Clear Sky Science · zh
使用轻量级变压器高效检测 AI 生成的科学摘要
识别 AI 撰写的科学作品为何重要
随着人工智能写作能力的提升,它现在能够起草出与人类作品几乎无法区分的科学摘要。这带来了严肃的问题:期刊、大学和读者如何确认一篇研究摘要是真正反映科学家的工作,而不是机器的虚构?本文通过构建一个快速、紧凑的工具来解决这一问题,该工具能够以很高的可靠性标记出 AI 撰写的科学摘要,为维护学术诚信提供了一种可行的防线。
构建真实与合成摘要的测试库
为衡量和改进 AI 文本检测,作者首先需要可信的数据。他们从在线预印本服务器 arXiv 收集了 5,000 篇科学摘要,涵盖五个领域:计算机视觉、信号处理、定量生物学、物理学以及其他计算机科学主题。对于每一篇人类撰写的摘要,他们使用大型语言模型根据论文标题生成了对应的 AI 版本,仔细检查近重复文本并去除明显线索(如网址或代码片段)。他们还确保 AI 与人类文本在长度上相似,使检测器不能简单依赖诸如词数等粗糙统计量。
为真实场景调优的紧凑模型
研究者没有使用庞大且昂贵的模型,而是选择了较小的系统 DistilBERT,这是一个流行语言模型的精简版本。他们对其进行微调,使其能够判断每篇摘要是由人写还是由 AI 生成。该模型最多读取 256 个标记——大约几段文字——并输出介于 0 与 1 之间的分数,解释为文本由机器撰写的概率。训练与评估遵循严格协议:数据被划分为训练、验证与测试集且互不重叠,团队报告的不仅是准确率,还有在保持极低误报率时模型的表现,这在指控真实作者使用 AI 时尤为重要。
检测器的表现如何
在来自计算机视觉的摘要(主要测试集)上,检测器表现出色。它正确标记了 500 篇 AI 文本中的 499 篇,以及 500 篇人类文本中的 495 篇,整体准确率约为 99.4%,在标准性能曲线上几乎达到完美。当作者将系统的错误指控率限制为每一百例最多一次时,它仍能检测出约 90% 的 AI 文本;在允许每一百例出现五次误报的稍高容忍度下,它检测率约为 97%。与一系列替代方法相比——包括更简单的统计工具和其他变压器模型——该紧凑检测器在更苛刻的场景中尤其表现最佳。
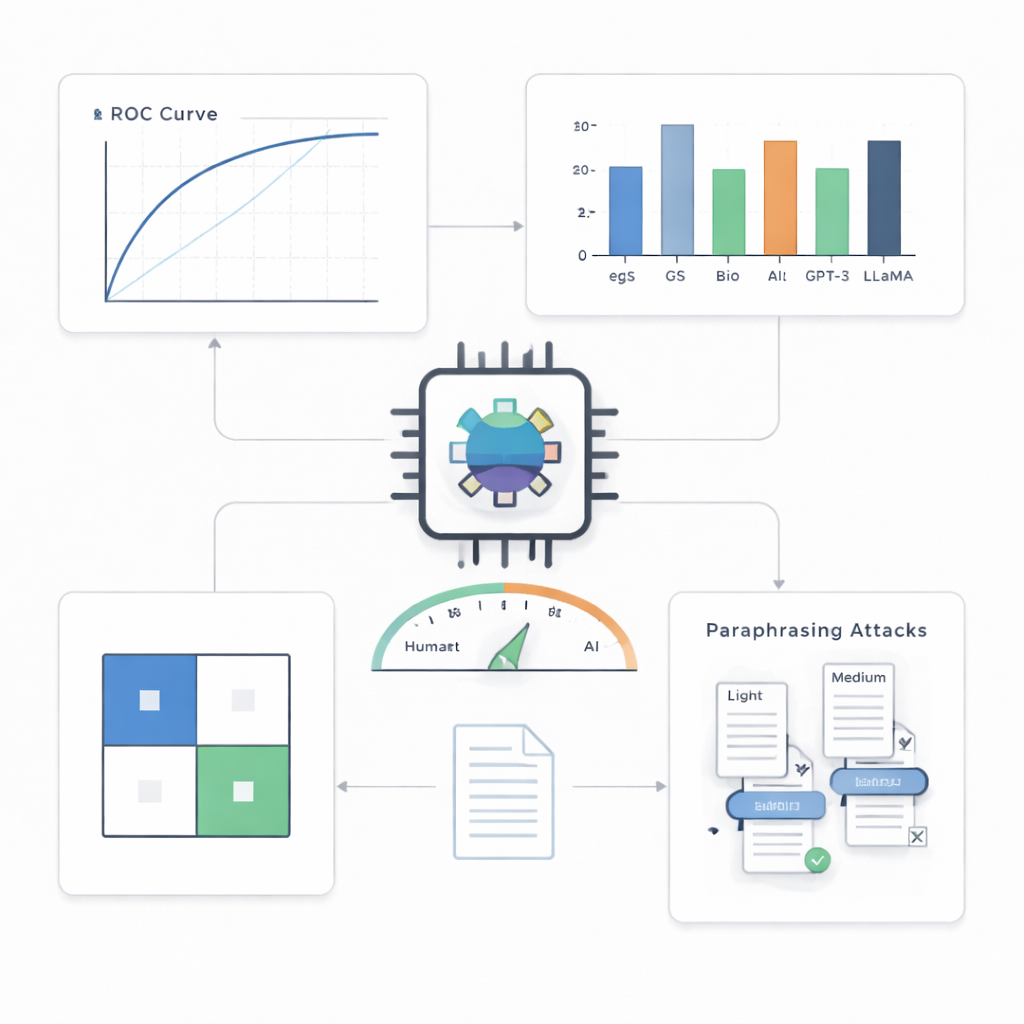
超越单一领域、单一模型与简单技巧
一个关键问题是,这样的检测器能否应对其未见过的写作风格和 AI 系统。作者在其他科学领域的摘要以及由若干不同先进语言模型撰写的文本上测试了该检测器。跨领域表现仍然稳健,仅有适度下降,表明该系统捕捉到的是 AI 写作的普遍模式,而非某一学科的特殊性。针对未见过的 AI 模型,它也能良好运行,尽管比在本域环境中稍逊。最具挑战性的攻击来自意译:当另一台 AI 将机器生成的摘要改写以在保持含义的同时听起来不同,检测难度明显上升。在中等强度的改写下,漏检的 AI 文本比例接近 30%,表明即便是复杂的检测器也能被有意混淆的手段欺骗。
这对科学及其保障措施意味着什么
研究表明,目前 AI 撰写的科学摘要仍留下微妙的痕迹,设计良好的模型可以捕捉到这些痕迹,即便该模型小到能在普通硬件上运行。这使出版商、会议和大学在不耗费巨大计算资源的情况下筛查大量投稿成为可行。然而,对意译攻击的脆弱性也强调了此类工具并非万能。作者主张应将 AI 文本检测与其他保障措施结合——例如编辑判断、查重检测和透明度要求——以在 AI 系统持续进步的同时保护科学交流的可信性。
引用: Zhang, C., Zhou, W. Efficient detection of AI-generated scientific abstracts with a lightweight transformer. Sci Rep 16, 4975 (2026). https://doi.org/10.1038/s41598-026-35203-3
关键词: AI 文本检测, 科学摘要, 学术诚信, 大型语言模型, 机器生成文本