Clear Sky Science · zh
一种结合 Mel 频谱和连续小波变换特征的混合 CNN 与强化学习说话人识别框架
为什么你的声音可以成为数字钥匙
想象一下仅用你的声音就能解锁银行账户、前门或手机。要做到安全,计算机必须能够可靠地区分不同的人——即使有背景噪声、情绪变化或麦克风质量不佳。本文探索了一种新的方法,通过将现代深度学习技术与来源于机器人学的试错式学习相结合,教机器识别说话者的身份,而不仅仅是他们所说的内容。
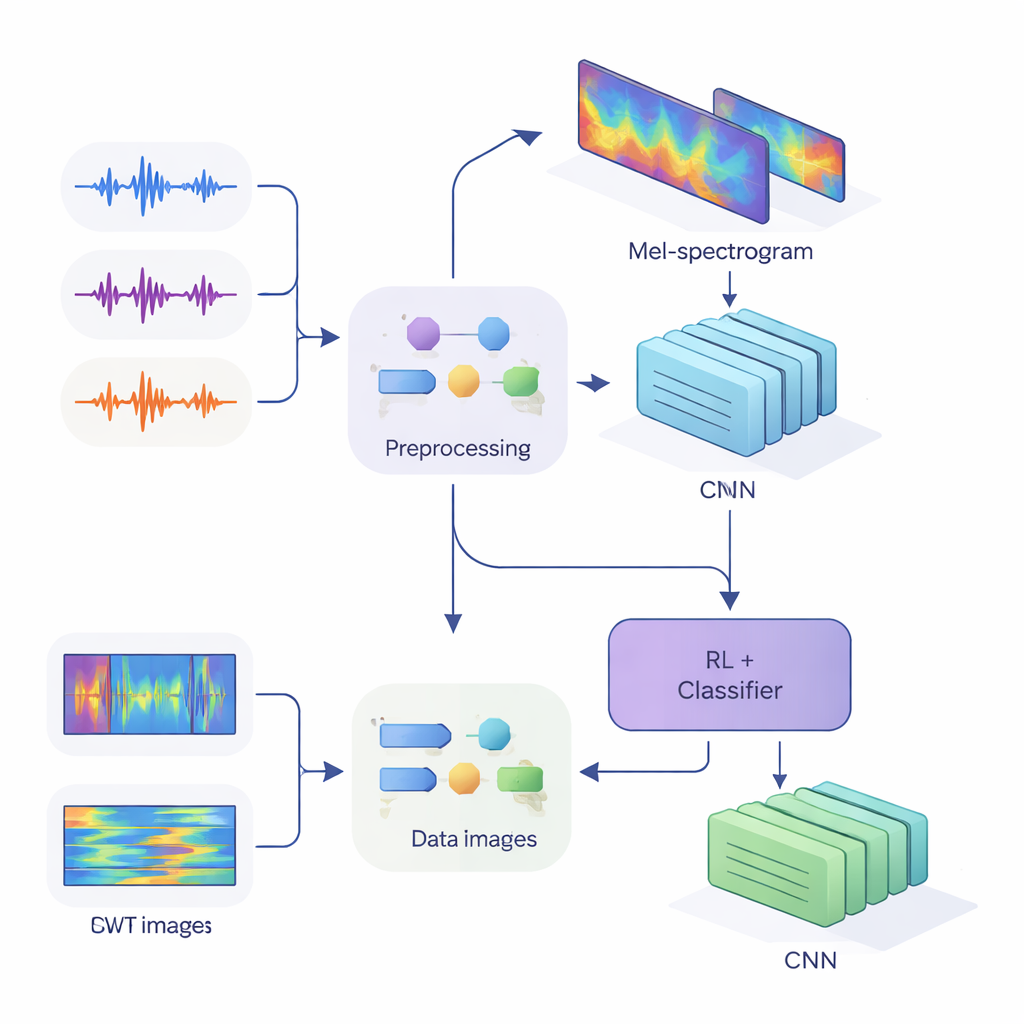
从声波到声音指纹
每个人的声音都携带由声道形状、声带振动方式和说话风格决定的细微线索。研究人员首先问:录音中哪些可测量的属性在不同说话者之间确实存在差异?他们使用 LibriSpeech 数据集中 40 名英语说话者的 2,703 段音频,分析了 22 项简单的声学特征,如响度变化、不同频段的能量、节奏,以及一种称为熵的指标,用以捕捉声音的复杂性或不可预测性。统计检验显示,这 22 项特征中有 21 项携带明显的说话人特异信息,其中熵和高频能量表现得尤为区分性强。换言之,一个人的“声音指纹”分布在声音的许多方面,而不仅仅是基频或音量。
两种将声音变为图像的方法
为了把这些线索输送到现代神经网络,团队将一维音频转换为二维图像,以捕捉能量随时间和频率的变化。第一种方法使用 Mel 频谱图,这种表示模拟了人耳对频率的分组,是语音技术中的标准做法。第二种方法使用连续小波变换,这是一种在时间上既能放大短促突发声,又能关注较长元音的更灵活手段。在对音频进行仔细清洗——去除静音、标准化音量,并加入小幅失真如噪声和音高偏移以提升鲁棒性——之后,他们生成了尺寸为 80×313 的 Mel “图像”和 128×128 的小波“图像”,以供卷积神经网络(CNN)处理。
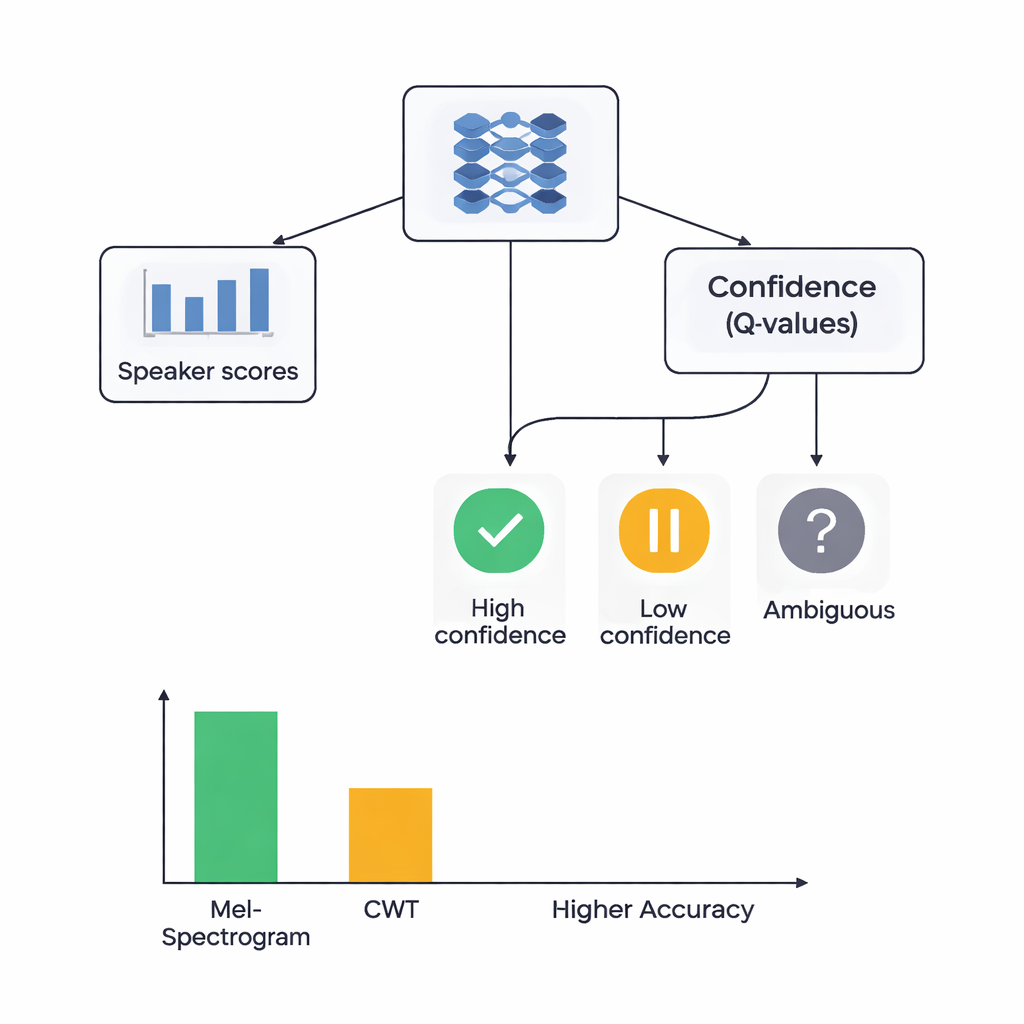
教网络去听并学会怀疑
