Clear Sky Science · zh
使用蛋白质大型语言模型与超图卷积网络预测根系相关蛋白
为什么根与其隐秘助手很重要
当我们考虑维持作物健康时,通常会想到叶片和果实。但植物的许多成功是在视线之外、土壤中发生的。在那里,特殊的根系相关蛋白帮助植物吸收水分和养分,并应对干旱或贫瘠土壤等胁迫。仅靠实验室实验去发现这些关键蛋白既缓慢又昂贵。本研究提出了一个强大的计算模型,称为 Hypergraph-Root,它可以快速扫描蛋白质序列并预测哪些蛋白可能与根系相关,为培育更耐逆的作物和提高产量提供了更快捷的途径。
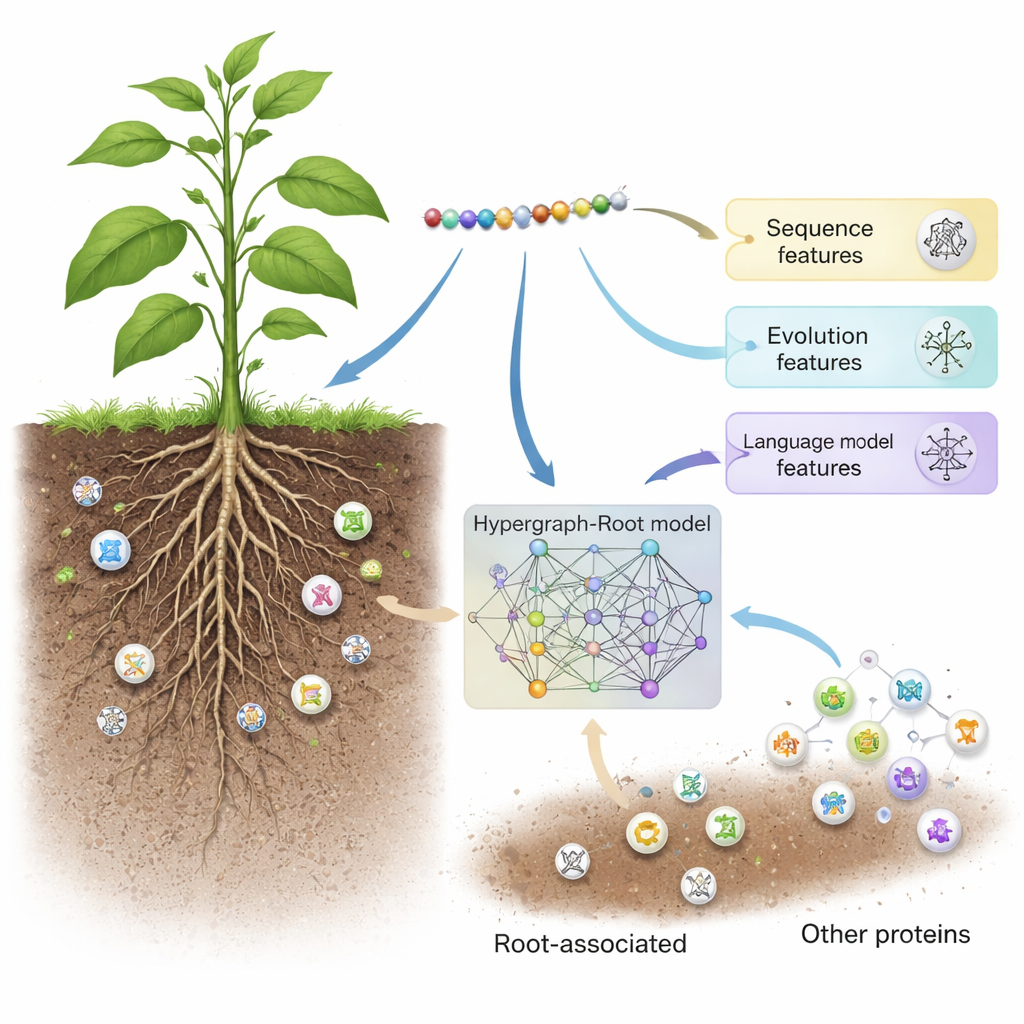
土壤中不显眼却劳作的主力
植物根系不仅仅是把植物固定在土壤中。根系不断感知周围环境、吸收矿物质,并与土壤微生物进行交流。根系相关蛋白在这些过程中起着核心作用,影响根的生长方式、对高温、干旱或养分缺乏的反应,以及与有益微生物的相互作用。由于这些蛋白强烈影响产量和抗逆性,农民和育种者非常重视它们,即便他们看不见这些蛋白。然而,许多此类蛋白仍未被发现,主要是因为传统方法——如蛋白质组学和基因表达研究——需要昂贵的仪器、复杂的分析和费时的实验。
把蛋白序列变成线索
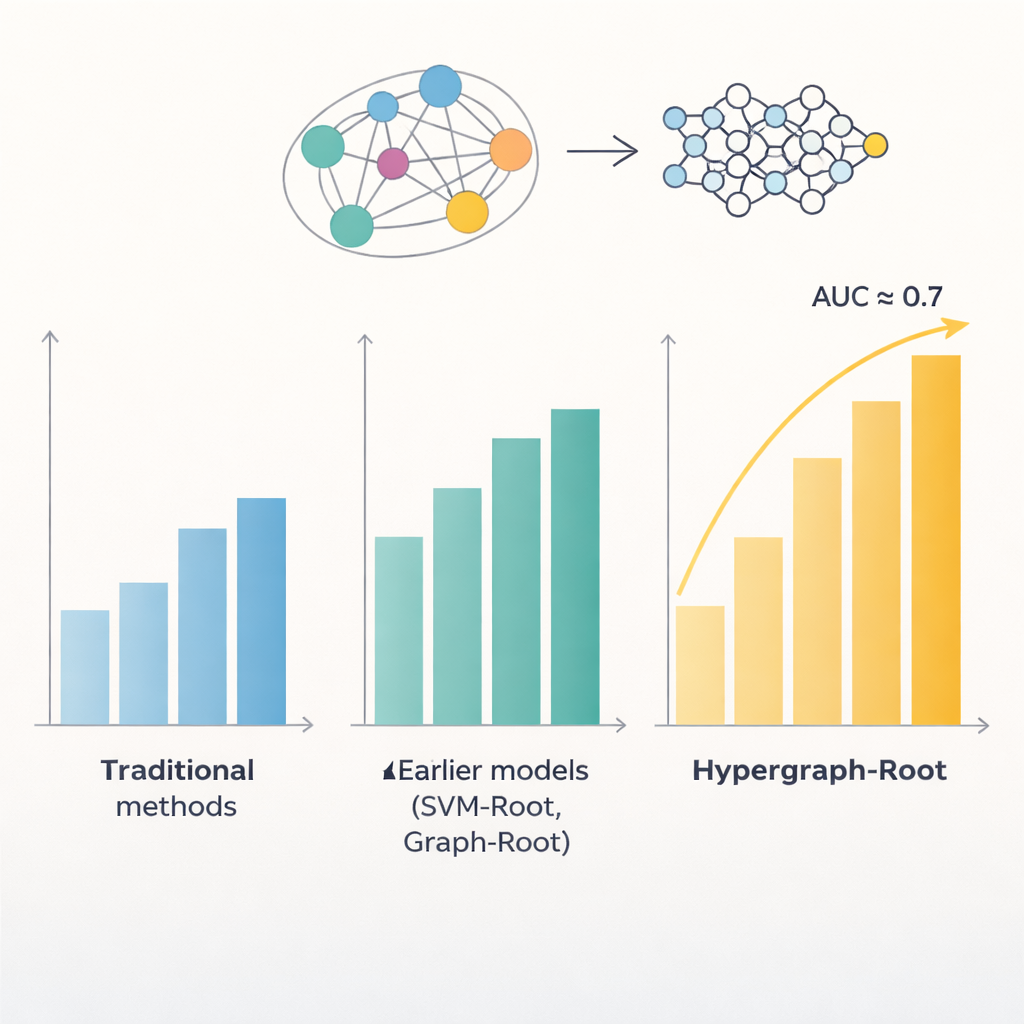
蛋白质由氨基酸序列构成,这些序列中的模式常常揭示蛋白在植物中工作的部位和功能。以往的计算模型试图利用这些模式来识别根系相关蛋白,但准确率通常低于80%。问题之一是它们以相对简单的方式处理氨基酸之间的关系,通常只考虑成对关系。另一个问题是它们依赖于从序列中提取的有限类型特征。作者认为,对每个蛋白进行更丰富的表示,并采用更智能的氨基酸关系建模方法,可以发现与根功能相关的更微妙模式。
