Clear Sky Science · zh
用于从佩戴式摄像头和常规图像识别施工现场未佩戴个人防护装备的域自适应 faster R-CNN
为何安全防护缺失仍然被忽视
安全帽、背心、口罩、手套和耐用鞋在施工现场本应是不可妥协的要求,但疏忽仍然发生——而后果可能致命。许多项目现在依赖摄像头和人工智能来标记未佩戴必要装备的工人,但这些系统面临困难,因为真正的违规行为很少且难以被拍到。该研究探索了一种通过借用普通街拍中的样本来训练更智能检测系统的方法,使自动安全检查在无需等待事故或违规积累的情况下变得更可靠。
将日常照片变成安全教材
核心思想很简单:公共场所或办公室的人通常不会穿戴施工防护装备,因此这些场景的照片充满了“工作现场不该穿”的示例。挑战在于这些场景与真实施工现场外观差别很大——背景、光照和相机角度都会改变人物的呈现方式。作者将这两类世界视为不同的“域”:一个是来自常规图像、拥有丰富非防护装备示例的源域,另一个是拥有较少但更真实的施工现场图像的目标域,很多图像来自工人头盔上安装的摄像头。论文表明,通过谨慎对齐计算机从两个域中学到的内容,系统可以比仅用施工数据训练时更准确地在真实工地上识别缺失的防护装备。
新型安全检测器如何“看”场景
该研究基于一种流行的目标检测系统 Faster R‑CNN,该系统扫描图像,提出可能包含人物或肢体的区域,然后对每个框内的内容进行分类。此处检测器被训练以识别五类缺失防护:未戴安全帽、未戴口罩、未戴手套、未穿背心和未穿安全鞋。在把图像输入模型之前,会对图像进行大量增强——调亮或调暗、旋转、模糊和扭曲——以模拟施工现场常见的抖动摄像、强烈阳光和尴尬角度。这种合成的多样性有助于模型在真实世界视频画质欠佳时保持稳定,尤其是当画面来自佩戴式摄像头时常见的情况。
教系统忽略背景干扰
简单地将街拍与施工镜头混合并不足以解决问题;模型可能会学会把缺少防护装备与城市人行道联系起来,而不是与人本身关联。为防止这种情况,研究引入了“域自适应”模块,旨在让系统更多关注人物和服装而非周围场景。其中一个模块关注整张图像,推动网络使施工与非施工照片在整体特征上趋于相似,尽管光照或设备不同。另一个模块在每个检测到的人级别工作,确保例如未受保护的头部在脚手架上或在购物街出现时具有相似的视觉特征。这些模块以对抗方式训练:一个小型分类器试图区分图像来自哪个域,而主网络则学习隐藏该域信息,将注意力保持在防护装备上。
