Clear Sky Science · zh
通过GPU加速实现高性能IP查找,以支持数据驱动通信网络中可扩展且高效的路由
为什么更快的互联网通路很重要
你分享的每张照片、你播放的每个视频或你发送的每条消息都必须通过一系列被称为路由器的数字十字路口。每个路由器都必须迅速决定将每个数据包发送到哪里。随着全球互联网使用量激增,这些决策每秒发生数十亿次,即便是极小的延迟也会导致浏览变慢或网络拥塞。本文探讨了一种新方法,通过利用图形处理器的海量并行计算能力(同样驱动电子游戏和人工智能的芯片),来加速决策过程中最耗时的步骤之一,从而保持未来网络的快速性和可扩展性。
互联网的隐藏地址簿
在每个路由器的核心是一本巨大的地址簿,称为转发表,它将IP地址的范围映射到路径上的下一个跃点。当一个数据包到达时,路由器必须查找哪个条目最匹配该包的目的地,采用“最长前缀匹配”规则:在所有部分地址匹配中选择最具体的那个。传统的软件方法将这些前缀存储在树状结构中并逐步遍历。该方法可行,但当表增长到成千上万乃至数十万条目时,查找过程会变慢并且占用更多内存,尤其是在一次只能处理有限任务的普通中央处理器上。
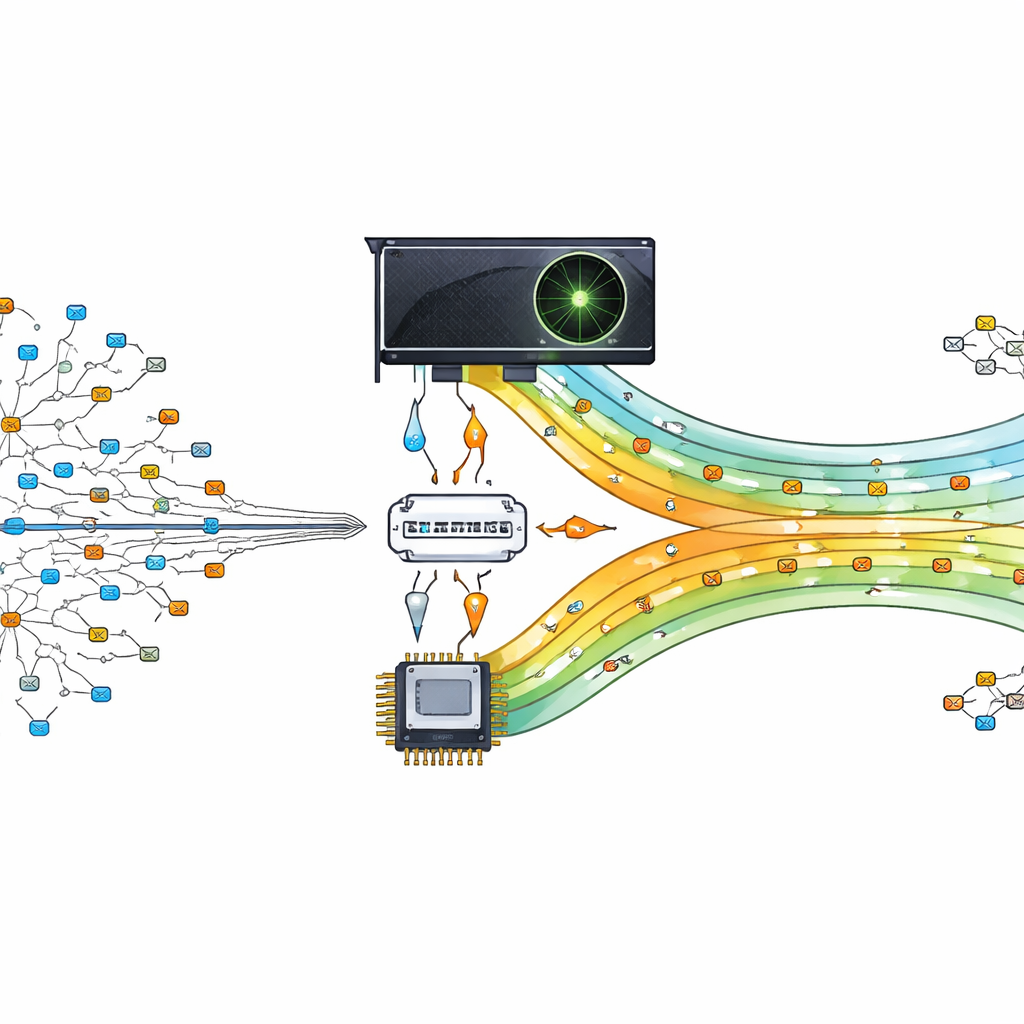
把图形芯片变成交通指挥官
作者提出将这项繁重的查找工作卸载到图形处理单元(GPU)上,这是一种设计用来并行运行成千上万小任务的芯片。他们的设计将GPU视为主处理器的助手。中央处理器准备并组织路由表,然后将压缩后的数据版本发送给GPU。当数据包到达时,其目的地址被分割并发送到GPU,在那里许多线程同时搜索最佳匹配。通过让数百甚至数千次查找并行进行,路由器能够跟上现代数据驱动通信需求的步伐。
缩短地址以加速决策
工作的一个关键见解是,较短的地址更容易搜索。作者不是使用原始IP地址,而是用一种无损方法——霍夫曼编码(Huffman coding)对其进行压缩,为最常见的地址模式分配更短的编码。这减少了表示每个条目所需的平均比特数,降低了内存占用并缩短了底层搜索结构的高度。然后他们将前缀存储在一种“多比特”树中,一次检查若干比特而不是仅一个,从而进一步减少所需的步骤。为了契合GPU的优势,他们将这棵树转换为简单的一维数组,用常规的索引计算替代复杂的指针跳转,使得数千个线程都能高效执行。
