Clear Sky Science · zh
使用有根大型语言模型自动识别情境相关的生物医学实体
为什么更智能的医学论文标注至关重要
每年都有成千上万篇生物医学研究发表,里面充满了关于基因、细胞类型、疾病和治疗的信息。然而,这些信息大多被锁在冗长的 PDF 中,其他科学家很难找到他们需要的具体数据。本文探讨了现代人工智能——大型语言模型(LLM)——如何自动从研究论文中提取这些关键生物医学术语,帮助将分散的出版物转化为结构良好、可检索的资源。
从混乱的论文到可搜索的构件
生物医学研究中心,例如德国的协作研究中心,依赖清晰、结构化的数据以便多年后仍能重复利用研究成果。传统上,研究人员必须手动为他们的数据集标注重要实体,如生物体、细胞系和基因——既繁琐又耗时。大型语言模型可以阅读整篇论文并理解语境,使其成为自动化标注的有力工具。但问题在于:哪些术语是真正相关的取决于具体的科学问题和数据将如何被重用。作者在以肾脏学为中心的 CRC “NephGen” 的精心设计的元数据方案内工作,该方案告诉 AI 应该寻找哪些类型的实体以及如何组织它们。
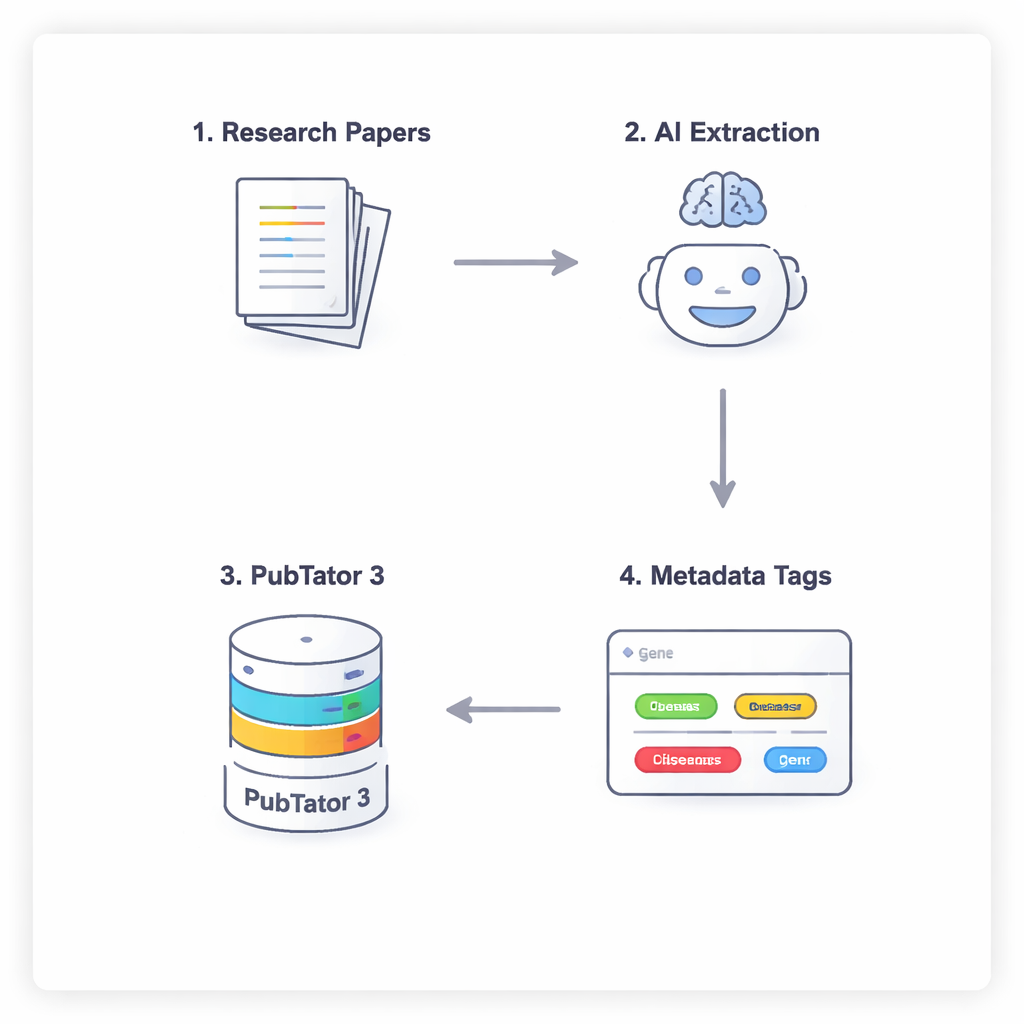
AI 与生物学数据库之间的四步对话
为防止 AI 仅凭猜测或“幻觉”生成生物医学事实,研究人员采用了一套四步流程,迫使模型谨慎推理并进行自我核查。首先,模型扫描论文全文(忽略讨论和参考文献),提出潜在相关的实体。第二步,它必须查阅外部工具 PubTator 3(大型生物医学数据库),以确认每个建议的术语确实存在并具有认可的标识符。第三步,AI 将每个经确认的实体分配到 NephGen 元数据方案中的相应槽位,该方案以分层、人工设计的结构对实体进行分组。最后,模型将所有这些整合为结构化的 JSON 输出,本质上是文章中关键生物医学实体的整洁机器可读摘要。
用真实肾脏研究测试八种 AI 模型
团队通过 14 种不同 LLM 的 API 实现了该工作流,发现只有八种模型能够可靠地遵循严格要求,例如返回有效的 JSON 并正确使用工具。然后他们将这八个模型应用于六篇肾脏学研究文章,并在短暂的面对面访谈中请每篇论文的作者审查 AI 的最终实体列表。由于没有固定的“正确”实体数量可供提取,作者将重点放在精确度上:被科学家判断为正确的建议实体所占的比例。使用针对接近 100% 比例调整的统计元分析方法,他们在考虑论文间差异的情况下估计了每个模型的精确度。
