Clear Sky Science · zh
使用经改进的Kepler优化算法修正的双向循环神经网络进行大学行政服务意图分类
为日常校园问题提供更智能的数字帮助
大学生现在期望无论何时都能获得快速、准确的答案——无论是在申请录取、选课登记,还是询问助学金时。本文探讨了一种专为大学行政服务设计的新型人工智能聊天机器人,重点处理英语和希腊语。通过让单一系统更好地理解学生的意图和关键细节,作者旨在让数字服务台更快速、更可靠且更易于维护。
为何现有聊天机器人仍会困惑
大多数现代聊天机器人依赖一个称为自然语言理解的领域,它将学生的问题分解为两部分。首先是意图:学生想要做什么,例如“注册课程”或“询问截止日期”。其次是实体:问题中具体的信息片段,如课程代码、学期或专业名称。传统系统对这两项任务使用独立的模型。这种分离浪费了内存和计算资源,并可能导致不一致的回答——例如,正确识别出课程代码却未能将其与正确的操作关联。在多语种环境中,这些问题会变得更加严重,因为同一含义可以在不同语言中以多种形式表达。
一个大脑替代两个
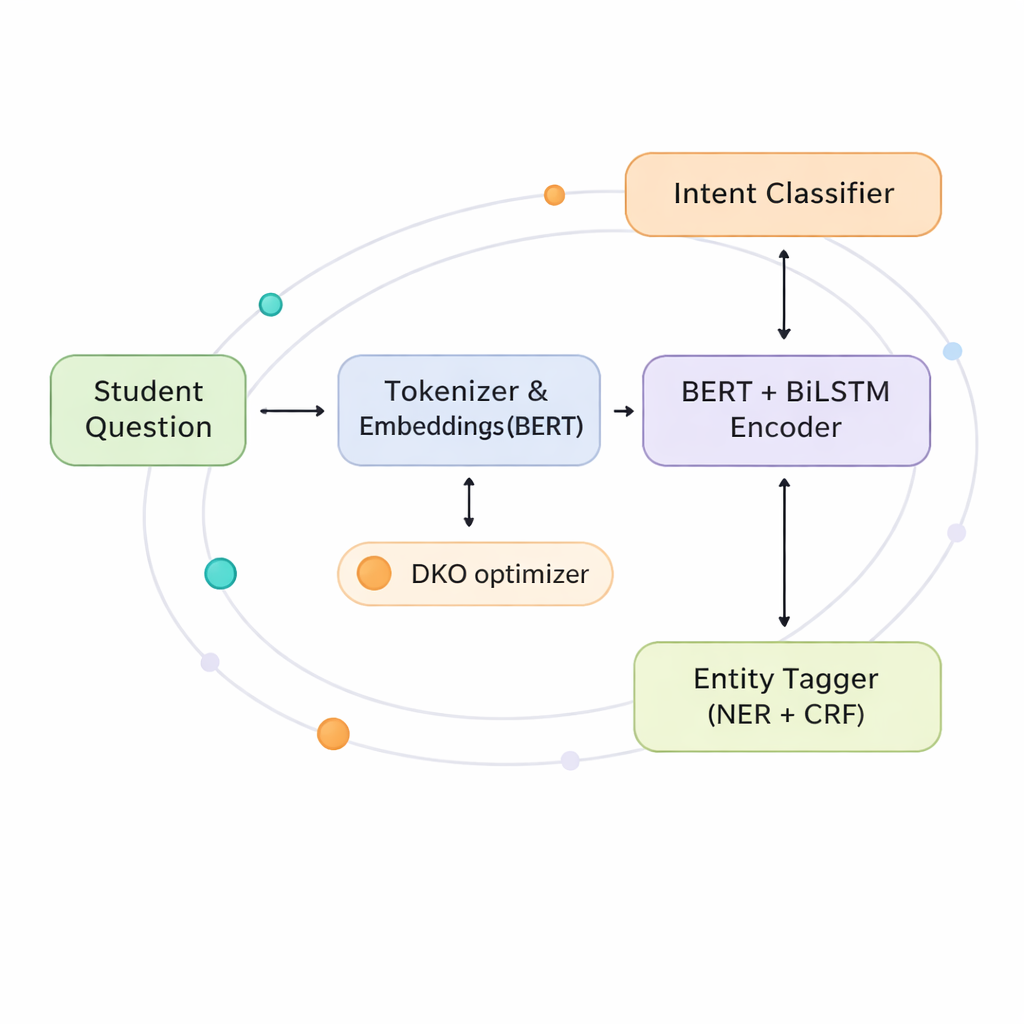
作者提出了一个联合模型,能够同时学习识别意图和实体,使用共享的“脑”而非两个独立的模块。其核心结合了两种强大的技术。第一种是BERT,它一次性查看整个句子以捕捉整体含义。第二种是双向LSTM网络,它同时关注从左到右和从右到左的词序,有助于跟踪临近关系,例如哪个课程对应哪个学期。在这种共享理解之上,系统分为两条分支:一条预测学生的意图,另一条为每个词标注其是否为实体及其类型。
让任务彼此对话
为了充分利用这一共享“大脑”,模型包含一个“协同交互Transformer”层,使两项任务能够实时相互提供信息。当系统在判断意图时,可以参考它认为存在的实体;在标注实体时,又可以依赖看起来最可能的意图。这种交互有助于消除歧义,例如“drop”是指退课还是取消申请,且在希腊语中尤为有价值,因为希腊语的词形和词序比英语更灵活。通过共享表示和注意力,这种方法相比分别运行两个大型模型将参数数量减少近一半,使其对大学信息技术部门更具实用性。
一种受宇宙启发的模型训练方式
