Clear Sky Science · zh
一种用于英语翻译教育的混合智能评估模型:改进的BERT与SVM
为何更智能的翻译评分很重要
每年,语言教师在批改学生翻译上花费大量时间。判断一个句子是否“够好”既缓慢又主观,而且不同教师之间往往差异很大。本文探讨人工智能是否能够分担这部分工作——提供快速、一致的评分并指出可能的错误,而不是取代教师。文中提出了一种专为教育情境下英语翻译质量判定设计的新计算模型,称为 BERT-SVM EduScore。
从粗糙的词汇匹配到更深层的理解
几十年来,计算机评判翻译主要通过统计与参考答案相匹配的词或短语数量来完成。像 BLEU 或 METEOR 这类著名工具速度很快,但面对自然语言的灵活性时力不从心:两个句子可能用截然不同的措辞表达相同含义。在课堂中,学生常试验同义词和多样句式,这些传统指标可能不公平地惩罚有效的意译,并且难以对具体错误提供有用指导。因此,研究者转向了通过比较语义而不是表面词形的新方法,利用在海量文本上训练的强大语言模型。
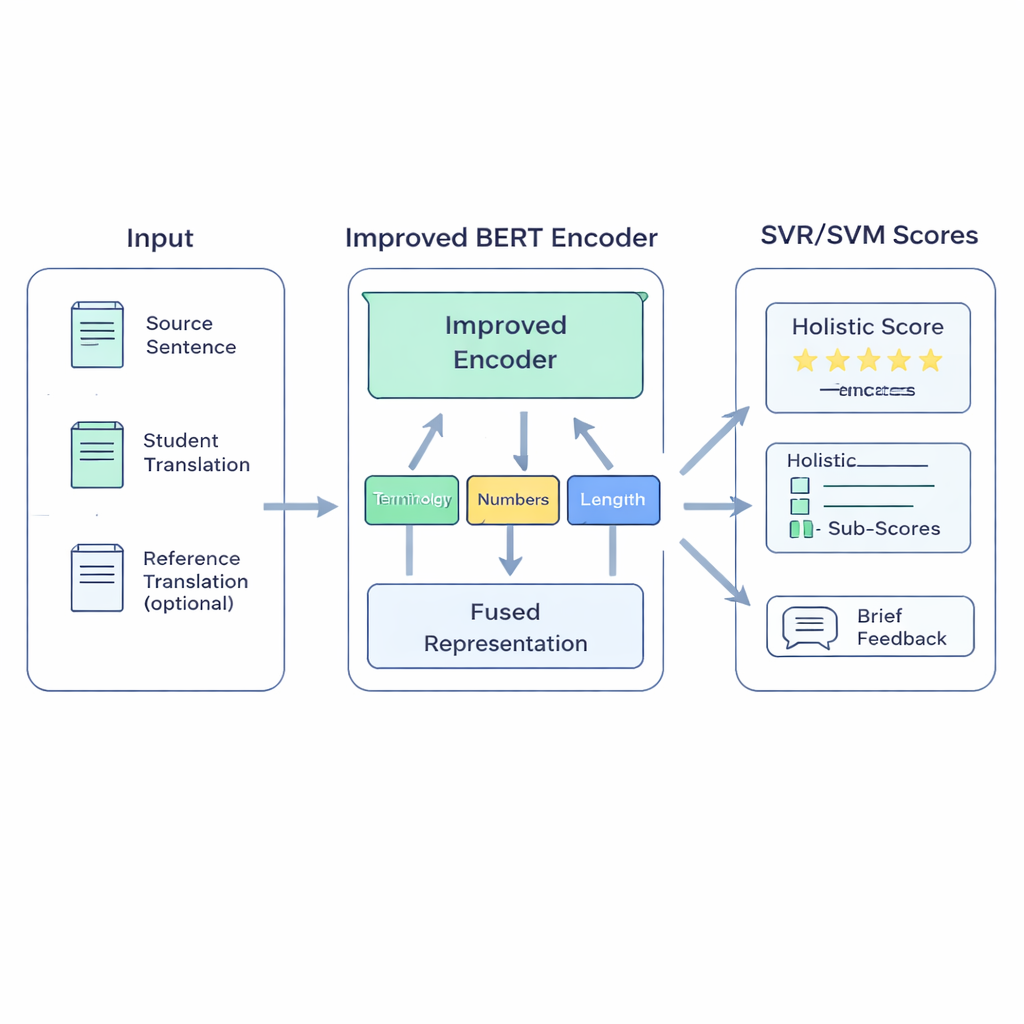
为课堂构建的混合模型
所提出的 BERT-SVM EduScore 系统结合了两类思想:深层语言理解与经典的稳健统计方法。首先,它使用改进版的 BERT 语言模型来读取三段文本:原句、学生译文,以及(若有)参考译文。BERT 将这些转换为丰富的数值摘要,反映的不仅是出现了哪些词,还包括语义对齐的程度。在此基础上,系统加入了一组教师关心的人工特征检查,例如专业术语是否翻译一致、数字和单位是否保留、标点是否合理,以及译文长度是否与原文相当。
系统如何学习像教师一样评分
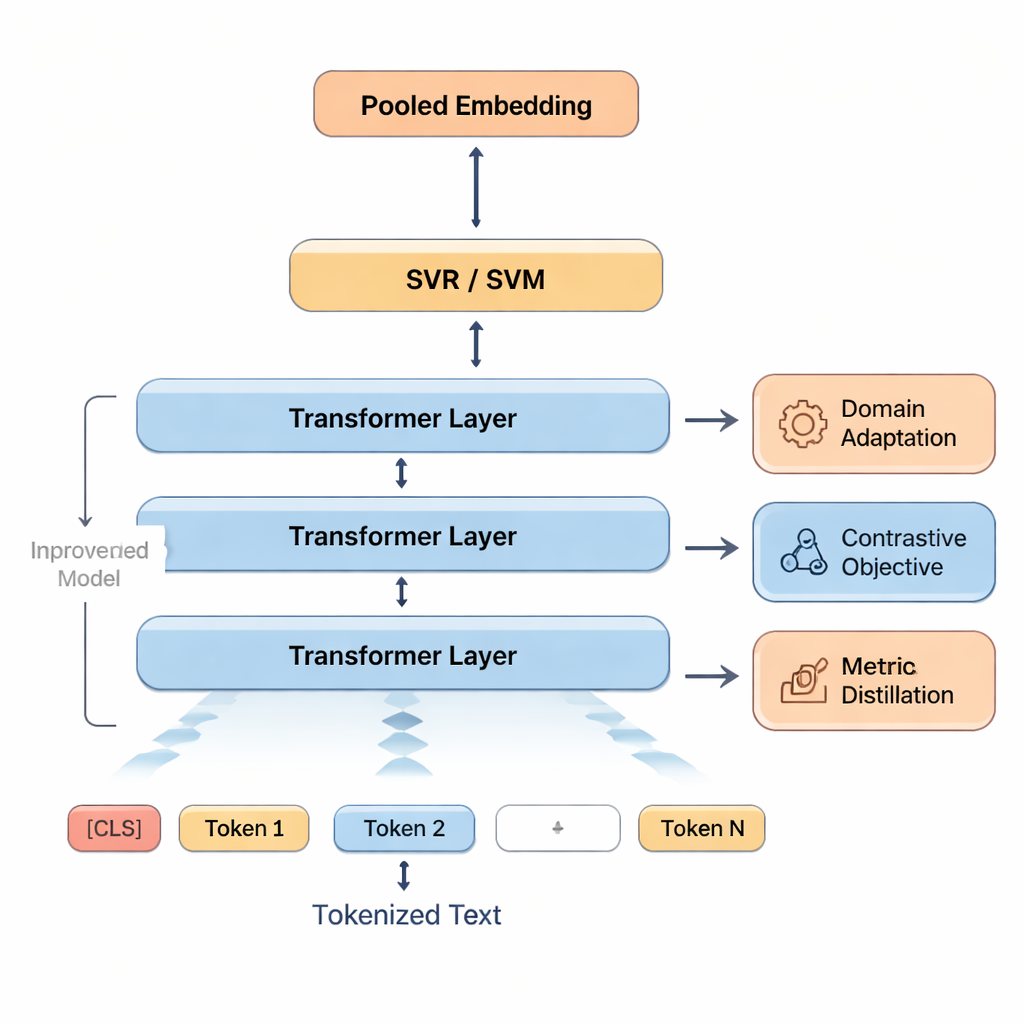
