Clear Sky Science · zh
用于自动驾驶系统感知的多模态学习与仿真方法
更聪明的自动驾驶汽车
自动驾驶汽车承诺带来更安全的道路和更少的拥堵,但前提是它们能真正理解周围的世界。本文探讨了一种新方法,帮助自动驾驶车辆更像谨慎的人类驾驶员那样“看见”、“感知”和“预判”周围环境——通过融合不同传感器、在现实世界的虚拟副本中安全测试,并使汽车的决策对人类更加透明。
用多种“感官”看路
当今大多数驾驶辅助系统高度依赖摄像头,摄像头在光线良好时表现出色,但在雾天、雨天或夜间会遇到困难。本研究将三种不同类型的传感器——摄像头、激光扫描仪(LiDAR)和雷达——结合起来,使车辆不再依赖单一、脆弱的信息源。摄像头捕捉丰富的颜色和细节,LiDAR 构建场景的精确三维图像,雷达在恶劣天气下仍保持可靠。作者将这三路信息融合为对交通的单一视图,为车辆提供更全面、更可靠的道路、行人和其他车辆感知。
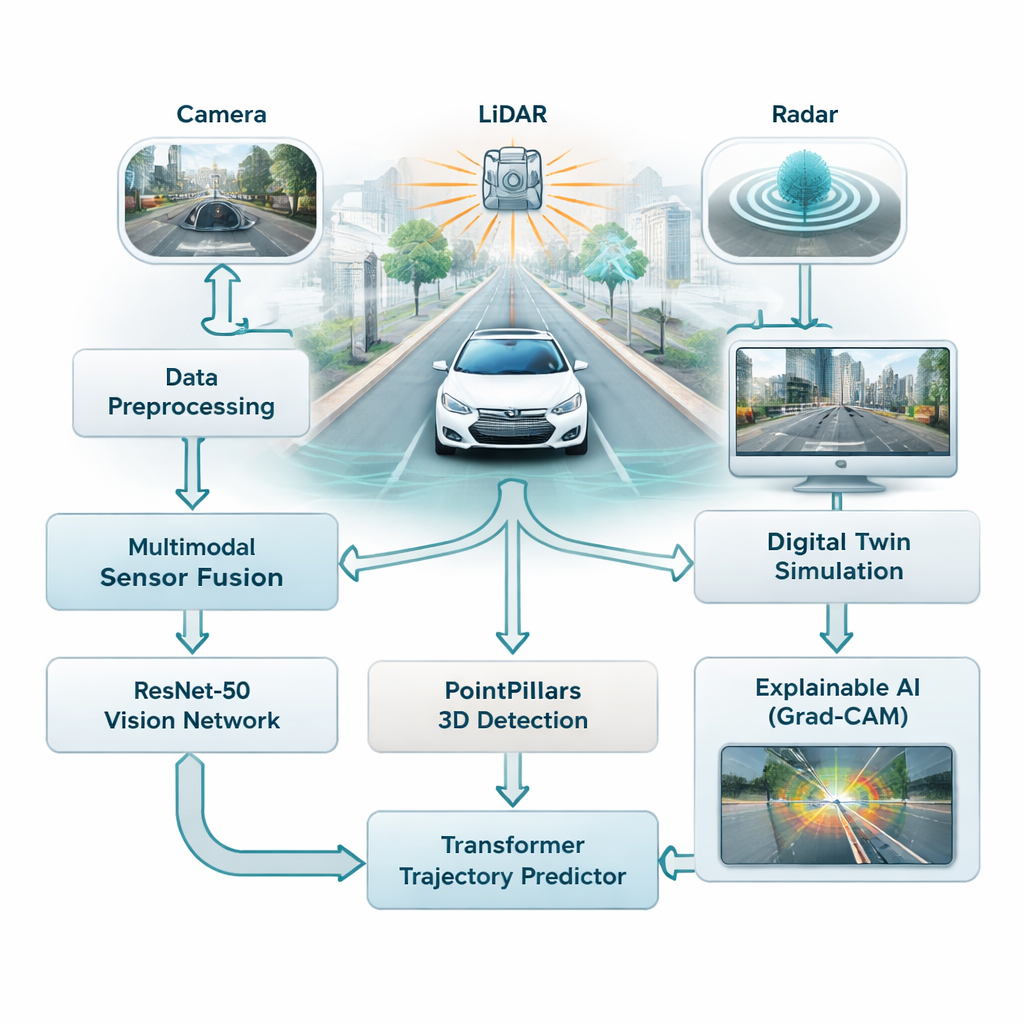
教汽车识别并预判
为了理解这大规模的数据流,该框架采用了两类现代人工智能模型。首先,一个名为 ResNet-50 的深度图像网络扫描摄像头图像以捕捉总体情况——道路的拥挤程度、车道的可见性以及场景布局。与此同时,一个名为 PointPillars 的三维模型读取 LiDAR 点云以在三维空间中定位车辆和其他物体。然后将这些信号输入到 Transformer 中——一种最初为语言设计、擅长理解事物随时间变化的 AI。在这里,它学习预测未来几秒内附近车辆和其他移动物体可能的运动,综合考虑其过去的运动和道路结构。
构建安全的虚拟测试场
研究人员并非直接在公共道路上测试高风险情形,而是将系统接入数字孪生——基于来自波士顿和新加坡的大型公共数据集构建的现实城市街道虚拟副本。在这个模拟世界中,汽车的传感器、运动和周围环境可以被回放并随意修改,同时 AI 尝试跟踪目标并预测其未来轨迹。该系统可以实时运行这些“假设”场景,响应时间低于 50 毫秒,使工程师能够探索诸如突然刹车、急转弯或拥挤路口等边缘情况,而不会危及任何人。
窥视 AI 的“黑箱”
对深度学习的常见批评之一是很难理解模型为何做出特定决定。为了解决这一点,作者使用了一种称为 Grad-CAM 的方法,该方法突出显示对模型输出影响最大的图像区域。这些热图显示,例如网络在估计轨迹时是否关注另一辆车、行人或车道标记。尽管此解释步骤是在离线环境下运行而非汽车的实时环节中进行,但它有助于工程师和安全审查人员验证系统是否关注正确的线索,这对建立公众信任至关重要。
它能开得好多少?
在数百个城市驾驶场景上的测试表明,所提出的框架在 3D 目标检测和运动预测方面都优于假设恒定速度或恒定加速度等简单物理规则。其预测误差——预测位置与真实位置的偏差——明显小于这些基线模型,且接近于一种强大的循环 AI 模型,同时运行速度仍足以满足实时使用。对不同网络设计的仔细实验表明,更深的图像模型与中等深度的 3D 检测器在准确性与速度之间取得了最佳平衡,并且该系统在模型压缩后可以部署到较小的车载计算机上。
这对普通司机意味着什么
对于非专业读者而言,结论是:更安全、更可靠的自动驾驶汽车很可能源于一种融合多种传感器、预测场景演变并在逼真的虚拟世界中充分测试的方法。通过将感知、预测、仿真和可被人类理解的解释结合为一体,这项工作使自动驾驶车辆更接近于在道路上表现得像谨慎、透明的伙伴,而不是神秘的机器。
引用: Almadhor, A., Al Hejaili, A., Alsubai, S. et al. A multimodal learning and simulation approach for perception in autonomous driving systems. Sci Rep 16, 5505 (2026). https://doi.org/10.1038/s41598-026-35095-3
关键词: 自动驾驶, 传感器融合, 轨迹预测, 3D 目标检测, 数字孪生仿真