Clear Sky Science · zh
针对结肠组织病理学的紧凑深度学习模型:关注性能与泛化挑战
这项研究对患者和医生为何重要
结肠癌是全球最致命的癌症之一,但其诊断仍依赖病理专家仔细检查显微镜下的组织图像,这既耗时又容易产生分歧。本研究探索了非常小且高效的人工智能(AI)模型是否能在日常临床中——包括计算资源受限的环境——足够准确地标记结肠癌组织。同时研究揭示了一个隐性弱点:在开发阶段看似近乎完美的模型,仍可能在新的真实世界数据上严重失灵。
教计算机“读”显微镜图像
在进行结肠活检时,病理学家会在显微镜下检查薄而染色的组织切片。癌变组织表现为腺体畸形、细胞形态不规则并向周围结构侵入,而健康组织则呈现有序、规则的模式。作者使用了一个公开的数据集,包含约24,000张此类数字图像,癌变(结肠腺癌)与良性组织数量相当。他们将所有图像调整到统一的小尺寸,并应用了真实感的变换——小角度旋转、翻转、缩放和适度的颜色变化——以模拟切片、染色和扫描过程中的自然变异。这种精心的预处理帮助AI模型关注有意义的组织模式,而非诸如精确朝向或亮度等表面细节。
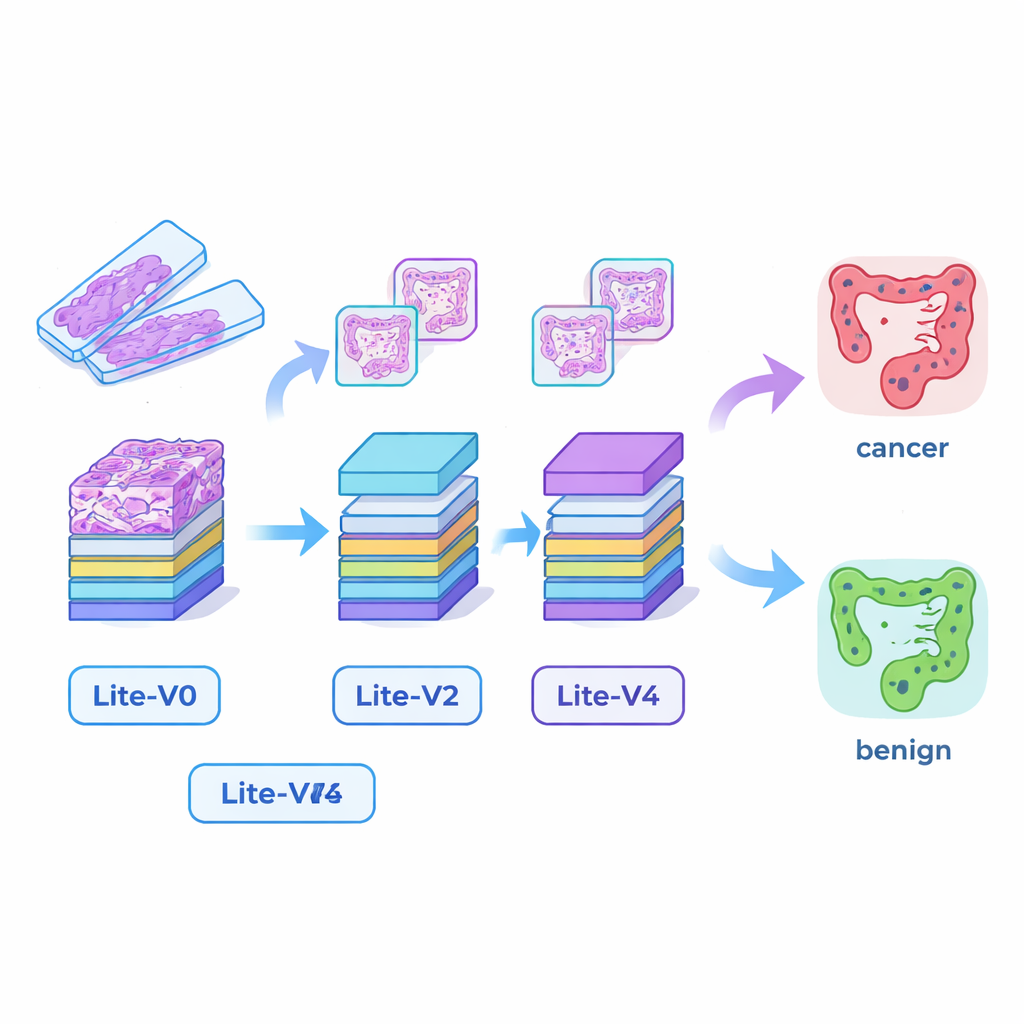
构建小巧但能干的AI“之眼”
许多成功的医疗AI系统依赖非常大的深度学习模型,这些模型需要强大的图形处理卡和大量内存,难以在小型医院或床边部署。为弥补这一差距,研究者设计了四个紧凑的卷积神经网络——Lite‑V0、Lite‑V1、Lite‑V2和Lite‑V4。每个模型都查看相同的输入图像块,但在层数和滤波器数量上有所不同,用以检测边缘、纹理和腺体形状等视觉特征。四个模型共享一种简单、透明的设计:重复的标准卷积、归一化和池化模块,之后是一个小型“决策头”,输出癌变或良性组织的概率。目标是评估在能够舒适运行于基础临床硬件上的模型中,能够挤出多少准确率。
实验室内的亮眼得分
研究团队在固定的数据划分上训练并比较了这四个模型,采用了广泛接受的衡量标准:准确率、对两类错误同等权重的宏F1得分、混淆矩阵以及ROC和精确率–召回率曲线等诊断图。中等规模的模型Lite‑V2表现最佳。尽管其模型文件约1.5兆字节且可训练参数约12.8万,Lite‑V2在内部验证集上几近完美,宏F1得分约为0.999,灵敏度和特异性接近完美。换言之,在这个精心准备的环境中,Lite‑V2几乎总能区分结肠癌变与良性组织,同时保持足够快且轻量,适合在较为普通的计算机上使用。
