Clear Sky Science · zh
基于双分支特征融合卷积神经网络的信道码盲识别
为拥挤频谱打造更聪明的无线电
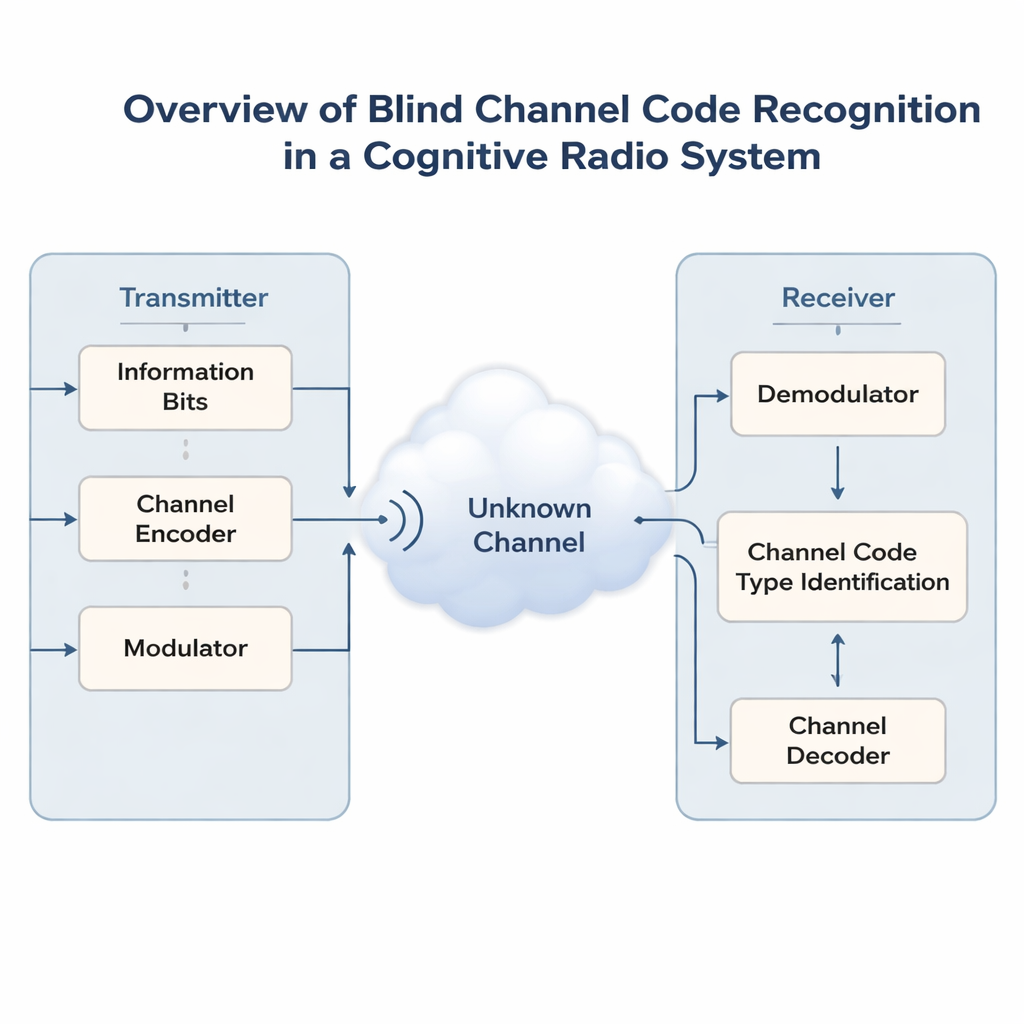
随着手机、传感器和车辆争夺相同频谱,无线网络越来越拥挤。为了避免混乱,未来的“认知无线电”需要先监听,然后智能地共享已被他人使用的频段。一个关键问题是,这些无线电通常不知道原始信号在发送前如何被保护以抵抗误码。本文提出了一种新的人工智能方法,能够在没有任何先验信息的情况下猜测信号所用的隐含纠错码,从而使智能接收端更容易锁定并可靠通信。
为何隐含纠错码很重要
现代无线链路使用纠错码来保护数据,这类码通过增加结构化冗余,使接收端能够修正噪声和干扰造成的错误。不同场景下需要不同的编码:简单的海明码、更强的BCH和Reed–Solomon码、灵活的LDPC和Polar码,或用于流式的卷积码和Turbo码。在非配合场景——例如军用通信、频谱监测或开放共享频段——接收端无法向发射端询问其使用的编码方案,只能看到噪声比特流。正确猜出编码方案(称为盲码识别)是进行任何有意义解码或更高层处理的前提。
早期识别方法的局限
早期研究要么一次只关注某一类码,要么依赖人工设计的统计量,如比特重复频率、序列的随机性度量或针对特定码的代数技巧。这些方法可能只能告诉你“这是某种分组码”,但难以同时区分多种流行格式。深度学习最近通过将比特流类比为语言模型中的句子而带来改进。然而,大多数神经网络要么只看原始序列,要么只使用手工特征,通常最多能同时处理两到三种码型。当比特误码率上升时,它们的准确率会急剧下降,而这恰恰是在需要鲁棒识别的时候。
