Clear Sky Science · zh
声学哨兵:使用精细与粗粒度声学特征表示进行战术监视的脚步声分层分类
倾听隐藏的脚步声
想象仅凭脚步声就能在没有任何摄像头的情况下,侦测有人穿过黑暗森林或沿偏远边界移动。本研究探讨了如何将行走时发出的微弱声音转化为对士兵、警察和调查人员有力的早期预警工具,尤其适用于摄像头失效或电力匮乏的地区。
为何摄像头远远不够
现代安防常依赖视频监控,但摄像头存在明显局限:它们需要视线直达、耗电量大,并且在崎岖或敌对地形中难以快速部署。流动检查站、边境巡逻和反恐小组可能在夜间、茂密植被下或山区行动,这些地方安装和维护摄像网络并不现实。在这些情形下,声音成为一种有吸引力的替代方案。麦克风重量轻、耗电少,且能够“绕过拐角”——在目标可见之前就侦测到其存在。脚步声尽管相对安静,但在背景噪声较低的战术环境中往往更易被辨识,使其成为早期预警和事件取证重构的有希望信号。
构建真实世界的脚步声库
要把这一想法变成可用系统,研究人员首先要解决一个基本问题:缺乏合适的真实脚步录音集合。现有声音数据库中仅包含一些主要用于通用声学识别或身份匹配的脚步声,通常是在受控实验室条件下录制的。它们通常未标注声音发生在森林、道路还是室内,也未说明是单人还是多人发出。于是团队创建了名为 EWFootstep 1.0 的新资源。该数据集包含来自176名志愿者的1,650段音频片段,志愿者在印度三个不同地区的森林、道路和室内场景中自然行走。录音涵盖软底与硬底鞋、不同地形,以及如麦克风放置不均等现实场景条件。每段音频至少包含15次脚步,并按环境类型与单人或多人标注。
教机器像侦察兵一样听音
有了该数据集,作者设计了一种模仿熟练侦察兵听觉推理的监听系统。他们没有把所有任务一视同仁,而是采用“分层多任务”模型:先判断声音发生的环境——森林、道路或室内,然后在该语境下估计是单人还是多人。音频被转换为彩色谱图,显示随时间分布在不同频率上的能量。一组卷积层提取与地面和鞋类相关的细微特征,例如落叶的碎响或靴子在混凝土上的沉重撞击。随后这些特征传入一个变换器模块(transformer),该现代序列处理引擎检查跨多步的模式——节奏、间隔和重复冲击——而非孤立的声音。位置编码帮助模型保持时间顺序的信息,这对识别行走模式至关重要。
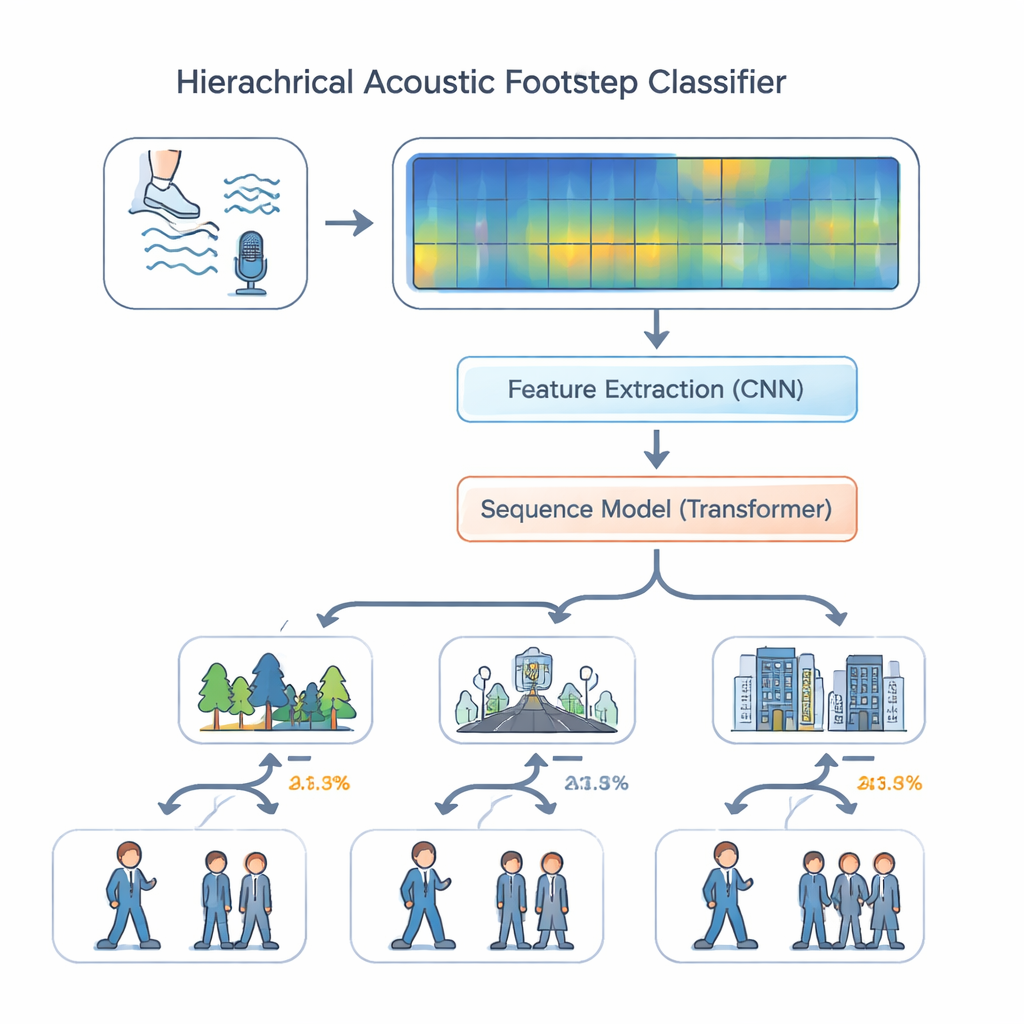
声学哨兵的表现如何?
研究人员将其分层模型与更简单的方法比较,例如单一整体分类器和环境与人数独立预测的标准多任务设计。他们还测试了去除关键组件(如卷积层或变换器)的变体。总体来看,包含两大模块与位置编码的完整设计表现最佳。在 EWFootstep 1.0 数据集上,该系统约96%的时间正确识别出环境,识别人数的准确率也相近——显著优于受过训练的人类听者,人类的准确率落后约25到30个百分点。在咳嗽声数据集上的额外实验表明,相同架构可较好地泛化至脚步声以外的声音类型,说明它能处理非常不同的日常音频。
从战场到犯罪现场
对非专业读者来说,关键结论是:像脚步这样微弱的日常声音包含的可用信息远超我们通常所觉察。通过将大规模、真实的数据集与先进的模式识别工具相结合,作者展示了一个紧凑的系统可以在近实时、无摄像头的条件下可靠判断听到的地点类型及人数。这个“声学哨兵”可用于保护巡逻队和偏远设施,其解析微妙声学模式的能力也能助力音频取证,例如在视频不可用或不可靠时重构犯罪现场的移动情形。
引用: Agrahri, A., Maurya, C.K., Tiwari, R.S. et al. Acoustic sentinel: hierarchical classification of footstep sound using fine and coarse-grain acoustic feature representations for tactical surveillance. Sci Rep 16, 5635 (2026). https://doi.org/10.1038/s41598-026-35756-3
关键词: 声学监视, 脚步检测, 预警系统, 深度学习音频, 战术安全