Clear Sky Science · zh
从数据到决策:可解释人工智能在主要产豆国预测大豆产量中的应用
更智能的作物预测为何重要
从超市价格到全球贸易,貌似普通的大豆在日常生活中扮演着意想不到的重要角色。政府、贸易商和农民都需要在收割机进入田间几个月前知道收成的规模。如今,强大的人工智能(AI)工具可以从海量的气象和卫星数据中筛选出预测信息——但许多模型像“黑箱”一样,几乎不解释为何得出某一结论。本研究探索了一种新型的可解释AI,它不仅能预测世界主要产豆国的大豆产量,还能清晰地展示哪些因素驱动了这些预测。
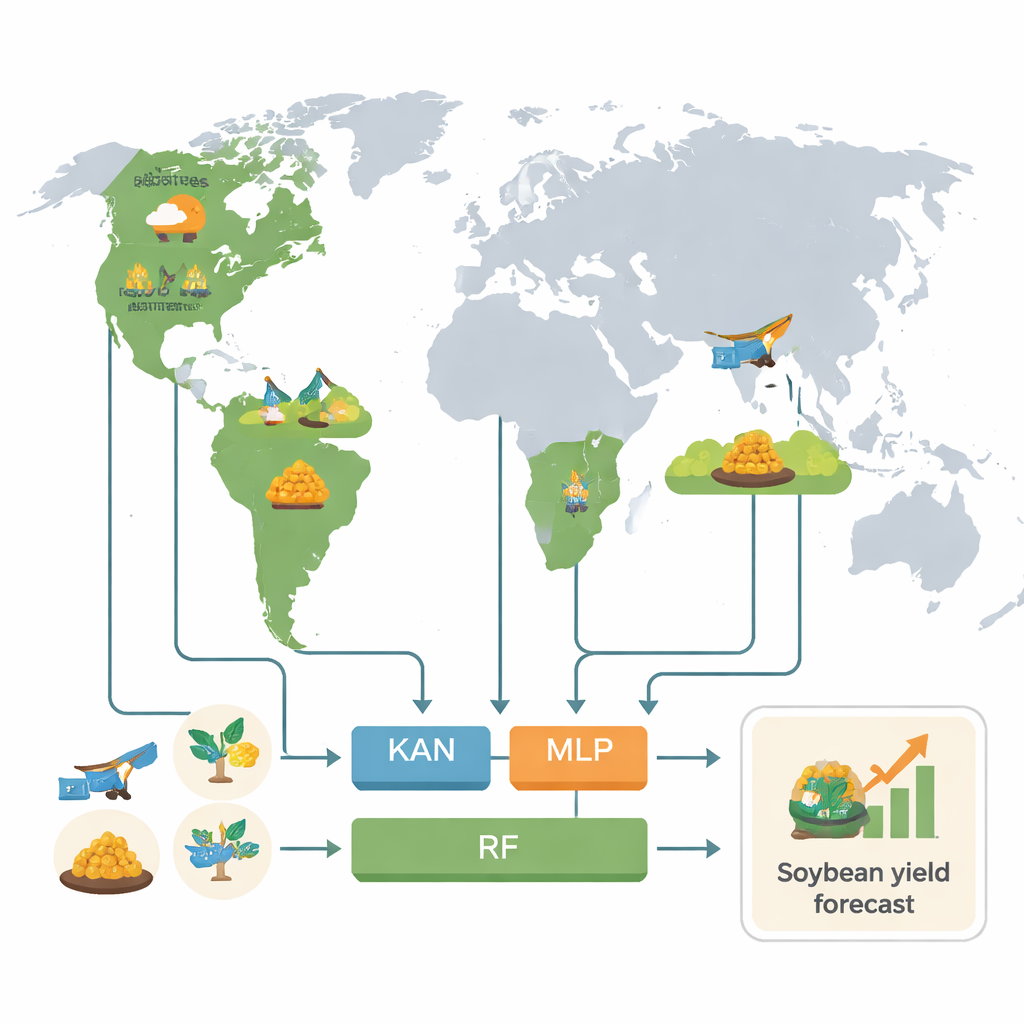
养活世界的三个国家
研究者聚焦于主导全球大豆供应的三国:美国、巴西和阿根廷,三者合计生产了全球超过80%的大豆。他们将研究尺度放在较细的单元——美国的县级以及巴西和阿根廷的同等小区——使用2018至2022年的最新数据。对每个区域,他们构建了关于生长状况的丰富画像:详细的气象记录、土壤特性,以及多种卫星数据,跟踪植被生长、水分状况,甚至与光合作用相关的微弱信号——太阳诱导叶绿素荧光(SIF)。总共提取了154项不同的数值特征来描述每个生长季,并将其输入模型。
从数据管道到学习机器
为处理这股信息洪流,团队建立了标准化的处理流程。他们利用作物日历在时空上对齐所有数据集,对嘈杂的卫星信号进行平滑处理,并用均值、极值和变异性等统计量总结生长季。随后,他们训练了三种类型的模型来预测产量:广泛使用的随机森林(RF);经典的深度神经网络多层感知器(MLP);以及一种从设计上更注重可解释性的较新架构——Kolmogorov–Arnold网络(KAN)。为避免自我欺骗式的过度乐观评估,作者谨慎地将数据按空间区块划分,使模型在未“见过”的区域上进行测试。
打开AI的黑箱
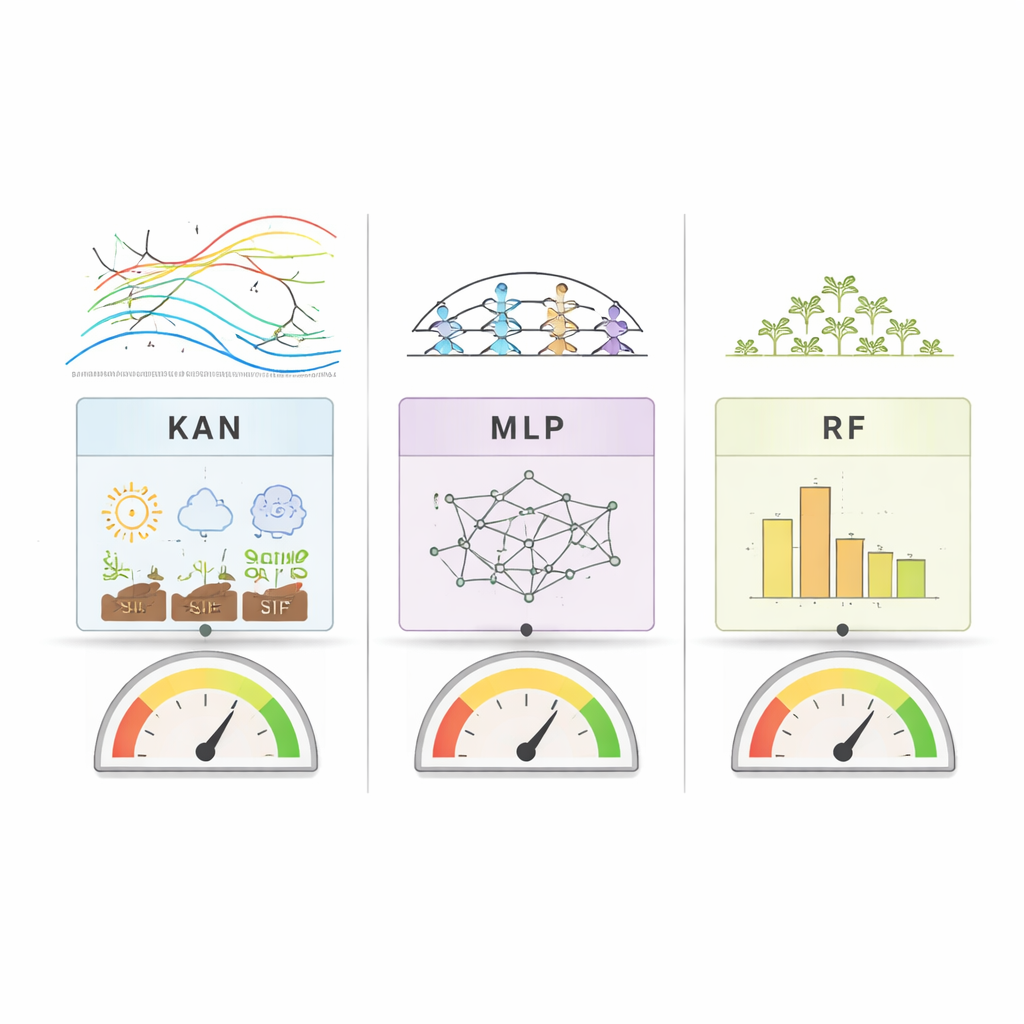