借用语言与网络领域的技巧
Hypergraph-Root 首先用三种互补的方式描述每个蛋白。它使用传统的序列评分方案(BLOSUM62 和位点特异性评分矩阵),捕捉氨基酸在进化过程中如何相互替代的倾向。随后它加入第三种、更现代的描述:来自名为 ProtT5 的蛋白质语言模型的表征——该模型在数百万条蛋白序列上训练,类似于文本预测引擎在大量人类语言数据上训练的方式。ProtT5 为每个氨基酸生成丰富的数值“嵌入”,编码了结构和功能的线索。三种视角共同为研究中的每个蛋白提供了详尽的指纹式表示。
在蛋白内部映射复杂连接
为了超越简单的成对比较,研究者预测了氨基酸在蛋白三维结构中的接近程度,并用这些信息构建了超图——一种单个连接可以同时链接两个以上氨基酸的网络。一个专门的神经网络——超图卷积网络——处理这个具结构感知的网络,并将蛋白指纹细化为更高层次的特征。接着,多头注意力模块学习蛋白中哪些区域携带最有用的信号以判定其是否与根系相关。最后,一个标准分类器将这些提炼后的特征转换为概率评分:是否为根系相关。在多次训练以及平衡与不平衡测试集上,Hypergraph-Root 的准确率超过83%,ROC 曲线下面积(AUC)约为0.9,明显优于早期模型。
模型揭示了什么及其重要性
