Clear Sky Science · zh
基于K-中位数与高斯核图注意力网络的社交用户地理定位
为什么你的推文会暴露你的居住地
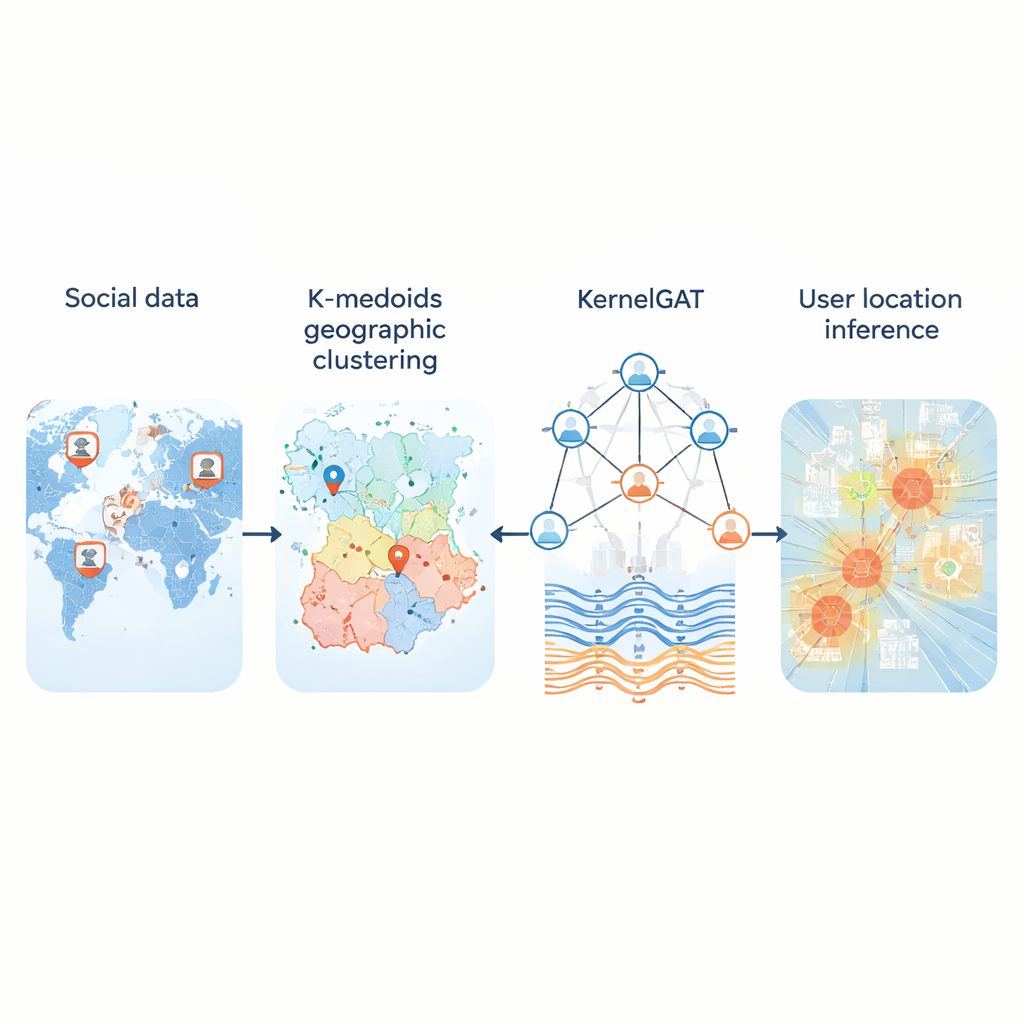
每天都有数百万人在社交媒体上发布内容而不分享GPS坐标。然而,那些帖子仍然会留下关于用户居住、工作和出行地点的线索。能够从这些公开轨迹推断位置,对应急响应、疾病追踪、本地推荐和定向服务等应用都很重要。本文提出了一种新方法,称为KMKGAT,它同时利用用户的言论内容和线上连接关系来估算用户位置,准确性优于早期方法。
从网络话语到现实地点
当用户发推或写微文时,可能会提到地名、使用本地俚语或与附近的朋友互动。像Twitter(现X)这样的公司知道用户的互联网地址,但外部研究者和服务提供者通常不知道。他们只能利用公开信息:文本本身、用户资料以及谁与谁互动。早期方法大致分为三类。仅内容的方法挖掘词语和标签来猜测位置;仅网络的方法依赖人们倾向于与近距离用户互动这一事实;第三类更强的方法结合了两种视角,但仍有盲点——尤其对人口稀少地区的用户以及那些在线连接跨越远距离的用户。
用真实用户为中心的更智能地理分组
一个关键问题是如何将连续的地理空间转化为计算机可以学习预测的一组区域。许多系统把地图划成固定网格。在城市里这比较有效,但在乡村地区则失败,巨大的网格单元可能覆盖数百公里。新方法用k-中位数聚类取代了僵化的网格,这种方法将用户分组,使每个区域以真实用户为中心而非人为点位。这使得区域更紧凑、对离群点更不敏感,尤其在人口稀疏的地方。在覆盖美国和全球的三个大型Twitter数据集上的测试表明,这种自适应分区相比基于网格的方案降低了典型误差,并为用户提供了更现实的“居住区域”。
让网络聚焦于附近且相似的用户
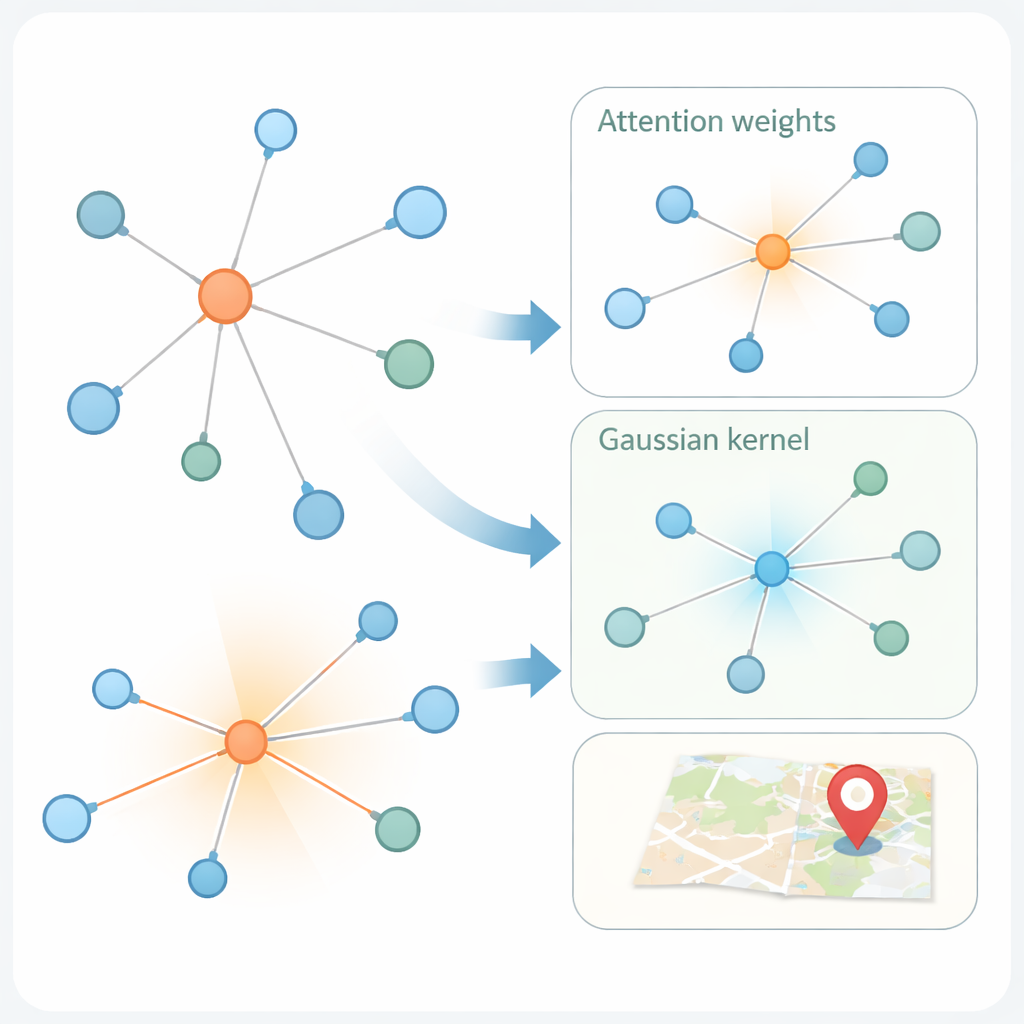
第二项创新在于模型从社交图中学习的方式。现代“图注意力网络”本已根据邻居特征表示的相似程度对其加权。但仅靠相似性有时会产生误导:纽约的账号和伦敦的账号可能语言相似,却在地理上相距甚远。KMKGAT在注意力机制中加入了高斯核——一种数学滤波器,偏好那些在学习特征上与目标用户接近的邻居,并抑制远距离邻居的影响。多个这样的核像镜头混合一样结合,使模型能够捕捉不同尺度的局部性。这遵循了一个简单但有力的原则:在线互动往往在物理上更接近的人之间更强。