这项工作不同之处不仅在于预测的准确度,还在于模型如何解释自身。RF和MLP使用了标准工具来探查各输入特征对预测的重要性。KAN更进一步:它将输入与输出之间的关系表示为可绘制和检查的平滑一维曲线。研究者因此可以直观看到,例如SIF或土壤水分的变化如何推动产量上升或下降。跨国家与方法,一个清晰的模式浮现——SIF,即与光合作用直接相关的卫星信号,始终位列最重要的产量预测因子之列。其他关键驱动因素则随区域而异:在美国,与水分相关的植被信号尤为突出,而在巴西和阿根廷,温度和土壤水分的作用更强。
这些模型表现如何?
在比较模型精度时,没有任何单一方法在所有情形下全面胜出。在产量年际相对稳定的美国,随机森林总体表现略优,但KAN和MLP紧随其后。在产量更为波动且数据量更大的巴西,三种模型都取得了较高的准确度,尽管在预测极高产量时表现稍弱。在数据较为有限的阿根廷,KAN通常优于深度学习基线(MLP),并接近随机森林。这些结果表明,KAN在处理较小且具有挑战性的农业数据集时,能与传统模型匹敌,同时提供关于其推理过程的更大透明度。
对农民与粮食安全的意义
对实际决策者而言,信任模型的重要性可以和原始准确度相当。本研究表明,像KAN这样的可解释AI方法可以在提供有竞争力的大豆产量预测的同时,清晰揭示哪些环境与作物信号最为关键。这种可见性有助于科学家诊断误差、整合专业农艺知识,并将模型调整到新区域或变化中的气候条件。长期来看,这类透明工具可以纳入国家作物监测系统,为农民、规划者和市场提供更早、更可靠的歉收或丰收预警——从而支持更有弹性与可持续的粮食系统。
引用: Wang, X., He, Y., Chen, H. et al. From data to decisions: the use of explainable AI to forecast soybean yield in major producing countries. Sci Rep 16, 5103 (2026). https://doi.org/10.1038/s41598-026-35716-x
关键词: 大豆产量预测, 可解释人工智能, 遥感, 农业建模, 粮食安全