Clear Sky Science · zh
通过融合地理语义特征的中文空间关系抽取模型
教计算机理解地点之间的位置关系
我们每天都用简单短语描述位置:一个城镇位于河流以南,一个公园靠近一所大学,一条高速穿越某省。把这种日常语言转成精确的数字化知识,对智能地图、导航应用和地理研究至关重要。本文提出了一种新方法,称为 PURE‑CHS‑Attn,帮助计算机更准确地阅读中文文本并自动识别地点之间的空间关系。
为什么空间语言重要
空间关系是告诉我们地点在空间上如何连接的词语和短语,例如“在内部”“邻近”“在北方”“相距30公里”等。它们在我们脑中建立起现实地图与概念之间的桥梁。在地理信息系统(GIS)中,这些关系支撑着数据的组织、检索与分析。它们在其他领域也很关键:例如结合卫星影像、视频运动跟踪、工业布局规划,或研究气候与地形如何影响生物多样性。由于大量信息以自然语言书写,具备能阅读文本并自动抽取空间关系的可靠工具变得越来越重要。
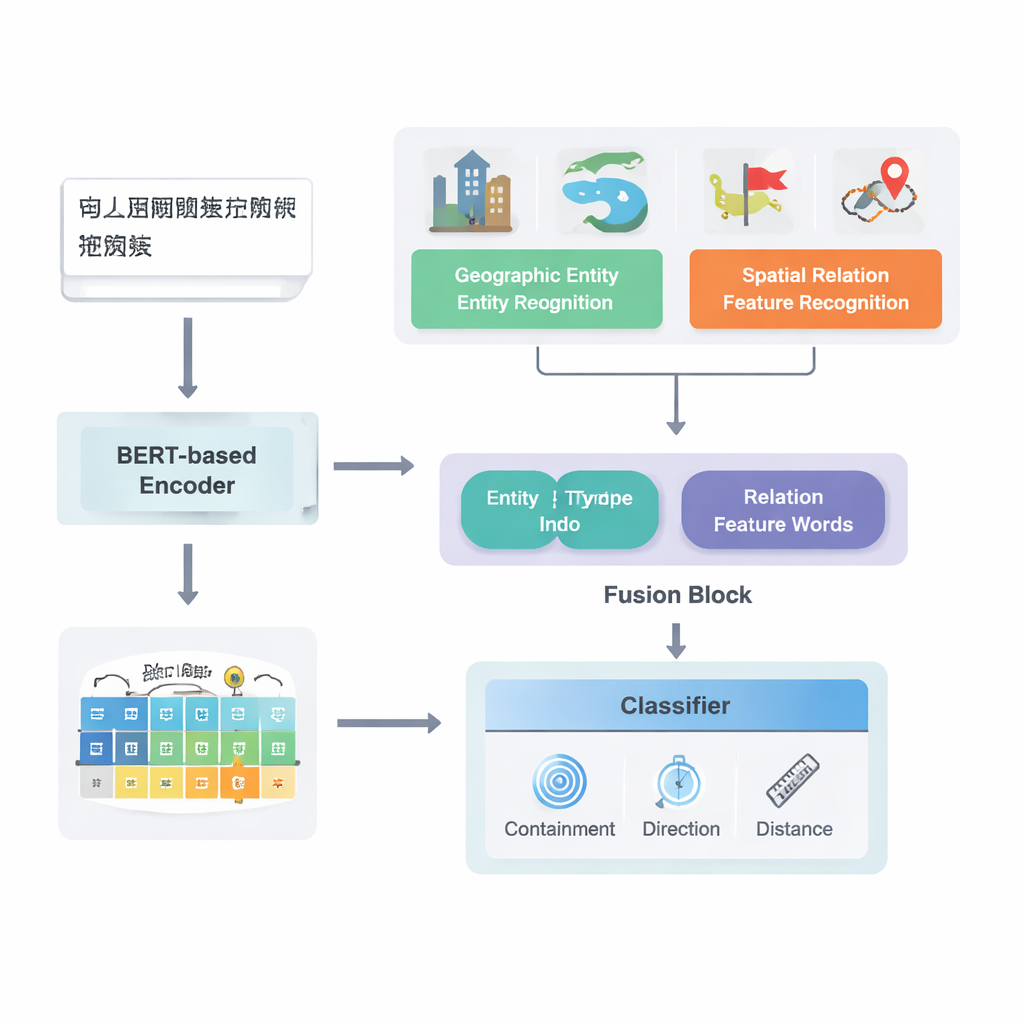
从原始文本到映射关系
作者把关注点放在中文文本上,基于已有的强大深度学习管线模型 PURE 进行扩展。他们的增强模型 PURE‑CHS‑Attn 分若干阶段工作。首先扫描句子以识别地理实体,如山脉、河流、城市和行政区,并为每个实体标注类型(例如陆地、河湖、水体、公共设施、历史遗址或行政区划)。接着检测表明两个地点关系的空间关系“特征词”,如“接壤”“流经”“以南”“靠近”等。一种强大的语言模型 BERT‑wwm‑ext 将句子中的字符转成捕捉其含义与上下文的数值向量。这些向量被送入独立组件,分别识别实体和关系词,然后将结果传递给融合模块。
