Clear Sky Science · zh
通过视觉增强与语义耦合进行红外与可见光图像融合
昼夜相机带来的更清晰视野
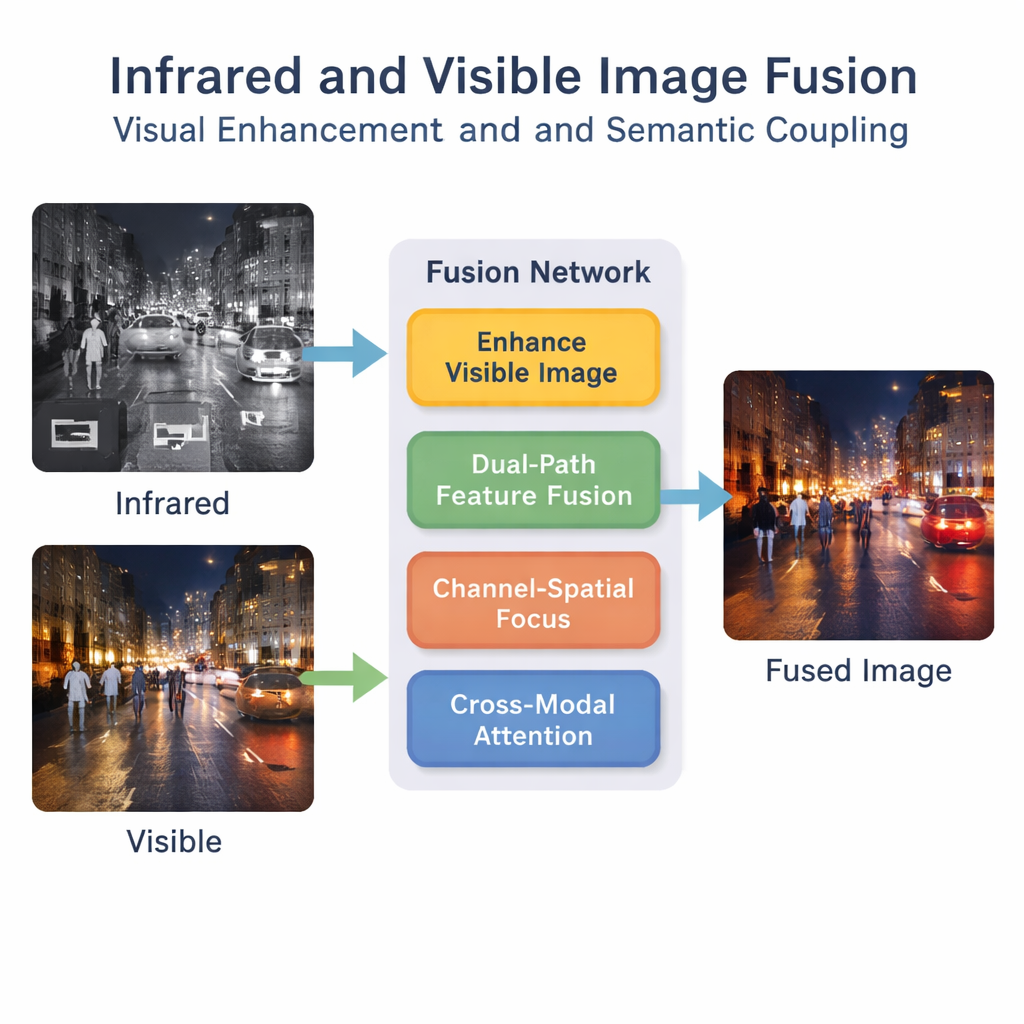
现代汽车、无人机和安防系统通常配备两类“眼睛”:能看见颜色与纹理的普通相机,以及能感知热量的红外相机。每种相机各有长短,将它们合成到一幅清晰的图像中出乎意料地困难。本文提出了一种新的融合方法,能把这两种视角合成一幅不仅更易于观察、而且更利于计算机理解的图像。
双眼为何优于单眼
可见光相机能捕捉到清晰细节,例如道路标线、建筑边缘和服装纹理,但在夜间、雾中或目标与背景相似时表现欠佳。红外相机则相反:它们能在黑暗中突出显示人体和车辆等热源,但画面通常模糊且缺乏细节。将这两种视图融合为一种“各取所长”的图像,可在从驾驶辅助系统中的行人检测到监控与搜救等任务中发挥作用。然而,许多现有的融合方法仅关注表面特征——红外的亮斑和可见光的纹理——而忽视了对智能系统更重要的、更深层的场景语义。
更智能的图像融合方式
作者提出了一个将融合视为超越简单叠加的深度学习框架。首先,一个特殊的增强步骤会对可见光图像进行亮度与色调平衡,特别是在弱光场景中,以免在融合开始前就丢失有价值的细节。随后,一个双路径网络并行处理红外与可见输入。一条路径专注于边缘与纹理等局部模式,另一条则关注更广泛的场景语境。通过结合这两条路径,系统生成对图像内容更丰富的内部描述。
教会网络该关注什么
仅仅提取大量特征还不够;网络必须学会哪些特征更重要。一个“通道—空间”模块帮助模型突出关键区域与信息类型,例如行人或明亮的车灯,同时弱化无关的背景杂讯。其上层的双模态交互注意力机制则鼓励红外与可见流之间进行信息交流。该机制学习热信号与视觉纹理如何在场景中对应,捕捉诸如“红外图像中的这个亮斑对应于可见图像中的那个人”之类的高层语义。这种语义耦合使融合图像在逻辑上保持一致,而不仅仅是视觉上的混合。

方法的实测验证
为了检验融合图像不仅好看而且真实可信,作者加入了一个类似生成对抗网络中判别器的网络。这个额外网络学习区分真实的可见光图像与融合图像,推动融合过程产出对人类和机器都更自然的结果。该方法在三个具有挑战性的红外—可见图像对数据集中进行了训练与测试,涵盖了白天与夜间道路以及军用场景。在一系列标准质量度量上,新方法总体优于十种现有的融合技术,生成的图像具有更清晰的边缘、更好的对比度和更具信息性的内容。
为更安全的机器提供更好的图像
除了视觉质量,作者还提出了一个实用问题:这些融合图像能否帮助计算机做出更好的决策?使用一种流行的目标检测系统进行行人检测,他们展示了与单一传感器图像和早期融合方法相比,融合图像提高了检测精度。通俗地说,该技术在艰难条件下(如夜间驾驶)生成了更易于人类与算法解读的图像。虽然该系统在资源受限设备上实时运行还需调优,但它为自动驾驶、监控及其他在关键时刻需清晰视觉的技术朝着更安全、更可靠的方向迈出了一步。
引用: Yang, Y., Li, Y., Li, J. et al. Infrared and visible image fusion via visual enhancement and semantic coupling. Sci Rep 16, 5666 (2026). https://doi.org/10.1038/s41598-026-35763-4
关键词: 图像融合, 红外成像, 弱光视觉, 深度学习, 目标检测