Clear Sky Science · zh
带有置信感知回归和自适应模板更新的Transformer增强双分支孪生跟踪器
教计算机在拥挤场景中跟随单个目标
从自动驾驶汽车到家庭安防摄像头和无人机,许多现代设备都需要在繁忙且不断变化的环境中跟踪单个移动目标。这个任务称为视觉目标跟踪,对人类来说看似简单,但对机器却出人意料地困难:有人会走到摄像头前面,光照会变化,目标会远去变小或被暂时遮挡。本文提出了TSDTrack,一种利用深度学习和Transformer最新进展的新跟踪系统,能够在此类真实场景下更可靠地锁定目标。
为什么只跟随一个物体如此困难
跟踪器通常只在视频的第一帧中清晰看到目标,然后必须在场景变化时持续识别它。传统方法要么依赖手工设计的图像特征,要么依赖将第一帧(“模板”)与每一帧进行比较的神经网络。这些较早的系统存在三个主要弱点。首先,它们通常保持原始模板不变,因此如果目标转向、部分被遮盖或尺寸变化,跟踪器就会困难重重。其次,它们经常只关注单一尺度的图像细节,错过了帮助人类识别物体的细微边缘与更广阔上下文的结合。第三,它们不知道何时应怀疑自己的判断:会在所谓的目标周围输出一个边框,但没有明确的可靠性度量,这使得它们容易漂移到背景上去。
将全局语境与精细细节融合
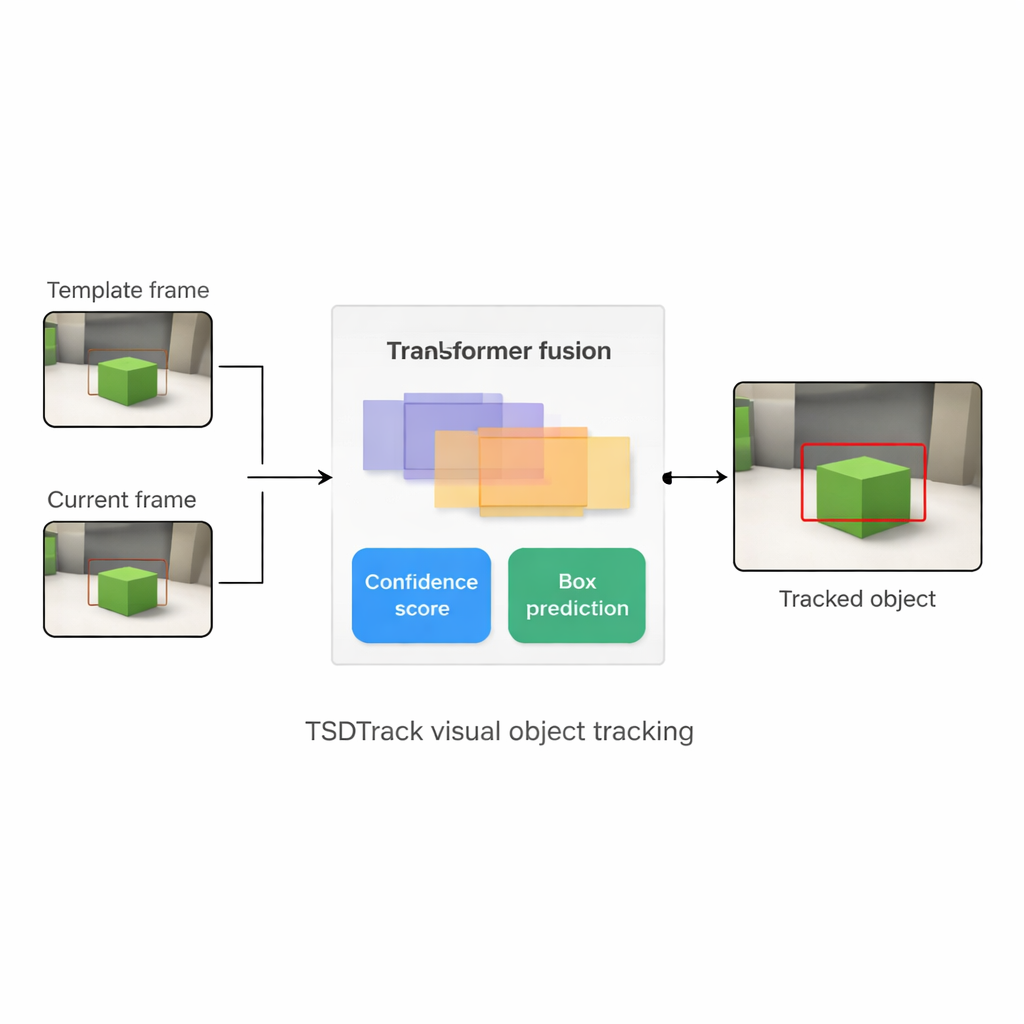
TSDTrack通过将经典的“孪生”跟踪结构与Transformer相结合来解决这些问题,Transformer是那种在语言和视觉任务中发挥重要作用的基于注意力的模型。该系统使用深度网络从两个输入中提取特征:定义目标的小补丁和包含当前搜索区域的较大补丁。它不依赖单一特征尺度,而是从网络的多个层次提取信息,这些层次分别表示边缘、形状和对象级模式。基于Transformer的融合模块学习如何混合这些层次,使得跟踪器既能理解图像中目标的位置,也能把握它们与更广泛场景之间的关系。这有助于在视图噪声或部分遮挡时,将目标与相似物体或杂乱背景区分开来。
知道跟踪器有多确定
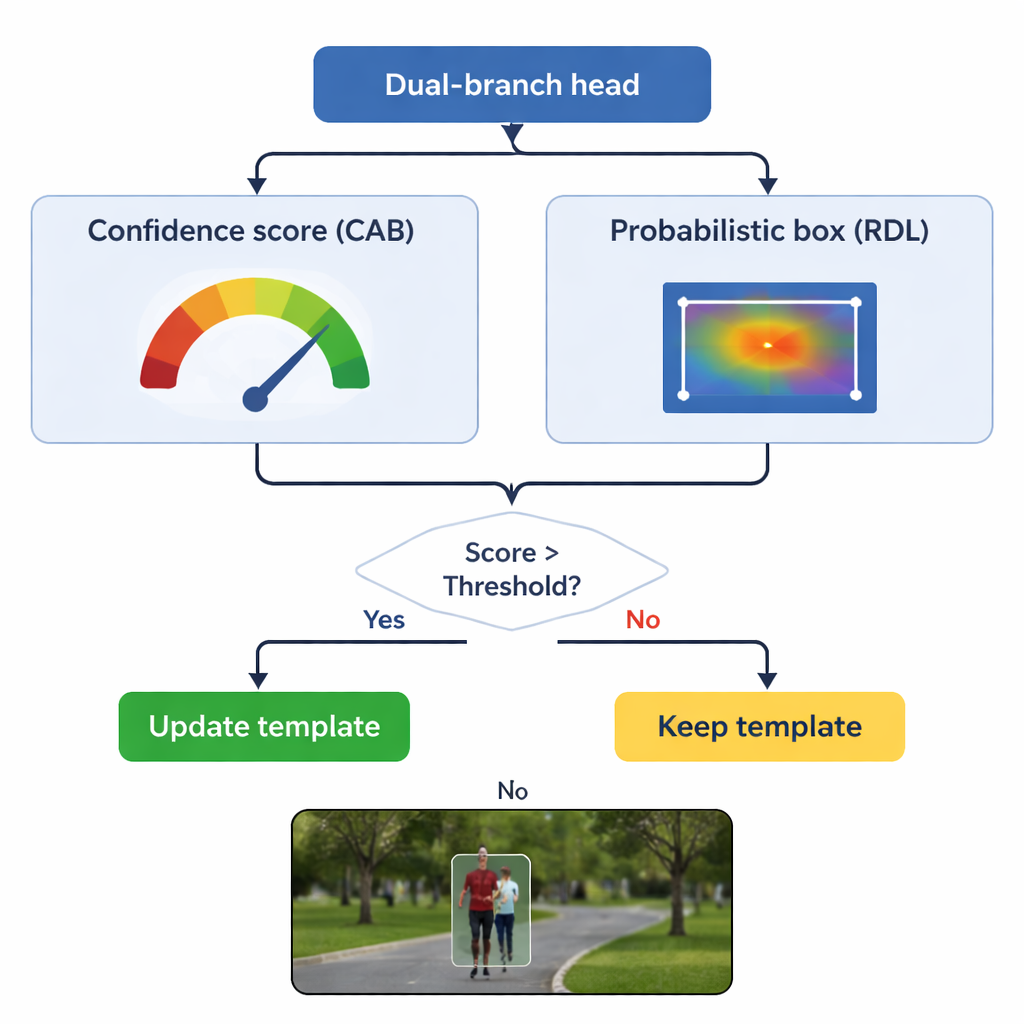
