Clear Sky Science · zh
基于广义M估计的有限总体均值稳健估计方法学
为何混乱数据至关重要
当政府、科学家或民调人员试图了解整个总体的情况——例如平均收入、作物产量或污染水平——他们很少能对每个人进行测量。相反,他们抽取样本并进行推估。只有在数据表现良好时,这种做法才有效。然而在现实中,调查和测量常常充斥着错误和极端值,这些问题会严重扭曲结果。本文介绍了一种计算总体均值的新方法,即便在数据混乱时仍能保持可靠,从而使基于调查的决策更值得信赖。
简单平均何时出错
用于估计总体均值的常规工具,如简单样本平均或普通回归,假定大多数数据点遵循平滑模式,不存在极端离群或异常个案。但在社会经济调查、环境监测和农业统计中,这一假设常常不成立。少量错误读数、罕见但极端的事件或错误报告会把估计值拉离真实值,增加偏差和不确定性。早期研究尝试使用所谓的稳健方法来削弱这些离群值的影响,其中一种常用方法是哈伯(Huber)M估计。尽管有帮助,但这些方法主要针对被测结果中的极端值,仍对伴随的解释变量中的异常模式敏感。
一种更聪明的下调坏数据权重方式 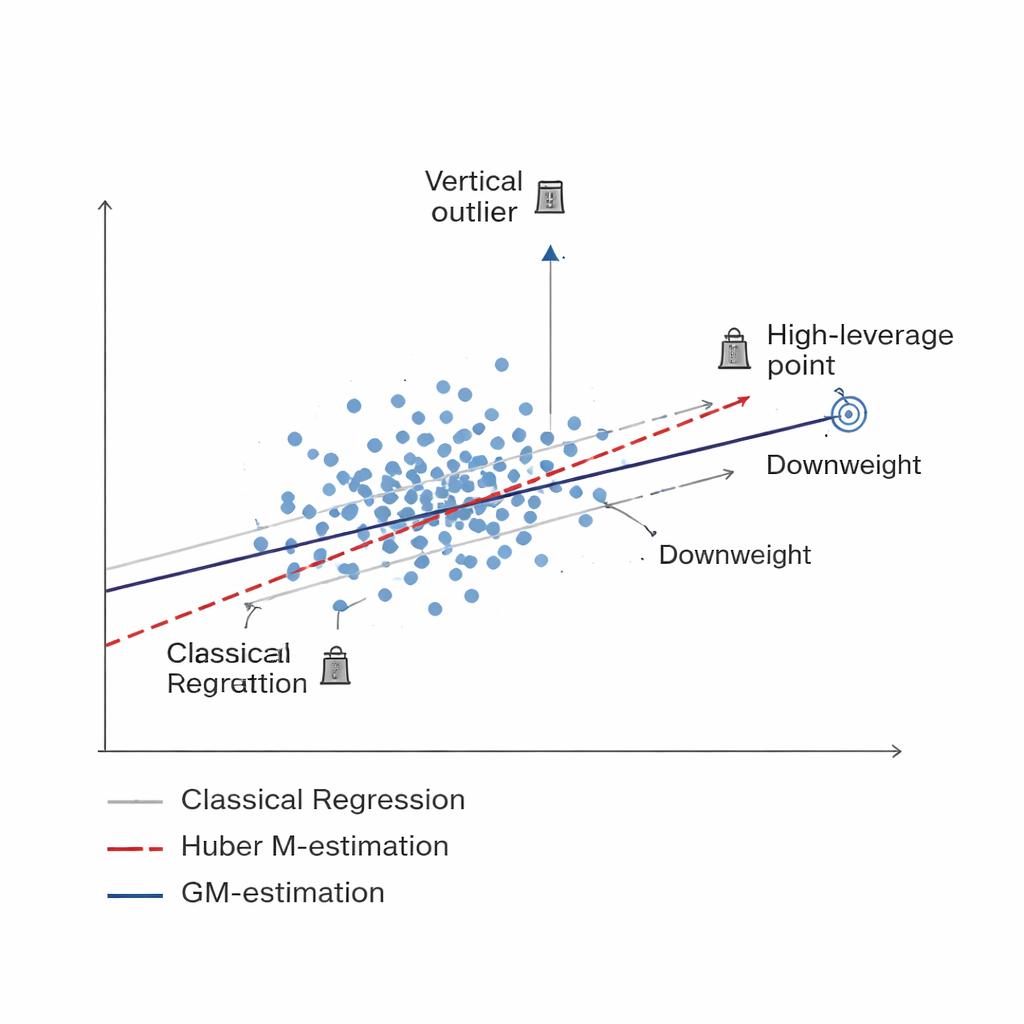
Figure 1.
