Clear Sky Science · zh
在间歇性需求预测中,特征工程优先于架构复杂性
为什么预测罕见销售很重要
在每一家汽车修理厂或零件仓库背后,都有一个安静的难题:货架上应该备多少滞销备件?这些物品很少且不可预测地出售,但在车辆出现故障时必须可用。订购过多会导致资金被闷在积灰的库存中;订购过少则让客户在零件紧急调入时等待。本文通过一个简单的问题来解决这一日常但代价高昂的问题:是使用越来越复杂的预测模型更好,还是为现有模型提供更聪明、精心设计的数据特征更有价值?
从长时间的无销售到突发性激增
在许多供应链中,尤其是汽车备件领域,需求不像牛奶或面包那样平稳。相反,存在长时间几个月的零销量,被偶尔几件的突发订单打断。作者分析了超过56,000个经销商—零件组合,约1.4百万条月度记录,发现大多数序列极其稀疏:平均而言,每发生一次销售伴随许多零销量月份,且订单量波动剧烈。诸如Croston方法及其改进等传统统计方法是为这种“开/关”式需求设计的,能给出稳定且可解释的预测,但它们把每个零件孤立对待,难以利用如价格或产品属性等额外信息。现代机器学习系统理论上可以利用所有这些信息,但当数据主要是零且只有偶尔有信息时,它们往往表现不佳。
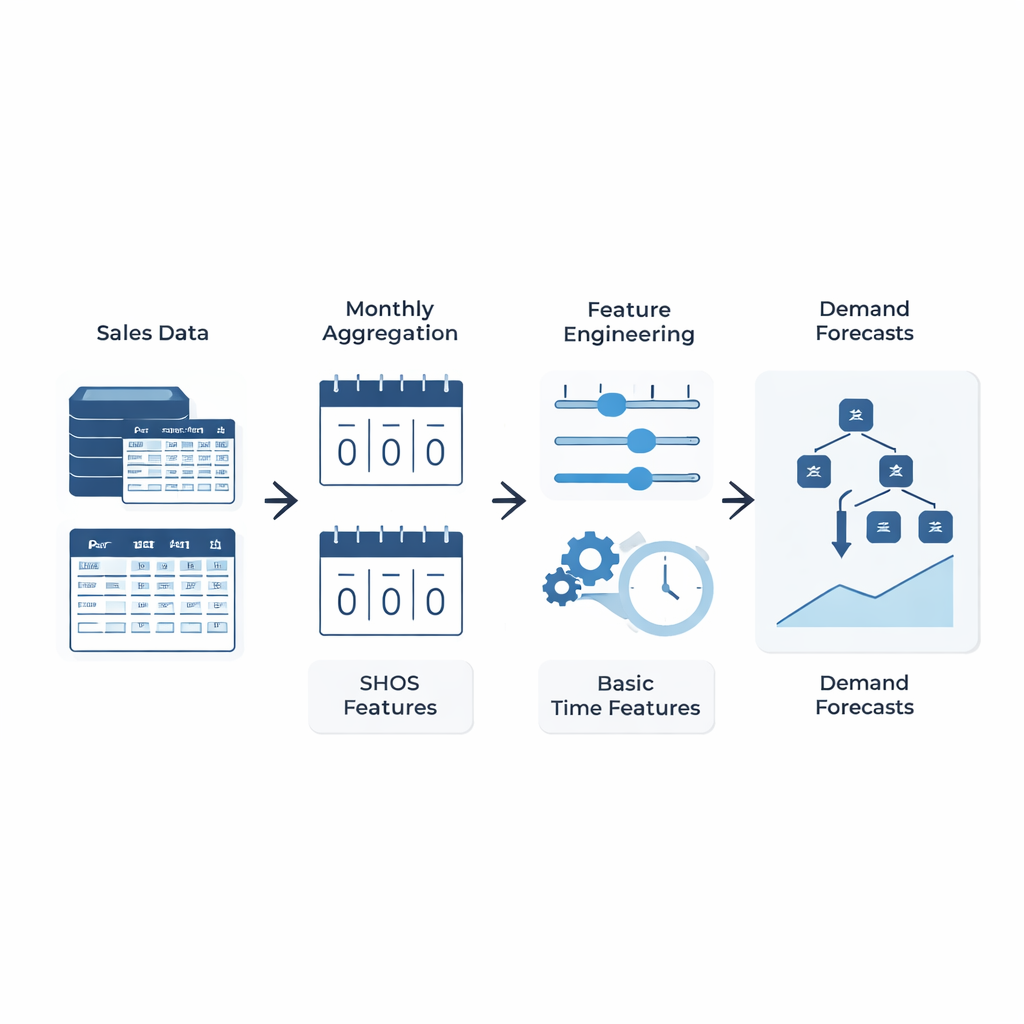
一个简单的思路:教模型什么才真正重要
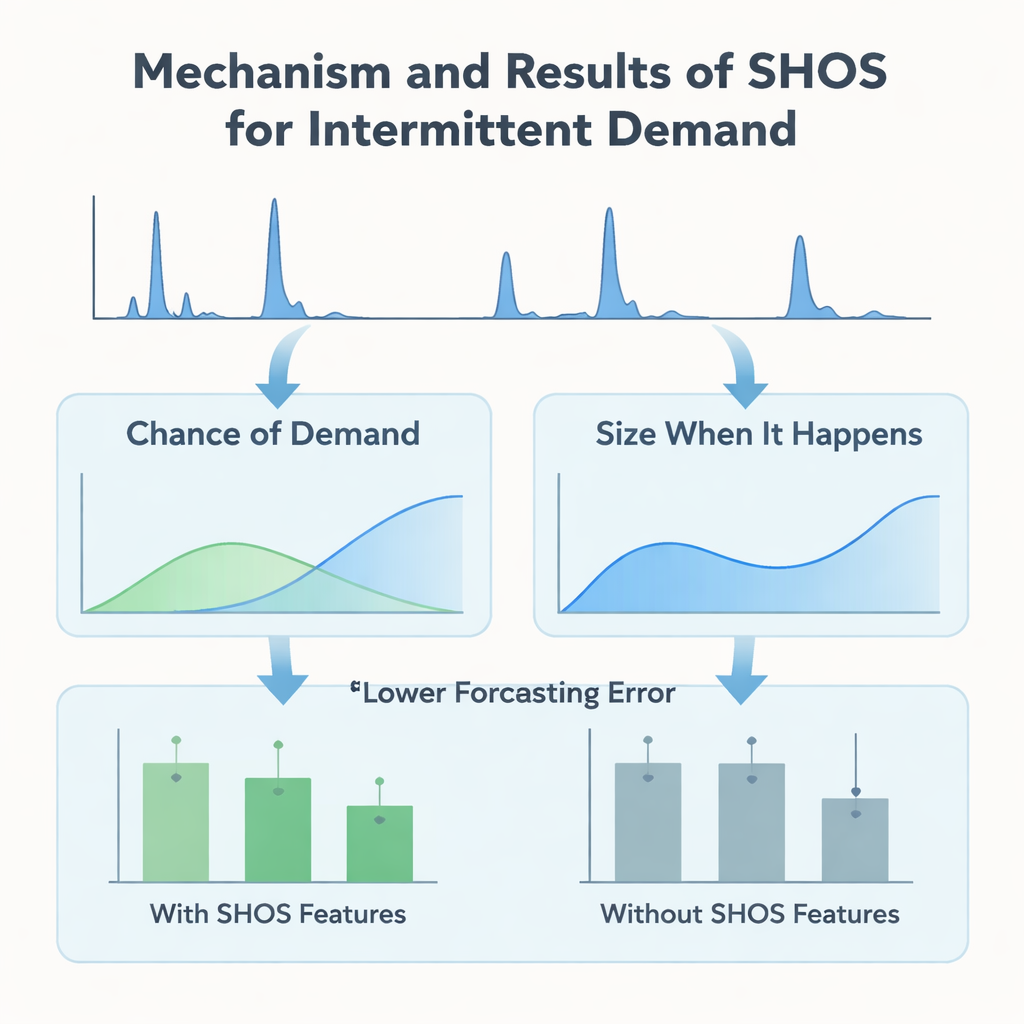
