Clear Sky Science · zh
使用机器学习模型进行跨癌种生存期预测
为何以新方式预测癌症生存期很重要
癌症患者及其家属常常会提出一个简单却令人痛苦的问题:“我还能活多久?”医生会根据经验和既往数据尝试回答,但对于许多较罕见的癌症,缺乏足够相似的病例以支持精确预测。本研究探讨现代计算程序是否可以“借用”常见癌症的经验,来帮助预测罕见癌症的生存期,从而可能为更多患者提供更清晰的预期和更契合的治疗方案。 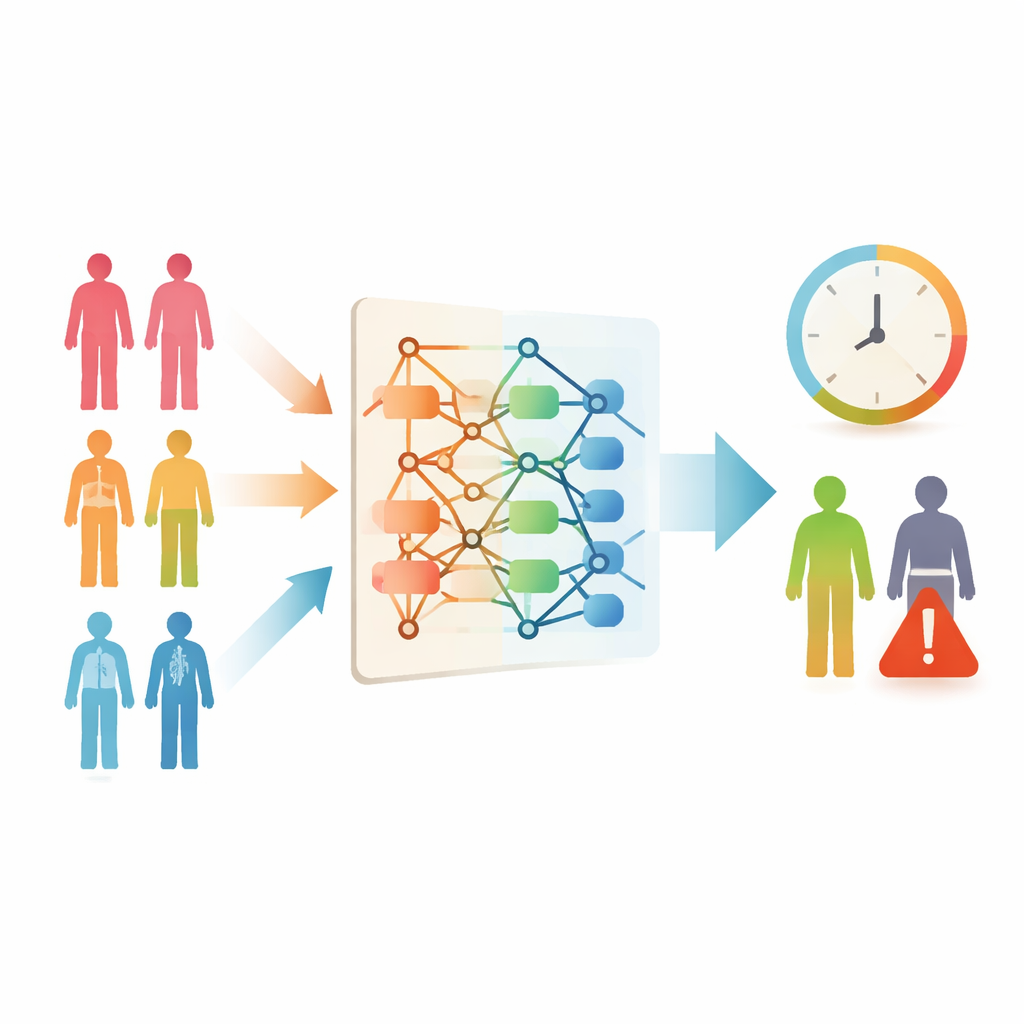
用既往患者资料指导未来护理
研究人员使用了来自巴西圣保罗医院癌症登记的海量真实世界数据。这些记录涵盖了2000年至2019年期间超过一百万名接受治疗的患者,包含年龄、肿瘤分期、所接受的治疗以及诊断后三年是否仍然存活等信息。将关注点放在三年这一时间节点,使团队能够在比较不同典型存活期的癌症时,避免出现极端倾斜的数据情形(即几乎人人存活或几乎人人死亡)。
教计算机发现生存模式
为了将该登记资料转化为预测工具,作者采用了两种流行的机器学习方法:XGBoost 和 LightGBM。这些方法并不试图直接理解生物学机制,而是从成千上万份病历中筛选出将疾病分期、治疗时机等特征与后续生存率关联起来的模式。首先,团队建立了“专家型”模型,每个模型仅以一种癌症类型(如乳腺癌、肺癌或胃癌)为训练对象。随后,他们使用标准衡量指标检验这些模型对同类癌症新患者三年生存预测的表现,这些指标在识别存活者与未存活者之间取得平衡。
一种癌症能否帮助预测另一种?