本研究提出了一族基于广义M估计(GM估计)的新估计量。GM方法不是把每个样本单元一视同仁,而是赋予自适应权重,权重同时取决于两方面:单元响应有多极端(垂直离群)以及其相关信息有多不寻常(高杠杆点)。设计了三种具体变体——称为 Mallows-GM、Schweppes-GM 和 SIS-GM,适用于常见的调查设置,包括不放回的简单随机抽样和更复杂的分层设计(将总体划分为相对均匀的组)。通过同时控制这两类问题观测,这些估计量旨在即便数据受到严重污染也能保持总体均值估计的稳定性。
对新估计量的实证检验
为了检验基于GM的估计量的性能,作者进行了大量数值实验。首先,使用真实的烟草农业数据以两种形式进行分析:干净版本和故意污染版本(将一个单位替换为极端值)。新估计量与传统回归和基于哈伯的稳健方法进行比较,采用的衡量标准是相对效率百分比,反映估计误差缩小的程度。在广泛的样本量范围内,GM估计量始终优于旧方法,尤其是在数据包含极端值时。在某些情形下,表现最好的GM估计量相比哈伯方法将误差降低了超过50%。
在不同设计、情形和调参选择下的稳健性 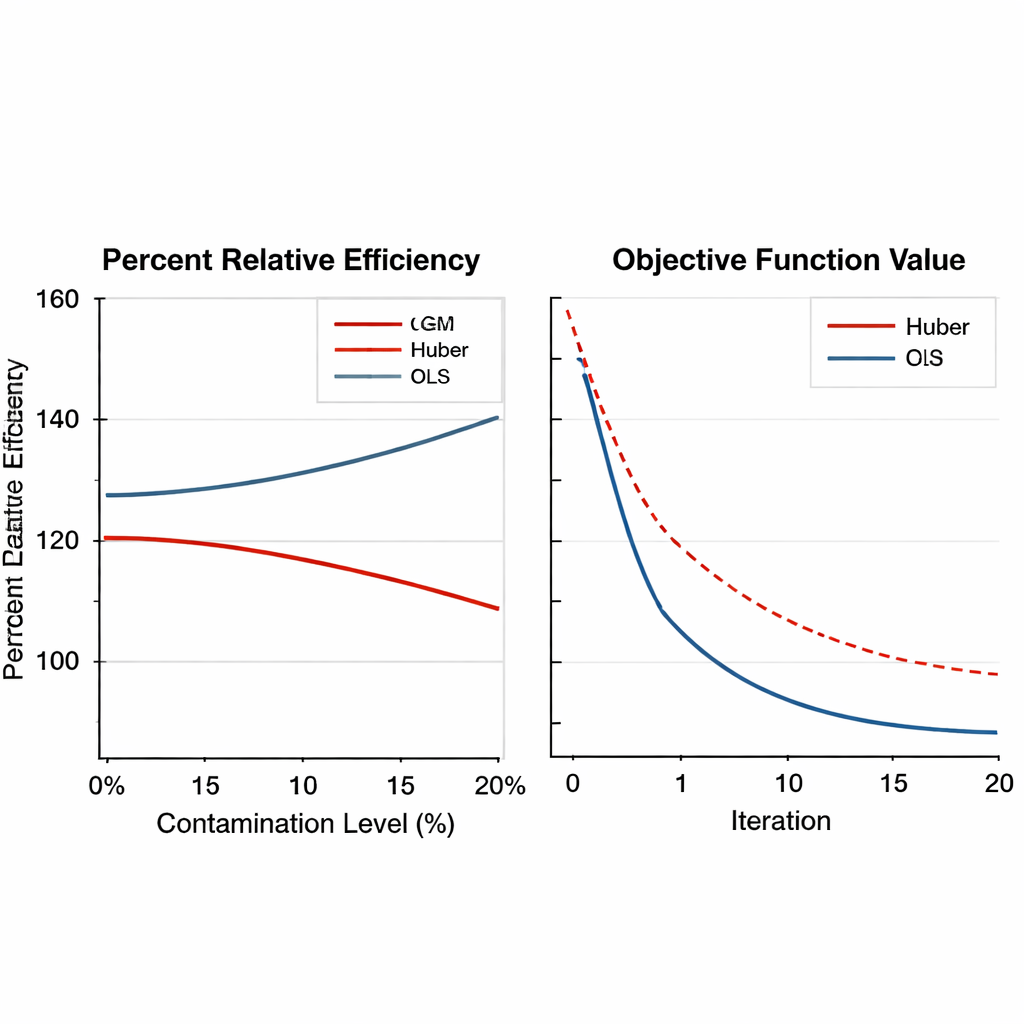
Figure 2.
论文随后通过大规模计算机模拟扩展了检验。人工总体在若干分布形态下生成——正态、偏斜和厚尾分布——并以不同比例污染离群值,从无到20%不等。考虑了简单抽样和分层抽样方案,并将主要变量与辅助变量之间关系的强度从弱到强进行变动。GM估计量不仅在严重污染下保持优势,效率提升常超过150%,而且数值收敛平稳可靠。值得注意的是,在合理范围内调整内部调参设置时,其性能变化不大,这意味着实践者无需为每次新调查做过于精细的参数微调。
这对实际调查意味着什么
简而言之,文章表明所提出的基于GM的估计量为将不完美样本转化为总体均值估计提供了更安全的途径。在理想、干净的数据条件下,它们与经典方法的准确度相当。但当数据包含测量误差、错误报告或罕见极端事件——这种情况在全国性调查、环境监测和金融统计中很常见——它们能提供显著更可靠的答案。由于这些方法在计算上可行,并且在不同设计和情形下表现良好,它们为调查实践者提供了一个实用的升级,可以使基于证据的决策对现实世界数据不可避免的混乱更具弹性。
引用: Abuhasel, K.A. A robust methodology for finite population mean estimation based on Generalized M estimation. Sci Rep 16, 5182 (2026). https://doi.org/10.1038/s41598-026-35592-5
关键词: 抽样调查, 稳健估计, 离群值, 广义M估计, 有限总体均值