TSDTrack的核心是一个双分支的预测头,将任务分成两个相关问题:“目标在哪里?”和“我们应该多相信这个答案?”一条分支估计置信度分数,这个分数不仅反映目标外观的相似度,还反映预测框与可能目标区域的重叠程度。另一条分支则把框坐标视为多个可能位置上的概率分布,而不是单一猜测,从而允许模型表示不确定性。当图像清晰时,分布变得尖锐,边框更精确;当目标模糊或部分隐藏时,分布会扩展开来。这种概率化的视角相比只做单一刚性预测的旧跟踪器,能得到更平滑、更稳定的边框放置。
在不忘记原始信息的情况下更新记忆
跟踪中的一个关键风险是“模板漂移”:如果模型不断用有问题的帧更新目标表征,可能会逐渐学习到背景而不是目标。TSDTrack通过让其置信分支充当把关者来应对这一点。系统仅在置信度分数高于设定阈值时才更新内部模板,即便如此也会将新信息与原始视图温和地融合,而不是完全替换。这样的选择性更新让跟踪器能够适应真实的变化,例如人转身或车辆旋转,同时不会被瞬时遮挡或干扰所误导。原始模板也被保留为稳定的参考,以防后续更新被证明是误导性的。
这些结果在实践中意味着什么
作者在多个广泛使用的跟踪基准上测试了TSDTrack,包括长视频、快速运动、无人机航拍和严重杂乱的场景。在这些测试中,新方法在准确性(边框与真实目标的接近程度)和鲁棒性(完全丢失目标的频率)方面持续优于许多领先跟踪器,同时仍能在现代硬件上达到实时运行速度。对非专业读者来说,结论是:TSDTrack能更可靠地在真实摄像头的复杂条件下盯住选定目标。通过结合多尺度的Transformer推理、自身置信度感知和谨慎的模板更新,它为自动驾驶、智能监控和智能机器人等应用提供了更值得信赖的构建模块。
引用: Sachin Sakthi, K.S., Jeong, J.H. & Choi, W.Y. Transformer-augmented dual-branch siamese tracker with confidence-aware regression and adaptive template updating. Sci Rep 16, 5170 (2026). https://doi.org/10.1038/s41598-026-35692-2
关键词: 视觉目标跟踪, 基于Transformer的跟踪, 孪生网络, 计算机视觉, 自主系统