Clear Sky Science · zh
人类与人工智能对治疗方案评估分歧
这对日常医疗为何重要
随着人工智能(AI)工具开始协助医生选择治疗方案,一个关键问题浮出水面:我们更应信任谁的判断——人类还是机器?本研究关注一个简单但令人不安的可能性:医生与AI系统可能不仅在哪种治疗最好上存在分歧,还可能对什么构成“良好”治疗方案本身有不同判断。理解这一差异至关重要,只有如此我们才能让AI成为支持而非悄然扭曲现实医疗决策的力量。
治疗建议的正面对抗测试
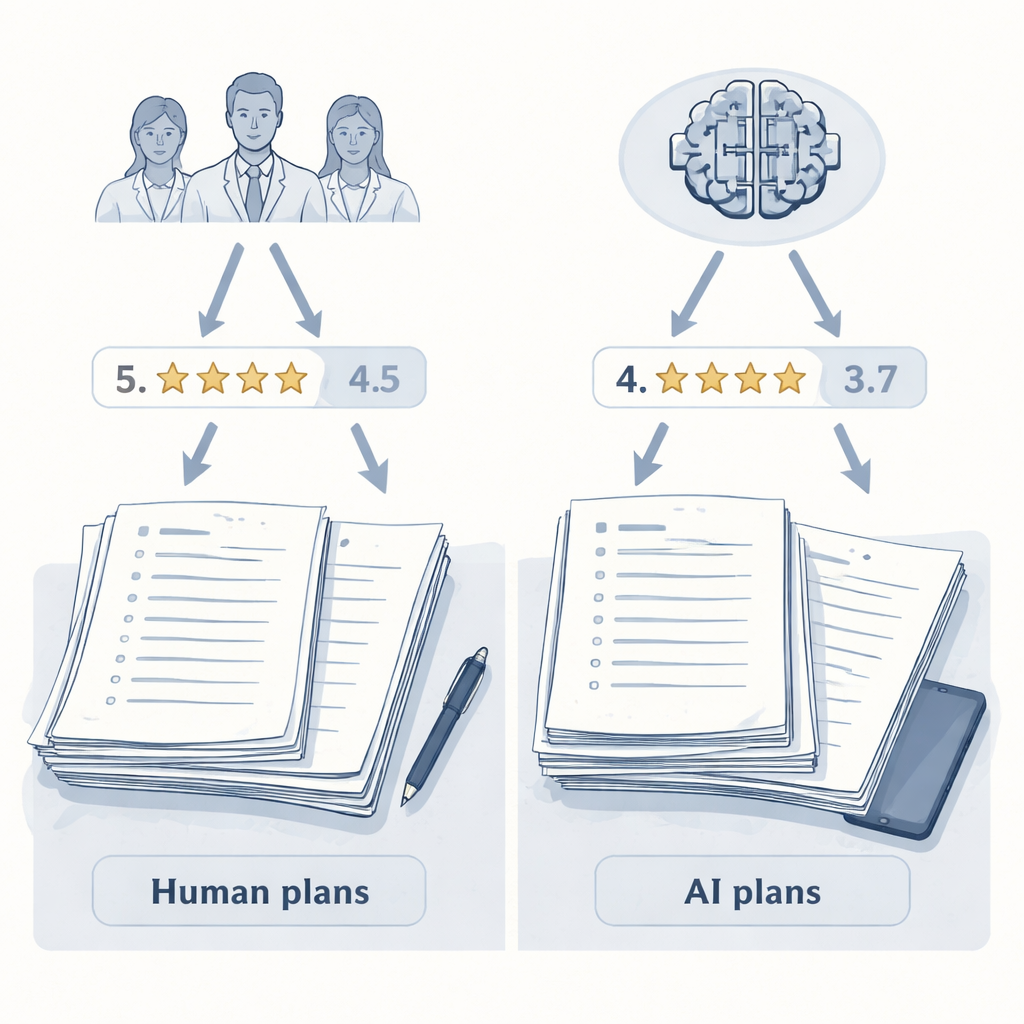
研究人员把焦点放在皮肤科——这个领域的医生常常管理一些长期皮肤病,这些疾病很少有单一“正确”答案。十位有经验的皮肤科医生和两种大型语言模型(LLM)——一种通用模型和一种侧重推理的模型——各自被要求为五个具有挑战性的虚构病例撰写治疗方案,病例包括重度湿疹、伴有其他疾病的银屑病以及妊娠相关痤疮等。为了保持公平,所有60份方案都被编辑成统一格式:长度、结构和语气相似。任何明显表明作者是人类或AI的线索都被移除,以便后来的评审只评价内容而非风格。
人类与AI如何担任评审
这些方案随后通过两轮盲评,使用相同的评分量表。首先,同一组十位皮肤科医生对每份方案的总体质量进行0到10分的评分,考虑其有效性、安全性、可行性和以病人为中心的程度。接着,一台单独的AI模型——仅作为评审者,不参与方案撰写——用相同的指示对完全相同的方案打分。关键在于,无论是人类评审还是AI评审,都不知道任何方案的作者是谁。这一设计使作者能够将一个关键因素孤立出来:评估者到底是人类还是AI。
人类支持人类,AI支持AI
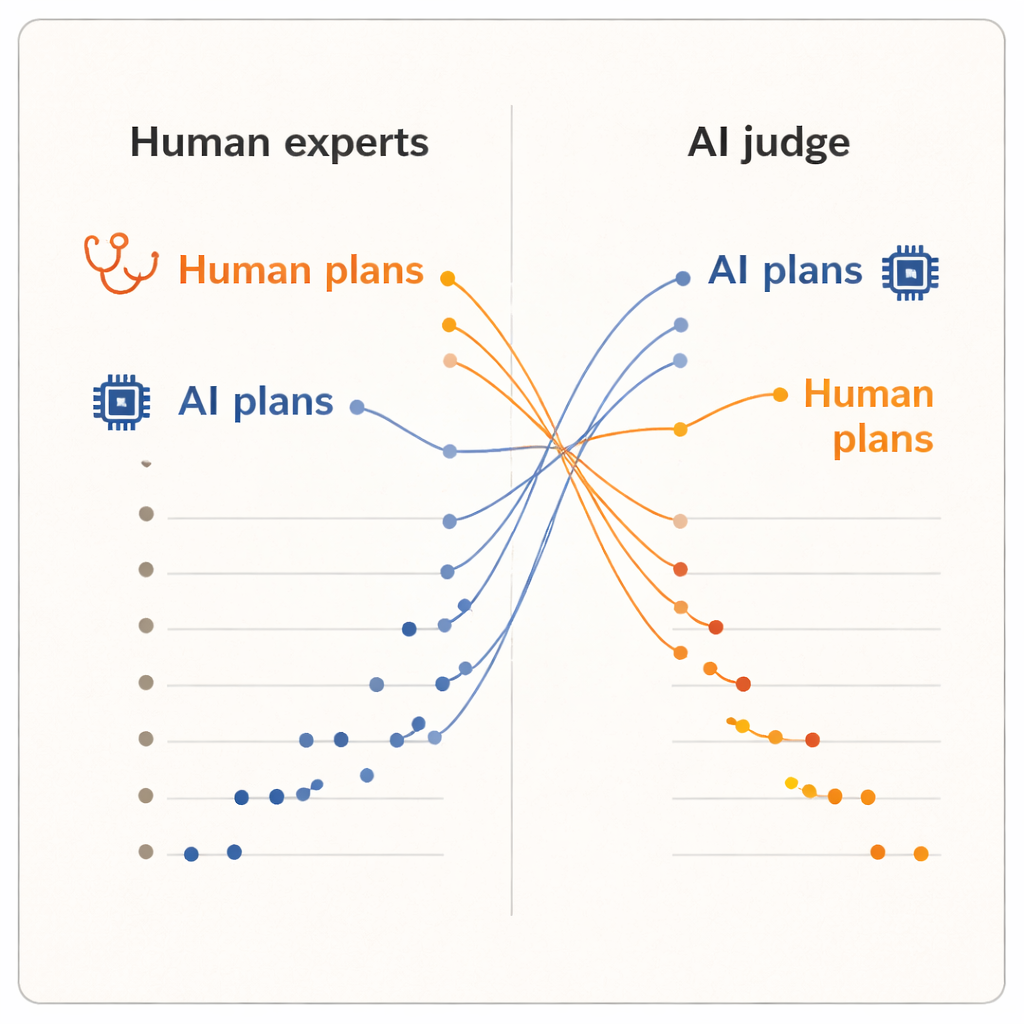
结果显示了明确的“评审者效应”。当人类对方案打分时,他们倾向于给同为皮肤科医生撰写的方案更高的分数,而不是给任一AI系统撰写的方案。人类撰写的方案平均分略高,并占据了排名的前五名。两种AI模型之一、那种高级推理系统,则位于接近底部的位置。但当AI评审接手时,情况发生了翻转。此时,两份AI撰写的方案升至排名前列,而所有人类医生的方案则落在其后。平均来看,AI评审对AI生成的方案打分高于人类生成的方案,尽管它阅读的是与皮肤科医生所见完全相同、已标准化的文本。