同时观察结构与统计量的双轨神经网络
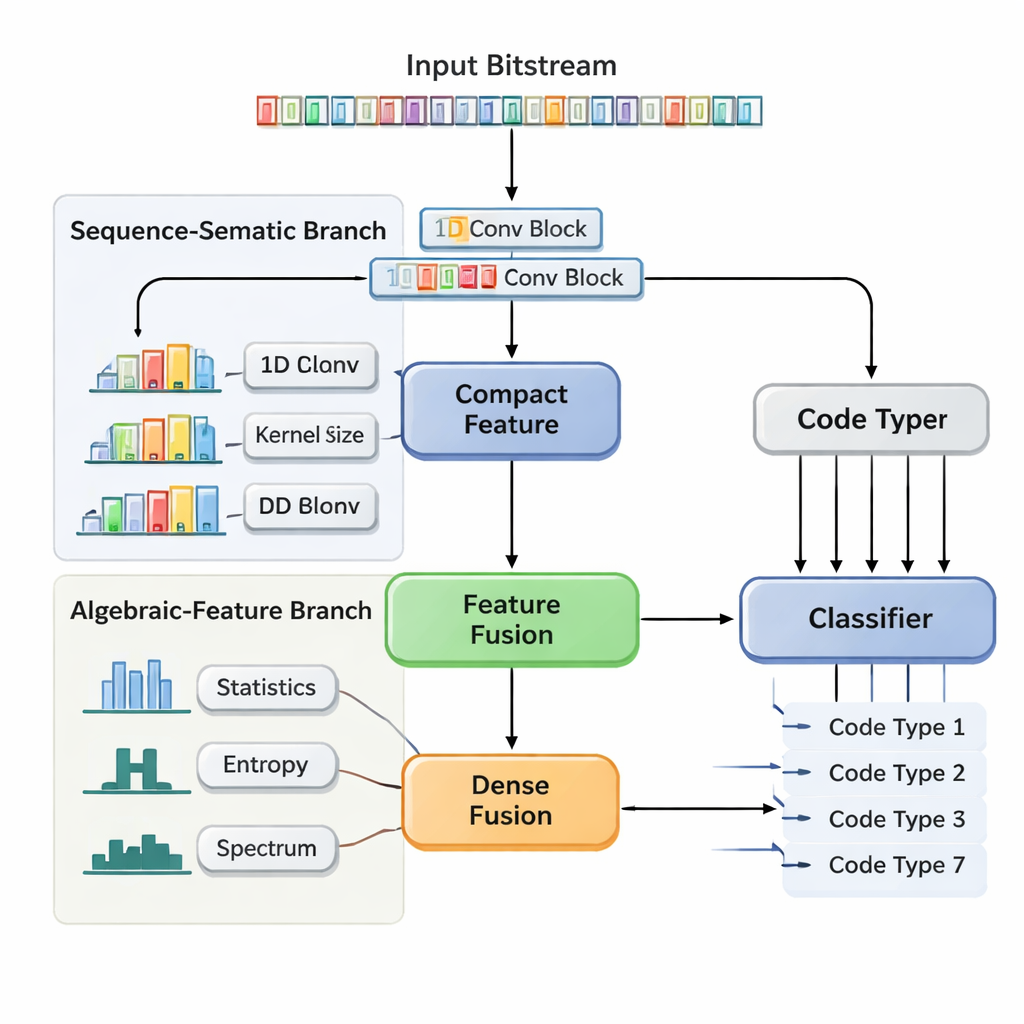
作者提出了一种双分支特征融合卷积神经网络(DBFCNN),一次性盲识别七种广泛使用的码:海明、BCH、Reed–Solomon、LDPC、Polar、卷积码和Turbo码。第一分支将输入比特看作短“词”,按8位为一组划分,并将每组映射为稠密向量,类似于自然语言处理中的词嵌入。然后对这些向量应用若干一维卷积,使用不同的窗口大小和膨胀率。小滤波器捕捉短程模式,比如简单分组码的紧致结构;而较大或膨胀的滤波器跨越更长范围,捕获交织器和Turbo/LDPC码典型的奇偶校验痕迹。全局池化步骤将其压缩为序列结构“指纹”的紧凑摘要。
稳固模型的人工设计测量
第二分支采用完全不同的视角。它不是直接处理原始比特,而是计算七类描述性统计量,工程师已知这些统计量对编码选择十分敏感。包括相同比特连续出现的频率、序列复杂度、外观随机性、与自身移位副本的相关性以及能量在频域的分布。额外度量探测编码的“线性程度”以及局部比特块的行为。由于这些统计量随噪声变化较慢,它们为网络提供了稳定、耐噪的视角。一个小型神经子网将该特征向量转换为另一个紧凑表示。最终,DBFCNN将两条分支拼接、归一化并正则化组合特征,然后送入分类器,输出七种码型的概率分布。
在噪声条件下证明可靠性