研究的核心提出了一个大胆问题:以一种癌症训练出的模型能否成功预测另一种癌症的生存?为检验这一点,研究人员按两种方式对癌症进行分组:最常见的癌症(皮肤、乳腺、前列腺、结直肠、肺和宫颈)以及消化系统癌症(口腔、口咽、食道、胃、小肠、结直肠和肛门)。在第一阶段,他们为每种癌症训练独立模型并在其他癌种上测试,仅选择那些在存活与未存活预测上保持合理平衡的配对。在后续阶段,他们将选定癌种的数据合并为共享训练集,创建更通用的模型,从相关肿瘤中汲取模式。 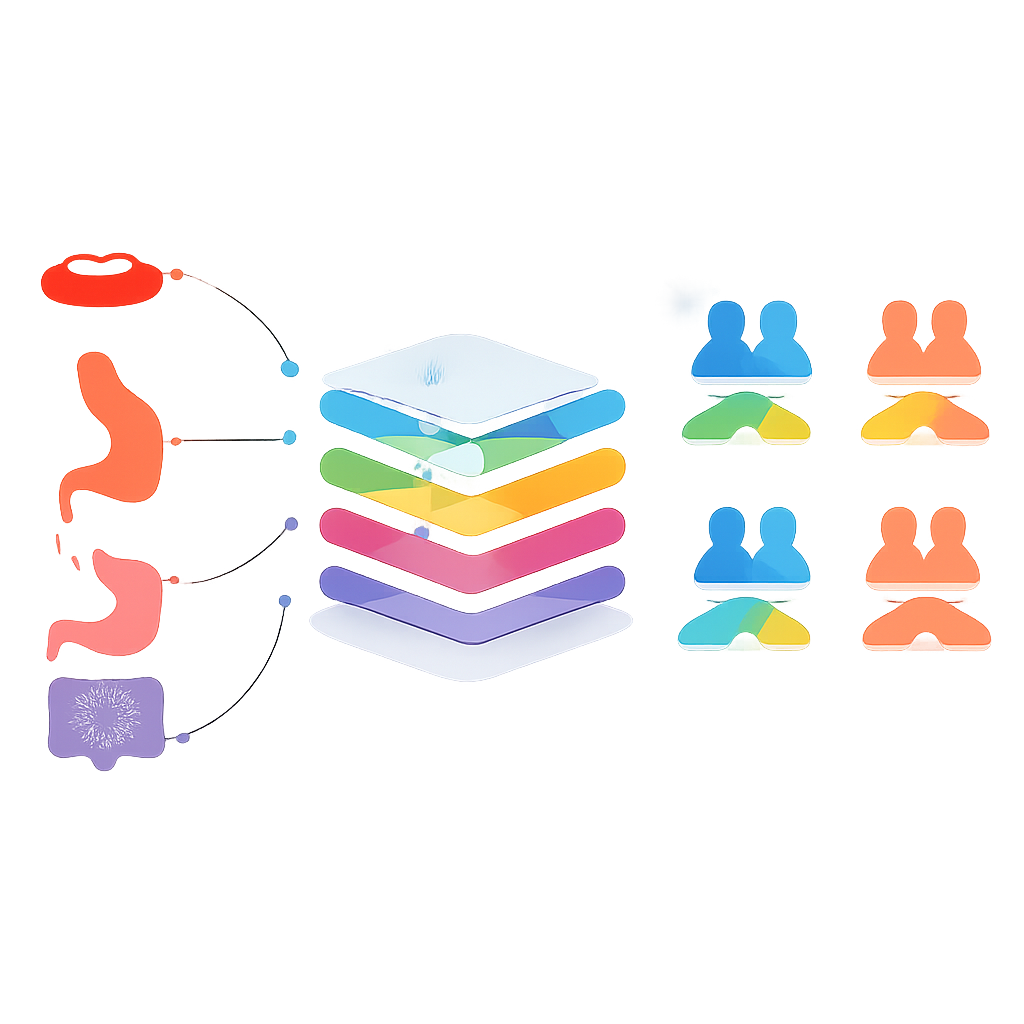
跨癌种学习何时有用——何时无效
对于常见癌症,将多种癌症的数据合并并未超过最佳的专家型模型。例如,对所有六种常见癌症训练的单一模型,其预测准确度低于针对每种癌症单独定制的模型。对某些消化系统癌症的情况则有所不同:当口腔癌、食道癌和胃癌的数据合并时,得到的模型在预测胃癌三年生存方面略优于仅以胃癌数据训练的模型,平衡准确率略高于80%。然而,统计检验显示这一提升并不显著高于偶然差异,意味着共享模型与专家型模型基本上不分高下。对口腔癌、小肠癌和结直肠癌也出现了类似的“几乎更好但又不完全显著”的结果,常伴随在正确识别存活者与未存活者之间的权衡。
这对罕见癌症患者意味着什么
尽管跨癌种模型很少明显超越最佳的疾病特异性模型,但它们常常能接近该水平——仅靠从其他癌种借来的信息。对于缺乏大型高质量数据集的罕见癌症而言,这是一个令人鼓舞的信号:未来当无法构建专门工具时,医生或许可以依赖以更常见癌症训练的模型来提供有意义的生存期估计。作者提醒,这些方法尚不适合常规临床使用,需在其他地区验证并与更深入的生物学数据相结合。尽管如此,该研究指向了一个前景:不再因为癌症罕见而让任何患者缺乏应有的指导。
引用: Cardoso, L.B., Egydio, J.E., Toporcov, T.N. et al. Cross-cancer survival prediction using machine learning models. Sci Rep 16, 9623 (2026). https://doi.org/10.1038/s41598-025-34133-w
关键词: 癌症生存期预测, 肿瘤学中的机器学习, 跨癌种建模, 罕见癌症, 临床登记数据库