Clear Sky Science · zh
一种基于深度强化学习的舞蹈动作分析方法
教会计算机像我们一样观看舞蹈
从芭蕾到街舞,舞蹈充满了节奏和姿态上微妙的转变,人眼能瞬间捕捉——但计算机却难以察觉。本研究提出了一种新的方式,让人工智能更像人类专家那样“观看”舞蹈视频:快速略过常规动作,聚焦于定义各类风格的短暂且具有辨识性的瞬间。结果是一个在观看更少视频的同时更准确识别舞蹈类型的系统,这对数字档案、体育和娱乐技术等领域都有潜在提升。
为什么舞蹈视频对机器很难
乍看之下,训练计算机识别舞蹈风格似乎很简单:输入视频,让深度学习去发现模式。实际上,大多数现有系统在浪费资源。标准视频模型要么处理每一帧,要么以固定间隔抽取片段,假设每一时刻同等重要。但舞蹈风格往往体现在细微处——脚如何转动、伴舞何时转身、旋转的时机——而非持续的动作。因此许多帧是重复或无信息的,而关键姿势可能落在固定采样点之外,导致例如华尔兹与狐步之间的混淆。
一种更聪明的浏览视频的方式
研究者提出了一个名为基于强化的注意时序采样(Reinforcement-based Attentive Temporal Sampling,简称 RATS)的框架,将视频分析视为主动搜索而非被动观看。系统不再逐帧前进,而是将舞蹈视频切成短片段,并先用专门的三维卷积网络将每个片段转换为对运动的紧凑描述。这些运动摘要被存入记忆。在此之上,一个决策代理在片段序列中步进,选择小跳、长跳或停止并给出风格预测。实际上,系统学会了如何在时间上浏览,停留在有信息的模式上,跳过无用的片段。
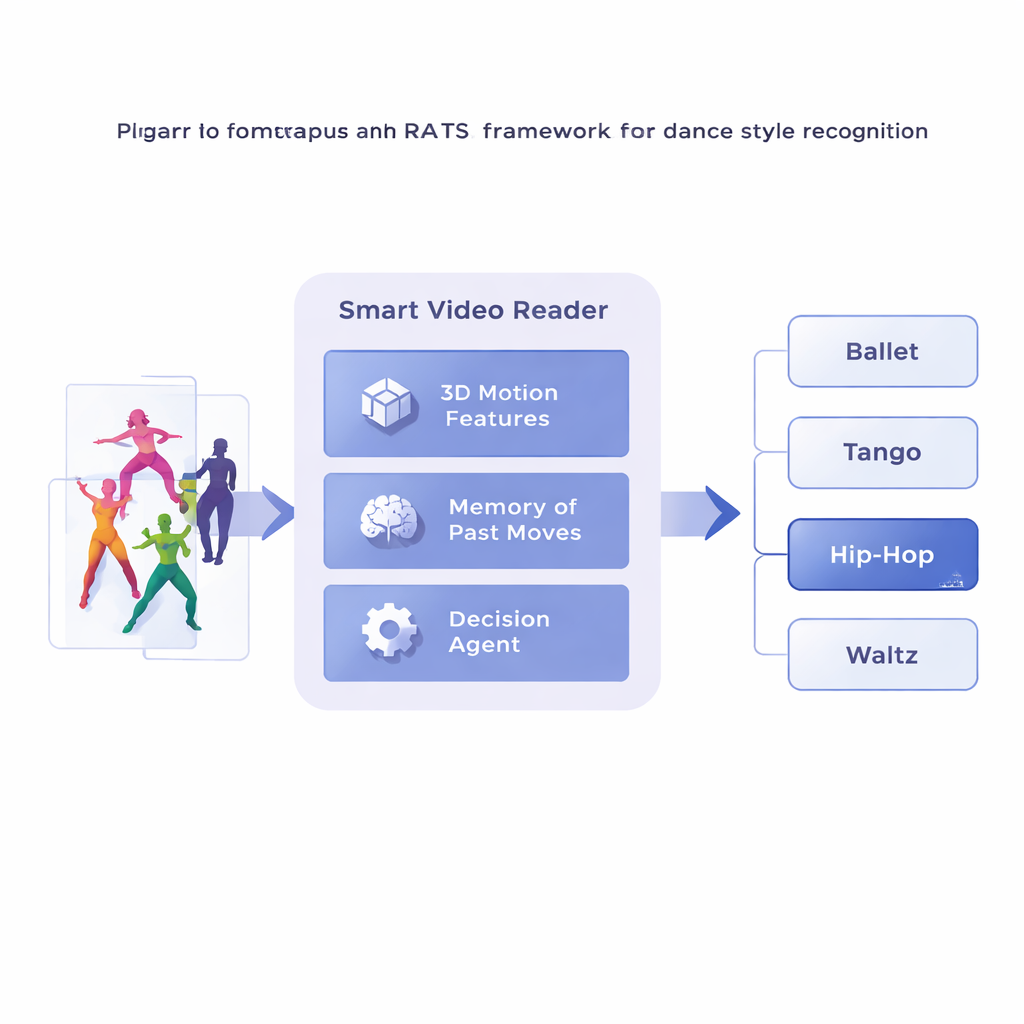
学会何时观看、何时做决定
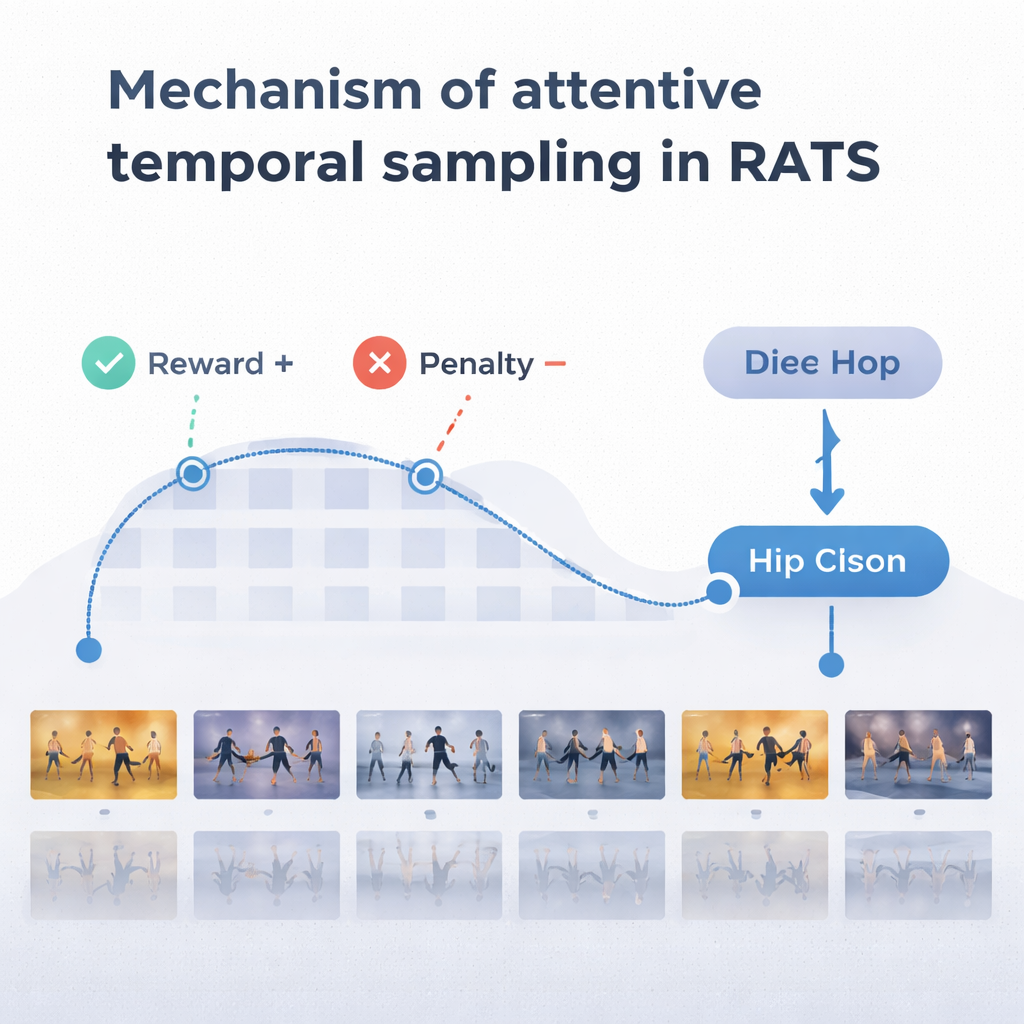