为严格评估DBFCNN,作者生成了超过一百万个合成样本,覆盖七类码、多个参数设定,以及从近乎无误到极为嘈杂的比特误码率。训练和测试过程中使用小心的蒙特卡洛程序,避免训练与测试数据间的隐含重叠。在这一广泛范围内,DBFCNN始终优于三个强基线模型,其中包括先前为该任务设计的多尺度膨胀CNN。在中低误码率(比特误码率低于10⁻³)下,新网络约98%的时间能正确识别码型,相比最强先前模型绝对准确率提升约5到11个百分点。即便在噪声很严重的情况下,DBFCNN仍保持明显优势,并能以高置信度识别若干复杂码型。
这对未来智能无线电意味着什么
对非专业读者而言,关键结论是:将领域知识与深度学习结合,可以显著提升无线电的自主管理能力。DBFCNN通过两种并行方式“听”噪声比特流,学习不同纠错码的微妙“口音”:一条分支捕捉详细的局部模式,另一条衡量全局统计线索。通过融合这些视角,系统通常能在没有发射端配合的情况下判断所用的编码方案。这一能力是认知无线电的基石,使其能够加入陌生网络、适应变化环境、更有效地利用稀缺频谱,并在频谱拥挤和噪声环境下仍保持可靠通信。
引用: Ma, Y., Lei, Y., Liu, C. et al. Blind recognition of channel codes based on dual-branch feature fusion convolutional neural networks. Sci Rep 16, 5159 (2026). https://doi.org/10.1038/s41598-026-35558-7
关键词: 认知无线电, 信道编码, 深度学习, 纠错, 信号分类