Clear Sky Science · zh
通过混合深度学习计算句子相似度分数,着重处理否定句
为何词义对公平评分至关重要
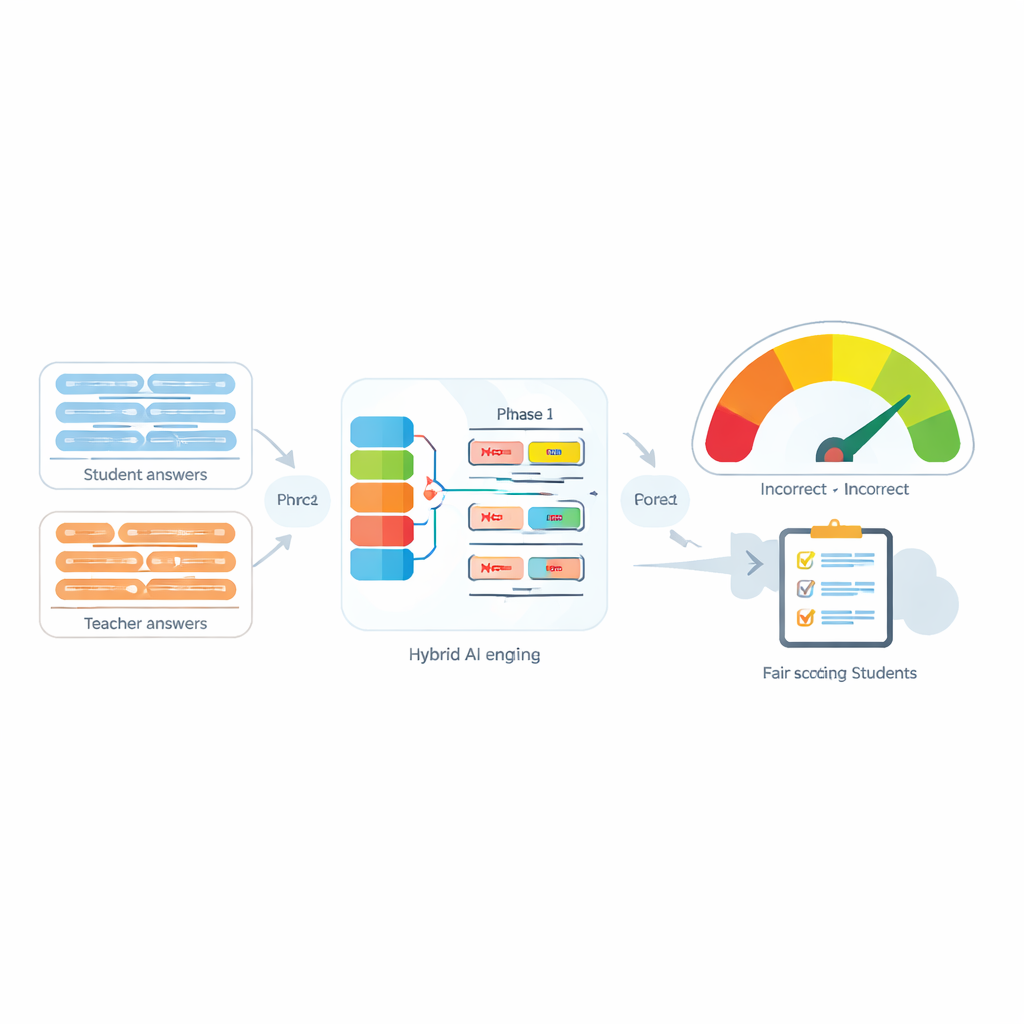
当学生用自己的话回答问题时,辅助教师评分的计算机必须理解的不仅仅是共同出现的关键词。像“不是”这样的小词就能颠倒句子的含义,如果自动系统忽视了这种变化,学生可能会被不公平地评分。本文通过设计一种新的句子语义比较方法来解决这一问题,并特别关注否定词如何改变陈述的内容。
小词却有大影响的挑战
自动评估系统日益被用于减轻教师的工作量,它们通过将学生回答与教师的标准答案进行比较来评分。许多现代工具通过把每个句子转为数值“指纹”并测量这些指纹的接近程度来实现这一点。这些工具在没有否定的情况下表现相当不错,但当出现“不是”“从不”或“无”等否定词时往往失效。例如,“该方法是准确的”和“该方法不准确”在计算机看来可能出奇地相似,尽管它们的意义相反。作者指出,不仅是否定的存在会改变含义,否定词的数量以及它们在句中出现的位置也会完全改变预期意义。
构建能教授细微差别的数据集
为了训练真正理解否定的系统,作者首先需要强调这些棘手案例的数据。他们创建了否定句相似度数据集(Negation-Sentence-Similarity Dataset),包含来自操作系统、数据库、计算机网络和机器学习四个计算机科学领域的8,575对句子。对于每一对,人工标注了已考虑否定的相似度分数。该数据集还记录了每个句子使用了多少否定词以及遵循何种否定模式,例如单个“不是”、偶数或奇数个否定,或否定与“因为”“但是”等连接词交互的更复杂情况。这些详尽的标签为模型提供了关于否定如何塑造意义的显式提示。
融合多重视角的混合引擎
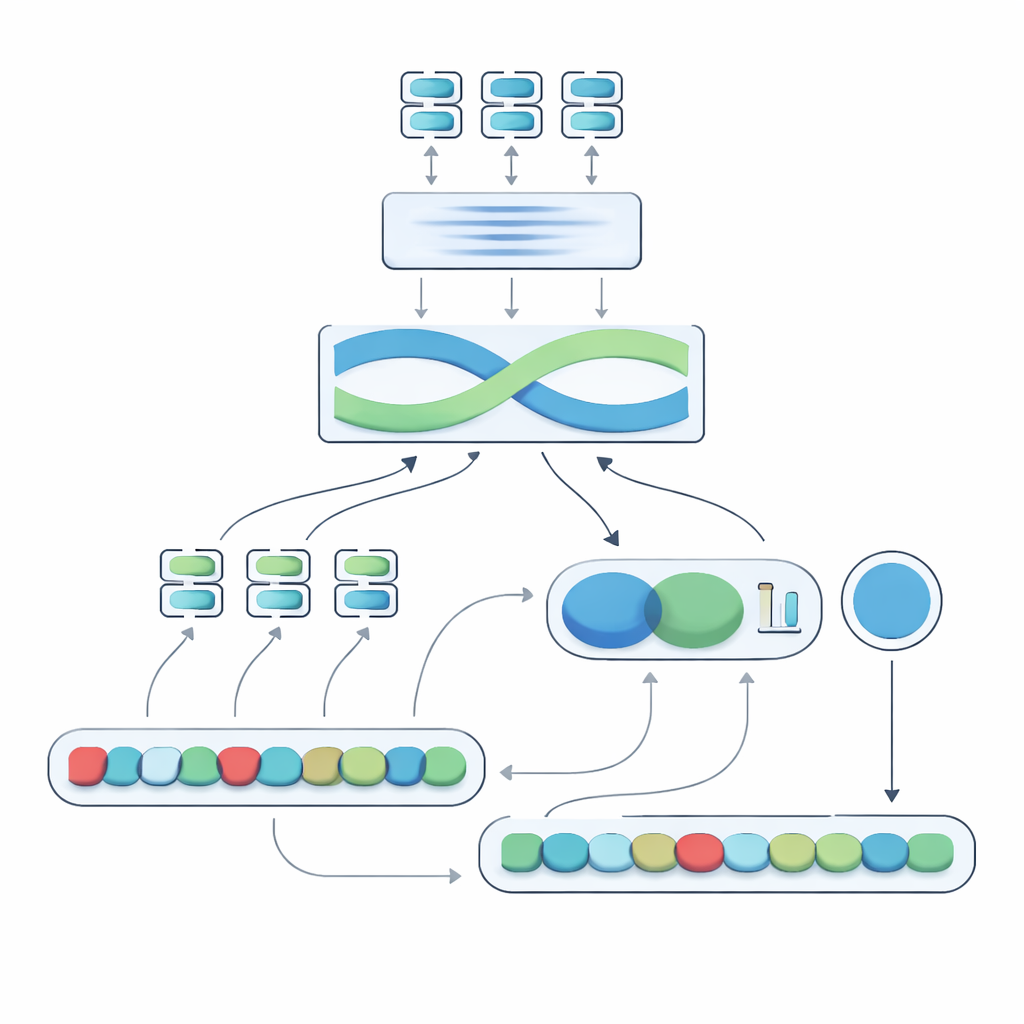
所提出系统的核心,称为否定对齐相似度评分器(Negation-Aligned Similarity Scorer),是一个两阶段引擎。第一阶段,系统将每个句子输入多个不同的语言模型,每个模型捕捉意义的不同侧面。它们的输出被拼接在一起,然后送入一个双向循环网络,该网络从整体上观察句子,考虑词序和局部上下文。这会生成每个句子的紧凑摘要,更善于处理微妙措辞,包括否定词相对于其他词的位置。