为做出合理选择,代理依赖一种受我们回忆既往与当前运动方式启发的记忆机制。一个双向递归网络跟踪系统已经“看过”的内容以及当前片段与历史的关联。在每一步,代理在三种选项间权衡:进行短跳以检查诸如脚步等细微细节,作较长跃以跨过重复动作,或停止并分类舞蹈。系统通过奖励与惩罚进行训练:正确决策获得高额正奖励,错误决策获得高额负奖励,每次向前跳跃会有小额惩罚。这种平衡促使代理既要准确又要高效——在拥有足够证据时再作决定,但不在整个视频中徘徊。
优于传统舞蹈分类器
团队在 Let’s Dance 数据集上测试了 RATS,该数据集包含 1,000 个视频,覆盖从弗拉门戈、探戈到摇摆舞和方舞的十种风格。与若干现有方法(包括标准深度网络和其他面向舞蹈的模型)相比,RATS 达到了最高的准确率——约 92%——以及最佳的精确率与召回率综合表现。统计检验表明其优于强有力的竞争对手,而非仅因偶然差异。重要的是,系统在平均仅分析约 38% 视频帧的情况下实现了这些结果。均匀地每隔若干帧采样虽然更快,但会错过关键时刻并降低性能;处理每一帧更慢,且仍不如这种有针对性的方式准确。
这对舞池之外意味着什么
对非专业读者而言,核心信息很直白:当计算机学会选择性观看时,它们可以做得更好。通过教 AI 集中于时间上的“黄金瞬间”,这项工作表明机器可以在使用更少资源的同时,更准确地识别人类复杂动作。尽管研究聚焦于舞蹈,同样的理念可帮助系统在体育动作、安全监控或任何重要事件短促且分散的长视频中挑出关键要素。换言之,更聪明的观看——而不是更多的观看——可能是视频理解的未来。
引用: Yin, P., Li, X. A deep reinforcement learning approach to dance movement analysis. Sci Rep 16, 5541 (2026). https://doi.org/10.1038/s41598-026-35311-0
关键词: 舞蹈识别, 视频分析, 深度学习, 强化学习, 人体动作