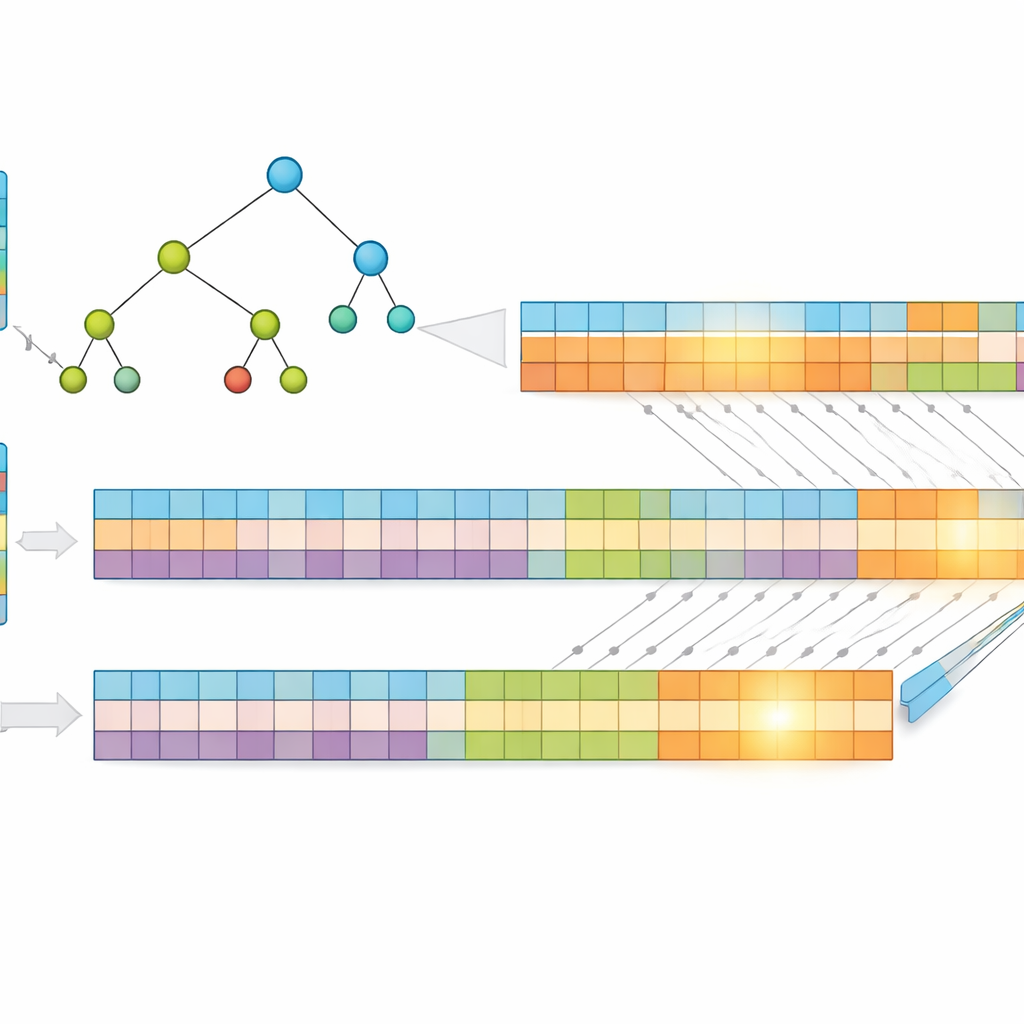
为大规模并行划分问题
为了进一步提升性能,研究人员将每个压缩地址分成两等份,并构建两棵独立的树——一棵用于前半部分,一棵用于后半部分。当数据包到达时,GPU并行搜索这两棵树。每次搜索返回一小组可能的匹配项,最终结果由这些集合的交集产生,以找到共享的、最具体的前缀。由于工作被划分并同时处理,所需时间主要取决于最大前缀长度和每步检查的比特数,而不是表中条目的数量。基于真实互联网路由数据的测试表明,这种设计即使在表增长时也能保持近乎恒定的查找时间。
实验揭示了什么
团队将他们的GPU方法与多种知名方法进行了比较,包括经典二叉树、压缩树以及其他GPU加速方案如哈希和二叉搜索树。在真实路由数据集上,他们的系统带来了显著提升:比流行的基于中央处理器的树方法快约83–91%,比先前的GPU方法快约89–97%。压缩还平均将内存使用减少了大约三分之一,减轻了片上有限内存的压力,并帮助保持GPU搜索结构的浅层与高效。更重要的是,该方法的性能在不同路由表规模下保持稳定,强调了其对不断增长网络的适用性。
这对普通用户意味着什么
对非专业人员来说,结论是作者展示了如何将图形芯片变成互联网数据的高效“交通警察”,通过对地址信息进行巧妙的压缩和拆分。结合压缩、更智能的树布局和大规模并行搜索,他们的方法比许多现有技术更快地为每个数据包找到最佳路径,而且在互联网地址簿扩展时不会明显变慢。尽管该工作主要在当今地址系统上演示,但相同思想可扩展到未来更大的地址空间,有助于在我们对数据需求持续增长的情况下保持未来在线服务的响应性。
引用: Sonai, V., Bharathi, I., Alshathri, S. et al. High performance IP lookup through GPU acceleration to support scalable and efficient routing in data driven communication networks. Sci Rep 16, 9612 (2026). https://doi.org/10.1038/s41598-025-33233-x
关键词: GPU路由, IP查找, 网络可扩展性, 数据包转发, 并行计算