关于什么是“优秀”方案的不同观念
由于方案在措辞上已被规范化,评审者也对来源保密,作者认为这种分歧不能用表面润色来解释。相反,这表明人类与AI在内部衡量标准上存在差异。临床医生很可能依赖现实世界经验:在他们所属诊所哪些做法可行、病人如何反应以及哪些权衡在实践中被认为可接受。相比之下,经过大量文本训练的AI评审可能更偏好医疗文献或指南中常见的模式,即便这些模式未必充分反映本地的限制或病人的偏好。该研究规模有限——仅十位临床医生、五个病例和一台AI评审——并且衡量的是感知质量,而非真实的病人结局。但这一反转仍足以提出更深层的问题:我们应如何评估临床AI。
重新思考临床AI的测试与使用方式
基于这些发现,作者得出两点广泛启示。首先,传统的“标准答案”式医学AI测试忽略了真实护理中许多重要因素,在临床中,治疗方案必须在疗效、安全性、成本、后勤和病人意愿之间权衡。他们主张采用更丰富的、多指标评估框架,明确为这些维度评分,使用多位人类与AI评审,并分析分歧出现的地点与原因,而不是将一切简化为单一分数。第二,他们指出人类与AI判断的差异可以是一个特征,而不仅仅是缺陷。如若谨慎使用,AI生成的方案可以作为富有洞见的第二意见,促使医生重新审视假设;而医生则提供AI所缺乏的现实情境与伦理判断。构建值得信赖、透明的界面,展示假设、允许临床医生调整优先级并邀请批判性审查,或可将这种人机视角的张力转化为更安全、更均衡的决策过程。
引用: Sengupta, D., Panda, S. Disagreement between human and AI evaluation of treatment plans. Sci Rep 16, 4798 (2026). https://doi.org/10.1038/s41598-026-35406-8
关键词: 临床决策支持, 医学中的人工智能, 人机协作, 治疗方案规划, 评估偏差