这些信号随后被输入到支持向量机(SVM)中,SVM 是在有限数据下表现良好的一类算法。其一部分用于预测总体分数;其他部分可对准确性或流畅性等方面给出单独评分,或将译文分类到不同质量等级。为帮助模型适应课堂式语言,作者首先对 BERT 在与学生作品相似的文本上进行再训练——这称为领域自适应(domain adaptation)。他们还通过让模型练习区分良好译文与经过轻微编辑的错误版本,来强化 BERT 对相似性与差异性的判断。最后,当有高质量的自动度量(如 COMET 或 BLEURT)可用时,系统会学习模仿这些度量的部分判断,借鉴其优点,同时保持与人工评分的一致性。
将模型付诸测试
研究者在一个包含人工评分的英中机器翻译的大型公开数据集上评估 BERT-SVM EduScore。尽管这些并非学生作业,但其句子级评分类似课堂批改,能提供现实的压力测试。新系统与传统的基于词的评分、较新的基于语义的评分以及若干强大的神经模型进行了比较。结果显示,它不仅与人工判断更为一致——表现出更高的一致性和更小的平均误差——而且运行速度足够快,在标准图形硬件上大约能处理每秒 44 个句子。谨慎的实验表明,将 BERT 适配到合适类型的文本带来最大提升,而额外的学习技巧则提供稳定但较小的增益,且不会明显拖慢系统。
这对教师和学生可能意味着什么
简言之,研究表明精心设计的深度学习与经典方法的混合模型,可以比现有自动工具更可靠地评估翻译,同时速度足以满足实时课堂需求。BERT-SVM EduScore 还不能作为对教师的直接替代:它只在机器翻译上进行了测试,尚未用于真实学生作品的课堂试验或公平性检查。但结果表明,该类系统有望很快通过提供稳定评分并突出潜在问题(如术语误译或数字遗漏)来辅助教师,从而让人工反馈可以集中于翻译中更深层、更具创造性的方面。
引用: Lin, C. A hybrid intelligent assessment model for English translation education with improved BERT and SVM. Sci Rep 16, 5466 (2026). https://doi.org/10.1038/s41598-026-35042-2
关键词: 翻译评估, 语言教育, BERT, 支持向量机, 质量估计