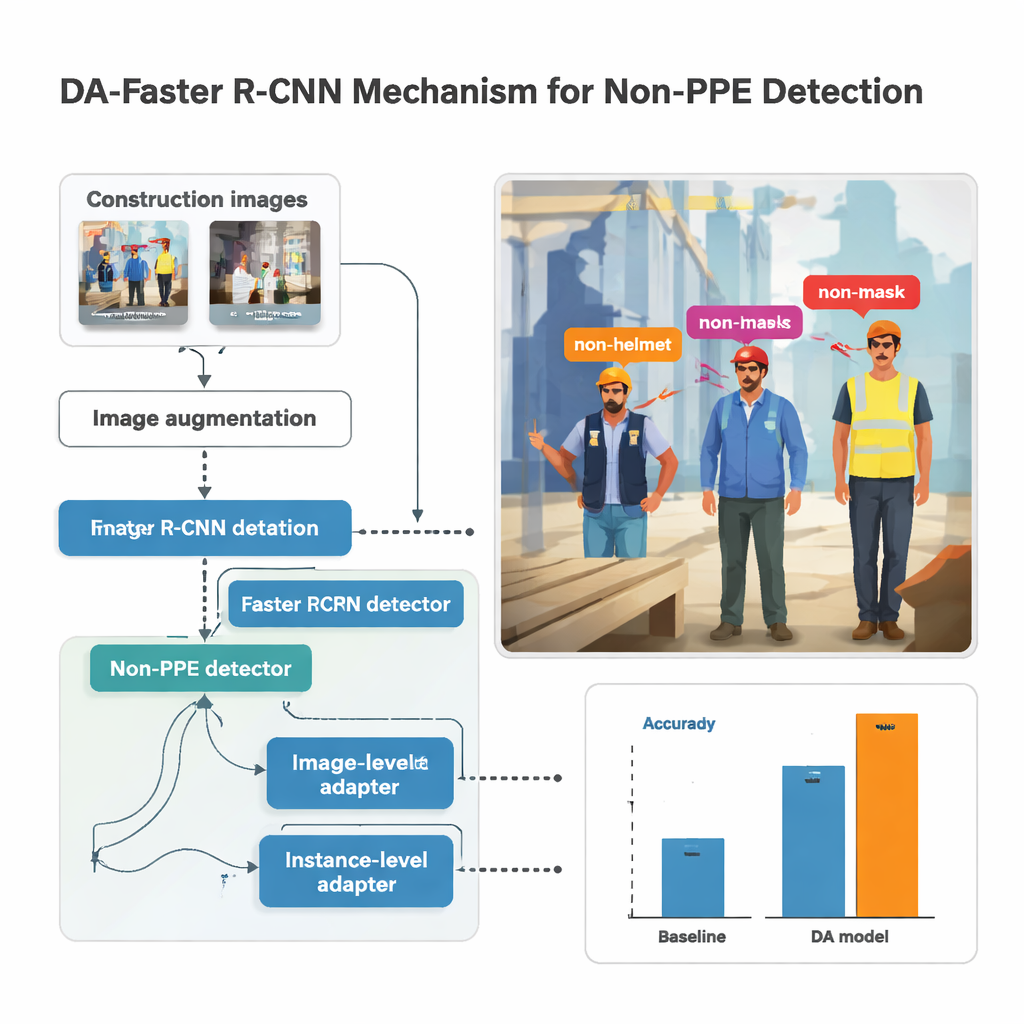
方法验证
作者通过将来自韩国五个施工现场的佩戴式摄像头素材与若干公开图像集合结合,组建了一个可观的数据集。对每一例缺失的安全帽、口罩、手套、背心和安全鞋进行了人工标注后,研究训练了数百个在不同神经网络骨干和参数设定下的模型。表现最佳的模型采用了名为 ResNet‑152 的深度网络,配合强烈的图像增强和域自适应模块。在先前未见过的施工图像上,该配置实现了约 86.8% 的平均精度(mean Average Precision),同时以约 33 帧每秒的速度运行,足以接近实时监控。与更传统的监督系统相比,经适应的模型提高了最多约 14 个百分点的准确率,相较于更简单的基线方法则提高了多达 39 个百分点。
这对更安全工地意味着什么
对非专业读者来说,结论是:更聪明的训练方法,而不仅仅是更大的数据集,能够使自动化安全监控更可靠。通过同时从日常照片和真实工地学习,并教系统忽略不重要的背景细节,所提出的方法能够高可靠地识别缺失的安全帽、背心、手套、口罩和安全鞋,即便真实违规样本稀少。尽管当前工作聚焦于五类装备和一个主要的施工数据集,但它为未来可覆盖安全带、绳索及其他防护设备并适用于多个工地的系统提供了实用蓝图,帮助监督人员及早发现问题、提高工人安全,而不必整天盯着视频屏幕。
引用: Wang, S. Domain-adaptive faster R-CNN for non-PPE identification on construction sites from body-worn and general images. Sci Rep 16, 4793 (2026). https://doi.org/10.1038/s41598-026-35148-7
关键词: 施工安全, 个人防护装备, 计算机视觉, 域自适应, 目标检测