轻量级文本特征仍携带位置信息
作者没有依赖昂贵的大型深度语言模型——这些模型在处理嘈杂且充满俚语的推文时可能表现欠佳——而是使用经典技术TF–IDF将每个用户的帖子集合转为一袋加权关键词。像“the”或“lol”这样的常见词权重很低,而较少见、具有区域性的词则权重更高。这些文本特征随后附加到社交图中的每个用户,并通过增强的注意力网络传递。有趣的是,在训练过程中随机丢弃大部分文本特征时效果最好,表明实际上只有一小部分词对定位有帮助,其余多为噪声。
在规模上超越现有最优方法
为评估性能,研究者衡量了预测区域中心与每个用户已知坐标之间的千米距离,以及有多少百分比的用户被放置在距其真实位置161公里(100英里)以内。在三个基准Twitter数据集上,KMKGAT始终匹配或优于强基线系统,在161公里内的准确率提升了几个百分点——在这一成熟度水平上这是有意义的增益。收益在小型和中型网络上最为明显,而在一个大规模全球图上,该方法受限于训练时只采样即时邻居的做法。
这在日常生活中的含义
对非专业人士来说,结论是:即便用户从未分享位置标签,估计社交媒体用户的大致位置也越来越可行。通过基于真实账号将用户分组,并训练模型主要信任社交网络中附近且相似的邻居,KMKGAT能缩小某人可能居住或发帖的位置范围。这可以帮助灾难期间寻找人员、改进本地搜索与推荐,并支持关于信息如何跨地域传播的研究。与此同时,它也凸显了我们日常线上互动可能泄露线下生活信息的程度,强调了审慎使用数据与隐私保护的重要性。
引用: Jiao, A., Qiao, Y., Li, P. et al. Social user geolocation based on K-medoids and Gaussian Kernel graph attention network. Sci Rep 16, 5115 (2026). https://doi.org/10.1038/s41598-026-35532-3
关键词: 社交媒体地理定位, Twitter用户位置, 图神经网络, 基于位置的服务, 在线隐私