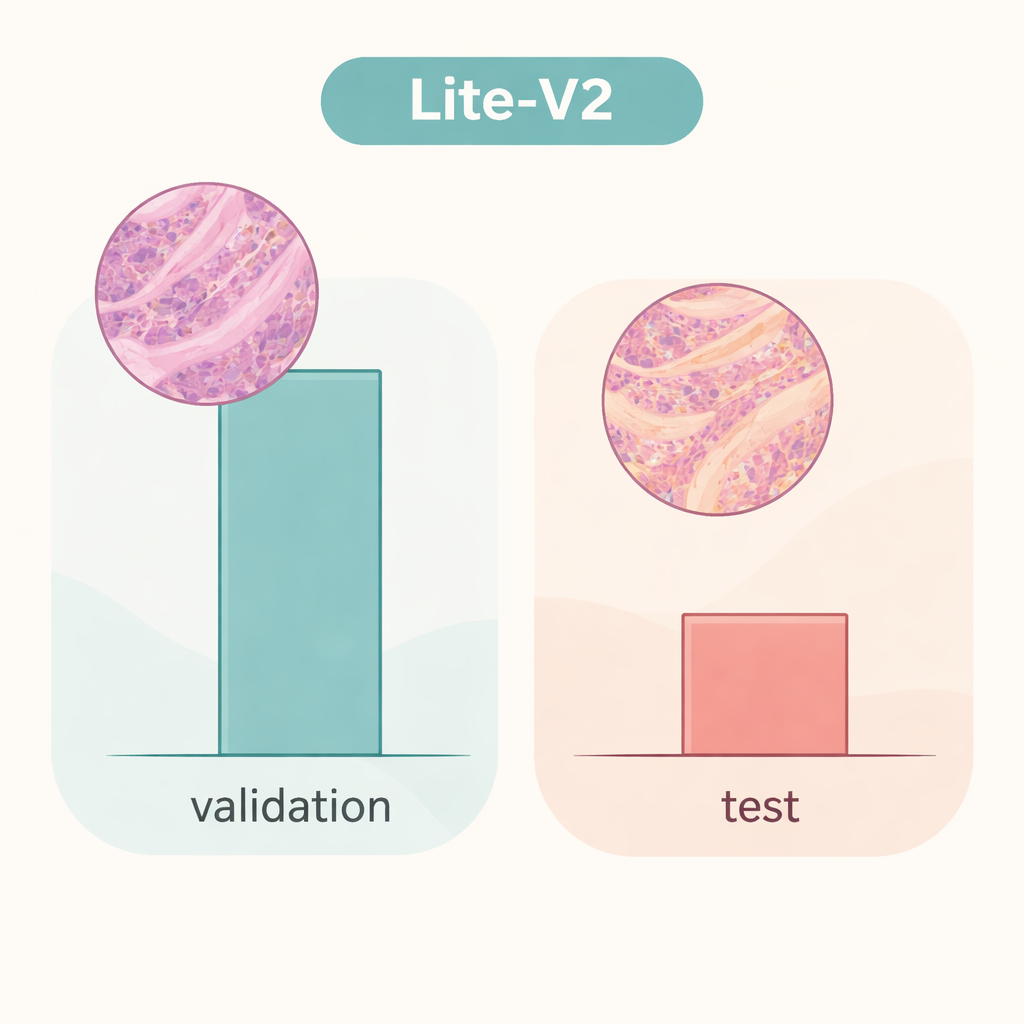
真实世界的变异打破幻象
然而,当在一组独立图像上测试同一Lite‑V2模型时,情况发生了戏剧性变化——这些图像在细微特征上与原数据不同,模拟来自另一实验室的切片,这就是研究者所说的“领域迁移”。在这个未见过的测试集上,整体准确率降至约50%,宏F1得分下降到约0.33。模型仍能识别许多癌变样本,但在良性组织上表现很差,错误地将大量良性样本标记为恶性。这表明网络学到的是与原始数据源紧密相关的细节——例如染色风格或扫描仪特性——而非对疾病具有稳健可迁移性的特征。该工作强调,如果模型未被真正不同的数据挑战,那么内部验证上的亮眼结果可能会带来虚假的安全感。
这对未来的AI诊断工具意味着什么
对一般读者而言,结论有两方面。第一,紧凑的AI系统确实可以在结肠组织图像上达到专家级的表现,同时保持小巧高效,便于广泛部署,这为更快速的筛查以及对压力巨大的病理学家提供支持打开了可能性。第二,同样重要的是,在本地数据集上看似“完美”的模型,遇到来自新医院的图像时可能大幅失效。作者认为,未来工作必须致力于提高这些轻量模型对染色、扫描设备和患者群体差异的鲁棒性——例如采用抗染色扰动的训练、领域自适应以及更广泛的多中心数据集。在此之前,AI应被视为一个有前景的辅助手段,而不是癌症诊断中的独立决策者。
引用: Hanif, F., Raza, A. & Mohammed, H.A. Compact deep learning models for colon histopathology focusing performance and generalization challenges. Sci Rep 16, 5489 (2026). https://doi.org/10.1038/s41598-026-35119-y
关键词: 结肠癌, 组织病理学, 深度学习, 轻量级卷积神经网络, 领域迁移