作者并未设计更复杂的机器学习架构,而是关注输入给模型的内容。他们提出了平滑混合发生—规模(Smoothed Hybrid Occurrence–Size,SHOS)框架,这是一种在每个需求历史上运行的轻量级统计例程。每个月,SHOS产生两个数:估计下个月发生任何需求的概率,以及如果发生需求时的典型规模。它通过对过去零值和非零值进行谨慎平滑来实现,在非常稀疏的序列上自适应,并在需求在长时间沉寂后突然回归时更迅速地反应。关键是,SHOS并不是最终的预测模型。其输出作为额外输入特征提供给常规机器学习算法,和诸如近期销售、滚动平均以及静态产品细节等简单项一起使用。
将特征质量置于模型复杂性之上
为了检验这种统计“预处理”是否真正有用,研究人员构建了受控实验。他们比较了一系列流行模型——梯度提升树、随机森林和线性方法——有无SHOS特征的表现,所有模型都在相同的以零填充的月度面板上训练,并使用模拟真实部署的严格滚动窗口方案进行评估。他们还测试了更复杂的两阶段“门槛(hurdle)”模型,这类模型分别预测是否会发生需求以及需求的大小。在11个验证窗口中,加入SHOS特征几乎将高度间歇性品类的平均预测误差减半,并将一个关键的业务度量(加权平均绝对百分比误差)降低了超过40%。令人惊讶的是,尽管两阶段架构更复杂并针对这类数据进行了定制,但它们并未优于一个简单的单一回归器——后者仅仅输入SHOS信号即可达到甚至超过复杂流水线的表现。
看清模型如何做出选择
研究团队不仅关注总体准确性,还探究了模型实际如何利用所给信息。使用SHAP这一标准的机器学习解释工具,他们展示了基于SHOS的特征——“需求发生的概率”和“发生时的规模”——在影响力输入中始终名列前茅。