Clear Sky Science · zh
用于营销分析的量子核方法及其收敛理论与分离界
为何更智能的客户预测很重要
公司越来越依赖数据来决定针对哪些客户推送优惠、提供支持或开展保留活动。但随着数据变得日益复杂,传统工具在识别细微模式时可能力不从心,尤其当每一个错过的高价值客户都代价高昂时。本文探讨了新兴的量子计算机——遵循量子物理规则的机器——是否能为类似营销的问题提升预测能力,并在研究中明确考虑了当下并不完美的“有噪声”硬件。

从客户记录到量子电路
作者们关注一个实用任务,他们称之为消费者分类:预测哪些用户会参与或采用某项数字服务。每个用户由一小组数值特征描述,如人口统计信息和在平台上的行为。与其将这些数据直接输入标准算法,他们先将其编码到几个量子比特(qubit)的量子态中,使用紧凑的量子电路。该电路作为一种特征变换,将数据重塑为可能更易于分成两类——“可能参与”和“不太可能参与”的形式。在这种量子变换之上,他们采用一种知名的分类方法——支持向量机的量子化版本,称为量子核SVM(Q-SVM)。
在现实条件下测试量子方案
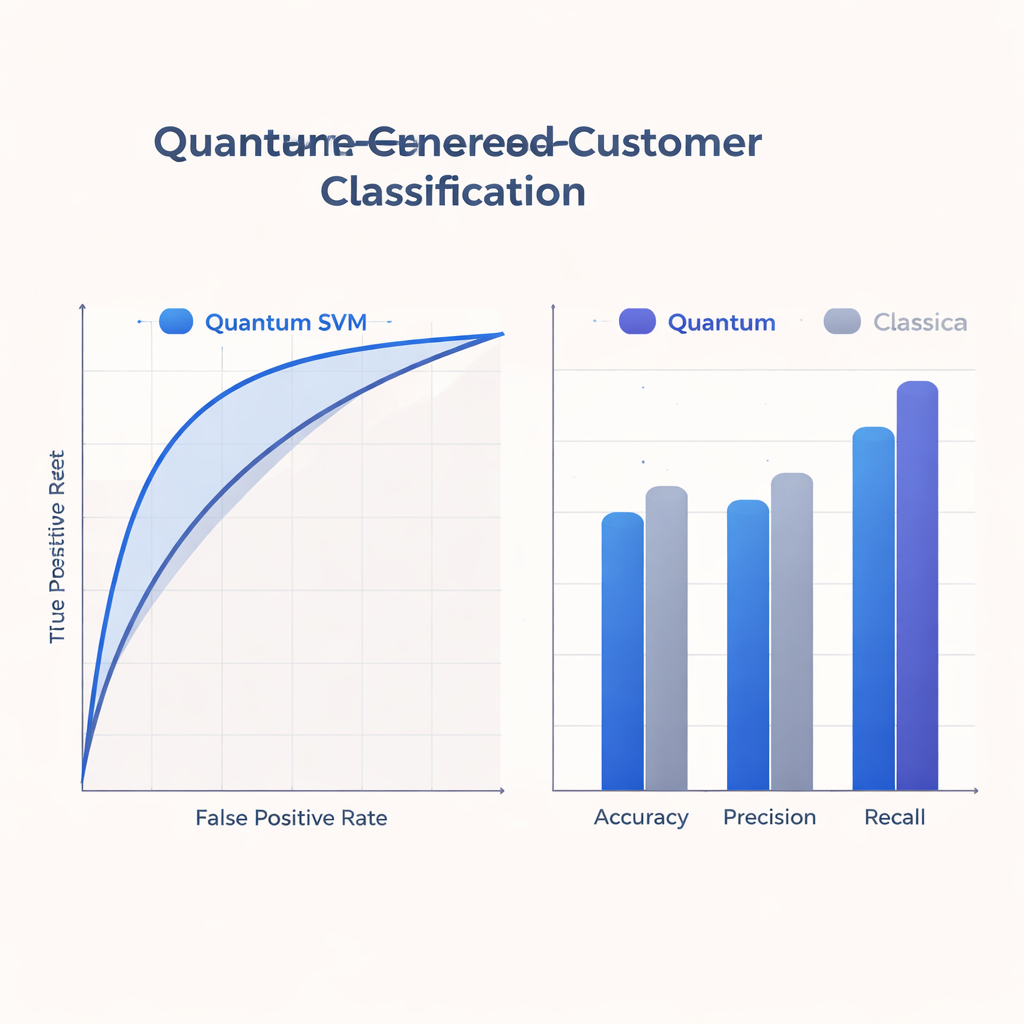
由于当今的量子设备规模小且易出错,研究坚持使用与近期硬件能力相匹配的浅电路。团队在一个真实的匿名数据集上训练和评估他们的Q-SVM,数据包含约500个训练样本和125个测试样本,每位用户有八个特征,同时模拟理想和有噪声的量子行为。他们将量子方法与在标准计算机上使用流行核技巧的强大经典基线进行比较。在准确率、精确率、召回率以及ROC曲线下面积(概括了在捕获正例和避免误报之间的权衡)等指标上,Q-SVM呈现出有竞争力或更好的表现,特别是在召回率方面表现强劲:它正确识别出真实感兴趣用户的比例高于经典模型。
幕后理论保证
除了原始性能外,论文还探讨了一个更深层的问题:何时可以预期量子方法会有所帮助?作者给出三项主要理论结果。首先,他们证明如果学习问题满足某些平滑性条件且量子电路保持浅层,量子核的训练过程应能在合理步数内可靠收敛。第二,他们提供了分离界,表明在特定假设下,他们的量子特征提取能相比经典变换扩大两类客户之间的差距——本质上使问题更易于解决。第三,他们分析了近似方法如何显著降低处理大规模量子衍生特征空间的成本,从而使该方法在计算上仍然可行。
这对营销人员可能意味着什么
对于营销和客户分析团队来说,最具体的收益在于量子模型如何在错过机会与浪费推广之间取得平衡。Q-SVM 较高的召回率意味着它不太可能忽略那些会对优惠做出积极响应的用户,这在保留或主动服务活动中是一项关键优势。与此同时,它的精确率和整体准确度仍处于与强大经典基线可比的范围内,并由稳健的ROC曲线支持。由于该方法在一系列决策阈值下表现良好,团队可以在不需要每次重新训练模型的情况下调整攻守策略——倾向于召回或精确率。
有前景的开端,而非(尚未到来的)量子革命
作者强调,他们的发现是早期步骤,而非量子全面优越的证据。结果来自对单一数据集的模拟,而非大规模硬件运行或多市场验证。他们的数学保证也依赖于在有噪声设备上可能不能完全成立的理想化假设。尽管如此,该工作表明精心设计的量子核在现实的消费者任务上已能与良好的经典方法匹敌或略有超越,同时为随着量子硬件规模扩大而获得更大优势指明了路径。对读者而言,结论是量子机器学习正从抽象承诺向可能在现实商业环境中提升客户预测准确性与灵活性的工具迈进。
引用: Sáez Ortuño, L., Forgas Coll, S. & Ferrara, M. Quantum kernel methods for marketing analytics with convergence theory and separation bounds. Sci Rep 16, 6645 (2026). https://doi.org/10.1038/s41598-026-35793-y
关键词: 量子机器学习, 营销分析, 客户分类, 支持向量机, 量子核