除了原始准确率外,该模型还提供了关于哪些信息最为重要的见解。来自 ProtT5 语言模型的特征贡献大于传统的序列和进化特征,这表明大型预训练模型能捕捉到旧方法难以察觉的微妙生物学信号。超图组件也被证明至关重要:移除它或用更简单的图模型替代都会降低性能。当研究者将 Hypergraph-Root 应用于先前未标注为根系相关的蛋白时,它挑出了若干候选者,其已知功能(例如膜运输和根中的蛋白标记)强烈暗示它们确实在根生物学中发挥作用。这些候选现在为实验生物学家提供了明确的短名单以在实验室中验证。
从智能预测走向更强壮的作物
用通俗的话说,Hypergraph-Root 就像植物生物学领域的资深图书管理员:仅凭蛋白的“字母”,它就能估计该蛋白是否可能在根中发挥作用。通过结合语言模型提供的洞见、进化历史以及复杂的结构关系,它在很大程度上改进了以往的预测工具。尽管它不能替代实验,但能够将数千种可能性缩小到可管理的少数,节省时间和经费。长期来看,此类模型可加速发现有助于作物在高温、干旱或贫瘠土壤中存活的根系相关蛋白——这是在不断变化的气候中实现更具韧性的农业的重要一步。
引用: Chen, L., Xun, X. & Zhou, B. Root-associated protein prediction using a protein large language model and hypergraph convolutional networks. Sci Rep 16, 4876 (2026). https://doi.org/10.1038/s41598-026-35110-7
关键词: 根系相关蛋白, 植物生物信息学, 深度学习, 蛋白质语言模型, 作物抗逆性