Clear Sky Science · zh
基于EULAR指南对ChatGPT-4o和Gemini在痛风管理中的评估:比较分析
为何智能聊天机器人与疼痛关节重要
痛风是一种常常累及大脚趾的剧烈关节炎,全球发病率正在上升。医生已有明确且以证据为基础的诊断和治疗指南,但许多患者仍未得到最佳护理。与此同时,像ChatGPT-4o和Gemini这样的强大人工智能聊天机器人开始进入临床场景,带来一个简单却关键的问题:这些工具是否能提供安全且符合指南的痛风建议,还是可能误导医生和患者?
检验聊天机器人遵循规则的情况
研究者旨在将两款领先的语言模型——ChatGPT-4o与Gemini 2.0 Flash——与欧洲官方(EULAR)痛风指南进行对照。两名专家将指南中的25条关键建议转化为临床医生风格的问题,涵盖现实世界中的关键问题:如何诊断痛风、何时开始降尿酸治疗、如何处理急性发作、血液检测的目标值以及生活方式或其他药物应如何调整。两款聊天机器人在独立且干净的会话中被分别提问,确保先前答案不会影响随后的回答。
答案评分方式
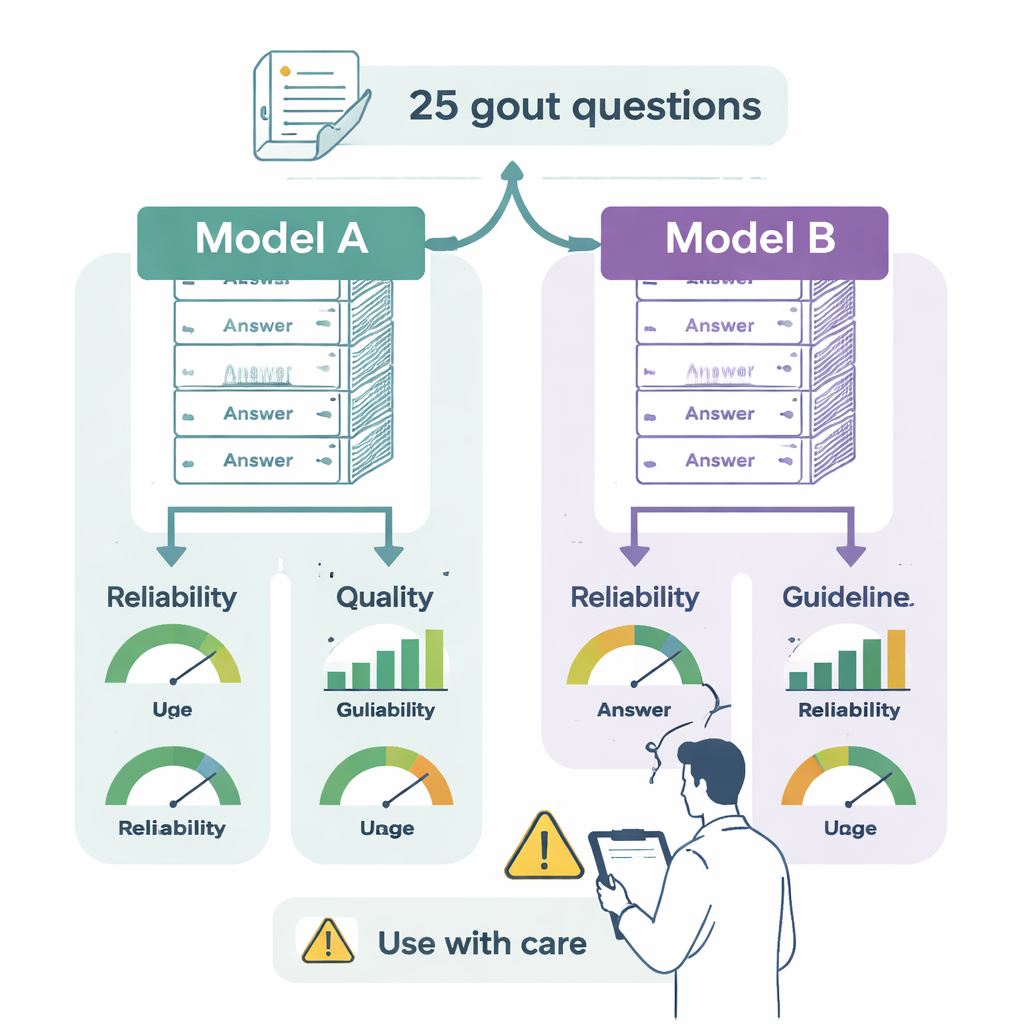
每个答案由两位有经验的痛风临床医生评分,评审者对模型来源不知情。评分包括三个方面。首先,可靠性:回答是否平衡、客观且可信,或是否遗漏关键事实或夸大益处?其次,质量:答案是否清晰、组织良好,并对做决策的专科医生有用?第三,与指南的一致性:回答是否完全符合EULAR建议、在部分内容上正确但不完整,或直接与指南相悖?团队还使用标准可读性测试评估答案的阅读难度,以估算理解该文本所需的教育程度。
ChatGPT与Gemini:谁表现更好?
两款聊天机器人给出的答案总体上都是合乎常理且书写清晰,并且常提醒读者咨询医疗专业人员。但重要差异显现出来。ChatGPT-4o在76%的案例中与痛风指南完全一致,另有20%为大体正确但不完整的回答,仅有一处明确的医疗错误。Gemini在48%的回答中完全符合指南,32%为部分正确但不完整。更令人担忧的是,12%的回答将正确观点与错误信息混合,8%的回答则直截了当地与指南相悖——例如,在EULAR仅建议用于难治性个例的情况下,建议广泛使用一类强效抗炎药(IL-1抑制剂),或在急性发作期间常规启动降尿酸药物,而专家对此类情况通常更为谨慎。
可读,但不易读懂
在风格上,两种系统令人惊讶地相似。在多种阅读量表上,两者生成的文本在理解上至少需要大学水平的教育程度。这对专科医生可能可以接受,但对大多数患者来说过于复杂。除非被特别要求,模型通常不会给出参考文献或来源链接,这使得核实信息来源变得困难。评审者之间的一致性被评为良好到优秀,这表明评分具有一致性,聊天机器人之间的差异是真实存在的,而非评审者主观意见所致。
这对痛风患者意味着什么
总体而言,研究表明先进的聊天机器人可以成为医生管理痛风时的有益辅助,但尚不足以独立承担诊疗责任。ChatGPT-4o在可靠性、完整性和对专家指南的忠实度方面优于Gemini,尽管即便是它的罕见错误在涉及用药与安全时也可能产生影响。两款工具的表述对大多数患者而言过于复杂,且缺乏内置的来源透明性。目前,作者认为应将人工智能视为有前景的辅助工具,可帮助临床医生和教育者,但其建议必须与最新指南和专家判断核对,尤其在像痛风这样的疾病中,剂量细节和时机决策会显著影响疼痛、长期损伤与生活质量。
引用: Meral, H.B., Kolak, E. Evaluation of ChatGPT-4o and Gemini for gout management: a comparative analysis based on EULAR guidelines. Sci Rep 16, 4831 (2026). https://doi.org/10.1038/s41598-026-35166-5
关键词: 痛风, 临床指南, 人工智能, 大型语言模型, 风湿病学