训练如此复杂的模型很困难:标准优化方法可能速度慢且对超参数敏感。作者引入了发展型Kepler优化(Developed Kepler Optimization,DKO)算法,其灵感来自行星绕太阳的轨道运动。在这个类比中,不同版本的模型像行星一样在可能的参数空间中探索,同时被性能最优的“太阳”所吸引。DKO以比通常更分散的初始候选集开始,然后根据其表现不断调整它们的“轨道”。与一种流行方法Adam相比,这种方法将学习速度提高了约42%,同时使训练更稳定,尤其是在复杂的多语种数据上。
与学生的真实世界测试
研究团队在多个数据集上评估了他们的系统,包括UniWay(涵盖有关大学服务的英语和希腊语问题集合)和xSID(一项用于理解简短指令的知名基准)。在所有数据集上,联合模型持续优于基于规则的系统、较老的神经网络乃至强大的Transformer基线。在两所高校的实地试验中——一所仅用英语,另一所为双语——聊天机器人正确识别学生的意图和实体约有九成,学生满意度评分约为4.5(满分5)。即便在训练数据减少的情况下,性能仍然强劲,表明该方法在资源较少的语言和领域中也具有鲁棒性。
这对学生和大学意味着什么
对普通读者而言,关键结论是作者设计了一个更高效、更准确的大学聊天机器人“倾听引擎”。通过统一意图检测与细节提取,并采用一种受轨道启发的训练方法,他们的系统能够更好地把握学生的提问,同时使用更少的内存和训练时间。这可能转化为更快的回应、更少的误解以及全天候的多语种支持而不至于过度依赖人工。尽管仍有挑战——如适应新的政策、更多语言以及长期使用模式——该工作指向了更具响应性、公平性和可扩展性的校园帮助系统。
引用: Yang, Z., Lu, M. & Huang, S. Intent classification for university administrative services using a bidirectional recurrent neural network modified by a developed Kepler optimization algorithm. Sci Rep 16, 6263 (2026). https://doi.org/10.1038/s41598-026-35504-7
关键词: 大学聊天机器人, 意图分类, 命名实体识别, 多语种人工智能, 优化算法