Clear Sky Science · zh
基于EMD分解高频与低频本征模函数的PM2.5浓度混合预测模型
更准确的空气预报为何关系到日常生活
空气中的细颗粒物,称为PM2.5,微小到可以深入肺部甚至进入血液。在以重工业和冬季取暖集中著称的华北,这类颗粒常常达到会触发健康警报、扰乱交通、甚至导致工厂和学校停工的水平。本研究提出了一个非常务实的问题:能否更准确地逐小时预测PM2.5水平,让城市管理者和居民在空气变得有害之前,获得更早、更可靠的预警?
近观华北的污染面貌
研究人员聚焦华北六个主要城市:北京、天津、石家庄、太原、济南和郑州。这些城市代表了人口密集、工业化程度高且冬季污染事件频繁的区域。研究团队使用官方监测数据,收集了2021全年每小时的PM2.5观测值,为每个城市获得了8,760个数据点。他们发现各地污染水平差异显著;例如,太原的PM2.5平均值最高,而北京相对最低。极端事件尤为显著:在一次三月的沙尘与污染复合事件中,太原的浓度曾飙升至652微克/立方米,使空气质量指数达到最高档,清楚地表明空气严重污染。
为何PM2.5难以预测
PM2.5受多重因素共同驱动——来自交通和工厂的局地排放、尘埃与烟雾的区域传输、风速、湿度等。因此,污染记录不像平滑曲线,更多表现为参差不齐、起伏不定的“心跳”。传统的统计工具甚至现代的神经网络在处理这类数据时常常吃力:它们可能能捕捉总体趋势,但错过突发的激增;或者在某个城市效果良好,却难以推广到其他城市。以往研究要么通过加入更多物理细节(如化学输送模型)来改进预报,要么完全依赖复杂的机器学习方法。本文则将多种方法结合起来,各自处理数据中的不同“节奏”。
将信号拆成快节奏与慢节奏
关键步骤是经验模态分解(EMD),它将原始PM2.5时间序列分解为若干更简单的成分。其中一些成分振荡迅速,捕捉短期尖峰与噪声;另一些则变化缓慢,反映潜在趋势。作者将前五个分量归为“高频”部分,剩余分量及残余趋势归为“低频”部分。高频成分更不规则且强非线性,被输入长短期记忆网络(LSTM)——一种擅长学习时间模式的深度学习模型。较为平滑的低频成分则交由经典时间序列方法ARIMA处理,该方法在数据呈较规则、近线性行为时更为有效。
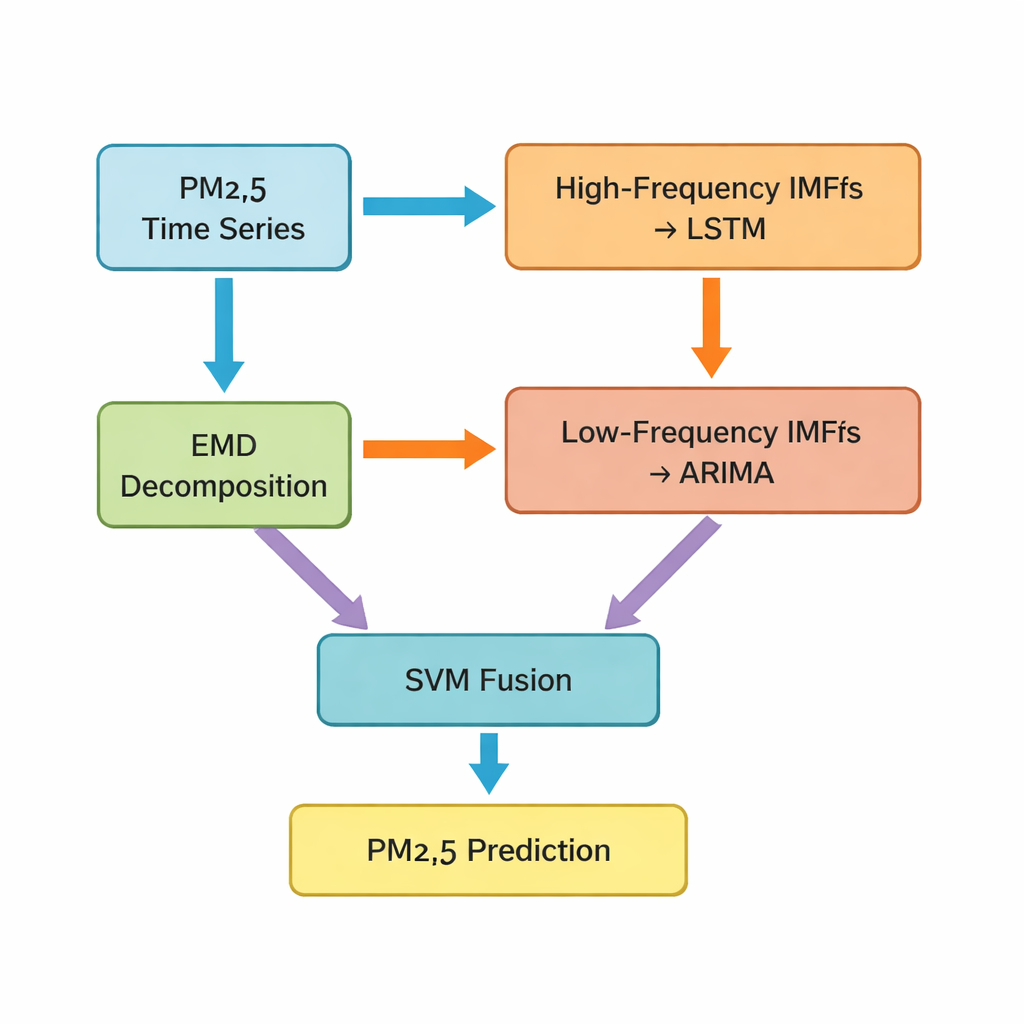
将不同模型融合为更智能的预报
在LSTM和ARIMA各自生成部分预测之后,研究仍面临一个挑战:如何将这些独立预测合并为下小时PM2.5的最终最佳估计?为此,作者使用支持向量机(SVM),另一种机器学习方法,用以学习如何加权并组合两类输入。本质上,SVM像一名裁判,决定何时应更依赖“快”视角(高频模式),何时应让“慢”视角(长期趋势)占主导。作者将该组合系统命名为Hybrid‑EMDHL,并用若干性能指标评估其表现,包括平均误差、预测与观测值的贴近程度,以及模型对变化方向(上升或下降)的判断能力。
更清晰的预警与更好的应对规划
混合模型在六个城市中均优于其任一单独组成部分。它不仅降低了平均误差和均方误差,还大幅提升了对下小时PM2.5上升或下降的预测能力——这是发布及时健康预警的关键属性。在许多情况下,与单一神经网络模型相比,混合方法把误差指标削减超过一半,其“方向准确率”超过0.69,意味着在远超过三分之二的测试案例中能正确预测趋势。对普通公众而言,这意味着类似天气预报的空气质量预报将更清晰、更可靠。对城市规划者和卫生主管部门而言,它提供了一个实用工具,支持在污染峰值到来前采取有针对性的早期行动——例如调整工业运行或交通管控——有助于减少暴露,保护中国一些污染最严重城市区域的日常生活。
引用: Wang, P., Wu, Q. & Zhang, G. A hybrid prediction model for PM2.5 concentration based on high-frequency and low-frequency IMFs with EMD decomposition. Sci Rep 16, 4969 (2026). https://doi.org/10.1038/s41598-026-35386-9
关键词: PM2.5 预测, 空气污染, 华北, 机器学习, 时间序列分解