研究的核心是一个将两种学习风格结合的混合架构。首先,CNN 扫描 Mel 或小波图像以提取倾向于属于特定说话者的模式,类似于图像识别网络学会识别眼睛或边缘。在基于 Mel 的系统中,作者加入了自注意力模块,使网络能够关注最具信息量的时间片段。在这些特征提取器之上,他们放置了一个强化学习(RL)组件,用于学习系统在每次判断中应有的置信度。RL 部分并不总是做出硬性的选择,而是为诸如“把这次判断视为高置信度”“视为低置信度”或“标记为模糊”等动作分配价值。经过多轮训练,当高置信度判断正确时该组件会获得奖励,从而推动网络做出更好校准的决策。
这种混合系统的表现如何?
研究者比较了四种模型:带 RL 的 Mel 模型、无 RL 的 Mel 模型、带 RL 的小波模型和无 RL 的小波模型。所有模型都采用谨慎的五折交叉验证测试,这意味着每段音频在不同轮次中既用于训练也用于测试。Mel+RL 系统表现最佳,识别说话人的准确率约为 88%,并且根据一项常用的判别力衡量指标显示出近乎完美的说话人分离。小波+RL 系统的准确率约为 78%。关键是,加入 RL 组件使两种特征类型的性能均提高了约 3 个百分点,并使不同数据划分间的结果更为一致。包含 RL 时,更多的说话人类别达成了高质量的识别,这表明置信度感知决策尤其有助于处理那些容易混淆的发音。
这对日常语音安全意味着什么
对非专业读者来说,关键结论是:可靠的基于语音的身份验证需要既有丰富的声音表征,也需要机器具备适当的怀疑意识。该研究表明,受耳朵启发的 Mel 频谱图,配合注意力机制和能够说“我不确定”的强化学习器,在区分说话者任务上优于更为“奇特”的小波图像。虽然该研究使用的数据集相对较小且较干净,尚未针对嘈杂的现实环境进行调优,但它证明在深度神经网络之上加入一个置信度感知层,能使语音认证更准确且更值得信赖——这是将我们的声音作为安全数字钥匙的重要一步。
引用: Heir, F.M., Najafzadeh, H. & Erfani, S. A hybrid CNN and reinforcement learning framework for speaker identification using Mel-Spectrogram and continuous wavelet transform features. Sci Rep 16, 5954 (2026). https://doi.org/10.1038/s41598-026-35858-y
关键词: 说话人识别, 语音生物识别, 深度学习, 强化学习, Mel 频谱图