在长期零需求期间,较低的SHOS概率将预测值推向零,从而防止虚假的库存积累;当干旱期后出现需求爆发时,SHOS中的近期性调整会迅速提高概率和规模估计,使模型能够响应而不过度反应于单次峰值。这些行为在简单的单阶段模型和更复杂的门槛版本中都能观察到,强调了主要收益来自信号质量而非架构技巧。
这对日常库存决策意味着什么
对于试图把合适的零件放在货架上的从业者来说,这一结论既务实又令人放心。研究表明,精心设计、统计上有依据的特征可以在不依赖脆弱且难以维护的模型设置的情况下,大幅改善对罕见、不规则销售的预测。配备SHOS特征的经过良好调参的中等规模梯度提升树,能够击败或匹敌更复杂的流水线,同时在数万件物品上更易于部署和监控。简单来说,为你的预测系统提供有关客户下单频率和下单量的更好汇总,比升级到最新、最复杂的算法往往更重要。这种强调简单且可解释构件的方法对大规模、现实世界的供应链具有吸引力,并表明在其他面临间歇性需求的行业中,类似以特征为中心的策略也可能带来回报。
引用: Nathan, B.S., Aravinth, P.M., Reddy, B.V.S. et al. Primacy of feature engineering over architectural complexity for intermittent demand forecasting. Sci Rep 16, 4792 (2026). https://doi.org/10.1038/s41598-026-35197-y
关键词: 间歇性需求, 备件预测, 特征工程, 供应链分析, 机器学习