把人类知识与机器学习结合起来
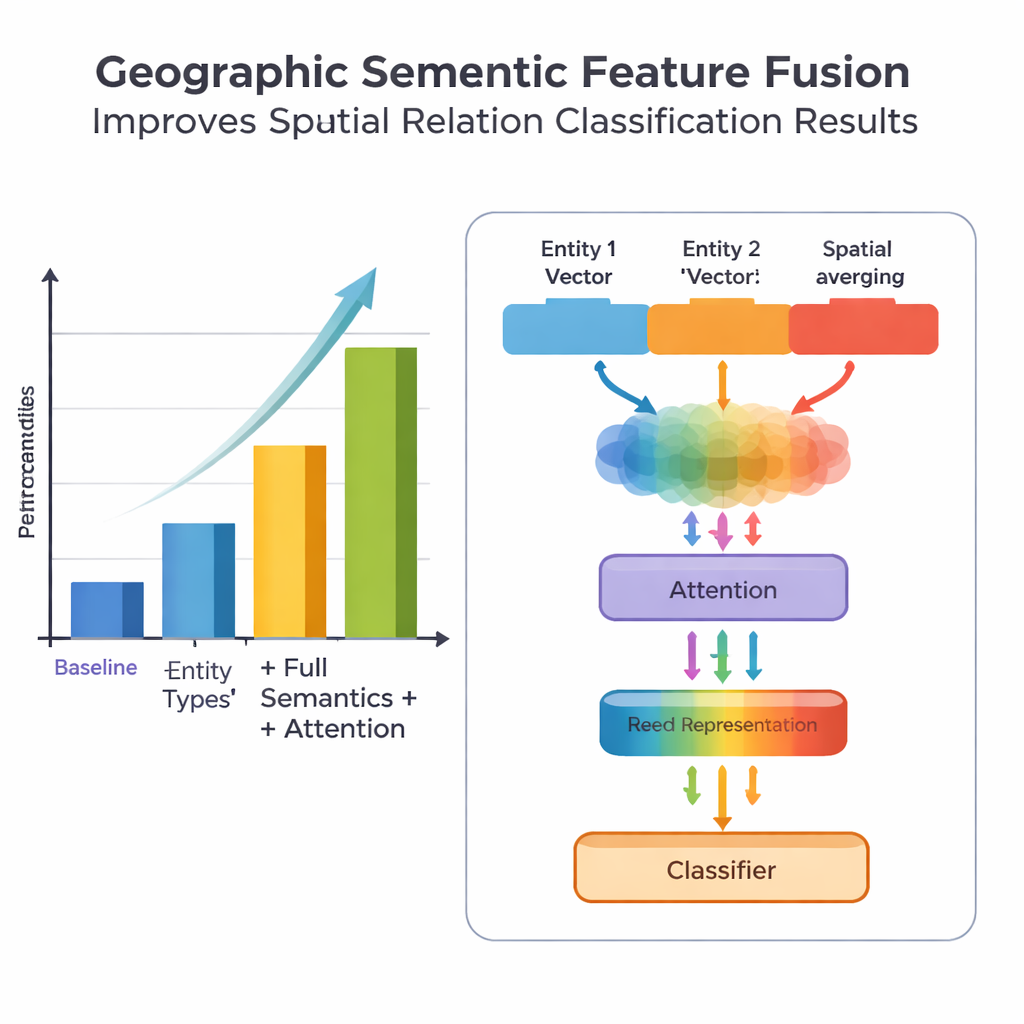
该工作的一个关键新意在于如何将地理知识与学习到的文本模式融合。模型不再把每个词同等对待,而是利用两类人类自然使用的语义信息:地理实体的类型以及连接它们的具体空间特征词。融合模块首先根据不同类型地点(例如两个行政区与一条河流与一个县)在不同关系类型中出现的频率来加权,合并两个实体的向量。然后将空间特征词的向量融合进来。在此“基础融合”之上,作者加入了注意力机制,使模型动态聚焦于实体—词组合中最有信息量的部分。最终的融合表示被送入分类器,可为句子中每对地点分配一个或多个关系类型——拓扑关系(如包含或邻接)、方向关系(北、南等)或基于距离的关系。
将模型付诸测试
为评估方法,团队从《中国大百科全书·中国地理》汇编并精细标注了数据集,包含1381句和368个空间关系对。他们比较了多个模型版本:仅使用粗糙位置信息的基线、加入更细实体类型的版本、再加入空间特征词的版本,以及他们具有新融合与注意力设计的完整 PURE‑CHS‑Attn 模型。按照精确率、召回率和 F1 分数等标准指标,PURE‑CHS‑Attn 相较基线在精确率上提升约7%,召回率提升约6.5%,F1 提升约6.7%。模型在识别拓扑和方向关系方面表现尤其强,并且在处理少样本(few‑shot)关系类型时优于更简单的模型。与三种近期最先进系统(包括基于大型语言模型的一种)比较时,PURE‑CHS‑Attn 名列第二,但更轻量、部署更容易。
