组内部先压缩空间分辨率再计算注意力,从而大幅减少操作数量。第三,它使用若干小注意力头而不是少数大型头,保留模型可关注信息多样性的同时降低成本。合理选择分组数、压缩比例和头数可以在速度与精度之间取得平衡。
轻量模型仍能在顶级竞赛中竞争
为了测试 HEViTPose,作者在两个广泛使用的基准上进行了评估:用于日常人体活动的 MPII 数据集以及包含多种场景人物的更大 COCO 数据集。在多个模型规模上,HEViTPose 在精度上与领先的姿态估计系统持平或接近,同时使用更少的参数和更低的计算量。例如,一个版本在精度上可与流行的高分辨率网络(HRNet)相匹配,但学习参数数量减少超过 60%,计算量降低超过 40%。与另一种将卷积与变换器混合的现代混合模型相比,HEViTPose 在性能相近的情况下在图形处理器上运行速度约快 2.6 倍。这些节省直接转化为更平滑的实时表现和更低的硬件需求。
这对日常应用意味着什么
简而言之,HEViTPose 表明在教计算机“读懂”人体肢体语言时,我们不必在精度与效率之间做出妥协。通过谨慎地重叠它分析的图像块,并重新设计网络内部的注意力计算方式,系统能够在保持紧凑与快速的同时精确定位关节。这使其在运动追踪、视频监控、人机交互和车内监测等需要速度与能耗兼顾的现实场景中具有吸引力。HEViTPose 背后的思想——更智能的重叠与高效的注意力——也可推广到类似任务,如动物姿态跟踪或面部关键点检测,可能为许多设备带来更敏锐的“数字之眼”,而无需超级计算机级别的硬件。
引用: Wu, C., Chen, Z., Ying, B. et al. HEViTPose: towards high-accuracy and efficient 2D human pose estimation with cascaded group spatial reduction attention. Sci Rep 16, 5637 (2026). https://doi.org/10.1038/s41598-026-35859-x
关键词: 人体姿态估计, 计算机视觉, 视觉变换器, 高效深度学习, 注意力机制