高准确率,但需要在工作量、成本与速度之间权衡
在所有模型中,AI 系统总体精确度约为 91%,意味着绝大多数建议的实体被判断为正确。GPT-4.1、GPT-4o Mini 和 Gemini 2.0 Flash 的精确度最高——大约在 94% 到 98% 之间——尽管它们之间的差异在统计上并不明显。Gemini 系列模型通常提出更多实体,带来了更多正确的标注,但也增加了人工核查的工作量。一些更小或更便宜的模型,例如 GPT-4.1 Nano,虽然速度更快且成本更低,但准确性明显较低。作者使用帕累托前沿可视化这些权衡,识别在精确度、正确实体数量、成本和处理时间之间取得平衡的模型组合:例如,当既看重准确性又看重低成本时,GPT-4o Mini 显得特别有吸引力。
为什么人类仍需参与流程
尽管表现强劲,研究强调了若干重要限制。模型有时会混淆已发表文章的信息与那些并非真正与未来用户希望重用的数据集相关的细节。这种混淆反映了自动化文本挖掘中的一个更广泛挑战:科学论文讨论的内容远超最终纳入共享数据集的内容。因此,作者建议在 AI 生成的注释发布前继续由人类专家进行复核。他们还指出,他们的评估仅涵盖六篇肾脏学论文,因此需要在更广泛的领域中进行测试。随着时间推移,常规的“人机循环”工作流可以构建一致的参考集,从而不仅测量精确度,还能评估 AI 漏掉了多少实体。
这对未来生物医学数据共享意味着什么
研究表明,在经过谨慎引导并以可信数据库为根基的情况下,现代大型语言模型可以可靠地帮助注释生物医学论文,大幅减少研究人员的手动负担。表现最好的模型接近专家级精确度,同时在全面性、成本和速度之间提供多种权衡。当前,人类复核仍然是确保注释与数据集和研究语境真正匹配的必要环节。但随着工具和开源模型不断成熟,这类工作流有望成为将当今大量医学论文转化为未来结构良好、可重用数据共享平台的标准骨干。
引用: Watter, M., Giuliani, C., Benadi, G. et al. Automated identification of contextually relevant biomedical entities with grounded LLMs. Sci Rep 16, 1952 (2026). https://doi.org/10.1038/s41598-026-35492-8
关键词: 生物医学文本挖掘, 大型语言模型, 元数据注释, 有根人工智能, 肾脏学研究