教会模型感知否定的翻转
在第二阶段,系统比较两个句子摘要并加入关于否定的显式信息。它考察摘要之间的差异程度、重叠程度,并将这些信号与三个简单特征结合:否定词数量的差异、句子中否定词是奇数还是偶数(这可能会翻转或抵消否定意义)以及否定词是否出现在大致对应的位置。所有这些线索在一个小型预测网络中融合,输出0到100的相似度分数。通过在精心构建的数据集上端到端训练,该分数变得对否定如何重塑意义敏感,而不再把“不是”视为普通词汇。
新评分器在实践中的表现如何
为了检验他们的方法,作者在自建数据集和一个广泛使用的句子相似度基准上进行了评估。与使用标准方法的强大基于Transformer的基线相比,新评分器取得了更低的预测误差和更高的分类质量,F1分数接近0.97。在精心挑选的示例中,当否定明显颠覆意义时它给出低相似度分数,而当双重否定有效抵消时则给出高分,而竞争模型往往高估相似度。消融研究确认了两个关键成分——序列感知的循环层和显式的否定特征——对于性能提升都很重要。
这对学生和未来工具意味着什么
对非专业读者而言,结论很明确:我们使用“不是”的方式很重要,机器是可以被教会去注意到的。通过融合多个语言模型、上下文处理以及对否定词的简单计数和位置判断,所提出的评分器提供了一种更公平、更可靠的方法来判断两个句子是否真正具有相同含义。这有助于自动评分系统避免严重错误,例如把“是不被允许的”当作“是被允许的”。尽管该方法计算开销更大且仍集中于技术领域,但它指向了未来更能捕捉日常语言细致逻辑的工具,使自动语言技术变得更智能、更值得信赖。
引用: M, R., L, J., Ummity, S.R. et al. Computation of sentence similarity score through hybrid deep learning with a special focus on negation sentence. Sci Rep 16, 8904 (2026). https://doi.org/10.1038/s41598-025-34084-2
关键词: 句子相似度, 语言中的否定, 自动评分, 自然语言处理, 深度学习模型