挑战与未来方向
尽管取得这些进展,模型在距离关系上仍存在困难,尤其当训练样本很少时。作者指出他们的数据集中此类情况很少,这限制了任何数据需求高的方法的学习能力。他们还注意到,盲目对句子中大量空间特征词取平均可能引入噪声,注意力机制虽有缓解但并不能完全解决。展望未来,他们建议两条有前景的路径:通过数据增强扩展和均衡训练数据,以及将其地理语义融合方法与大型语言模型和基于提示的学习技术结合,以在数据稀缺场景中进一步提升性能,同时保持系统高效。
这对日常制图意味着什么
简单来说,这项研究通过关注提到的地点类型以及关系表达的具体措辞,教计算机更像人类那样阅读中文的空间描述。PURE‑CHS‑Attn 表明,将结构化地理知识与现代深度学习结合,可以更准确、更稳健地从文本中抽取“谁相对于什么在何处”。这为更智能、更自动化的 GIS 系统、更丰富的地理知识图谱以及更好的工具打开了道路,帮助在科学、政策和日常交流中更好地探索空间的表述方式。
引用: Ye, P., Wang, Y., Jiang, Y. et al. Chinese spatial relation extraction model by integrating geographic semantic features. Sci Rep 16, 5537 (2026). https://doi.org/10.1038/s41598-026-35282-2
关键词: 空间关系抽取, 地理空间人工智能, 地理语义, 中文文本挖掘, GIS 自动化