Clear Sky Science · zh
用于皮肤组织学图像语义分割的增量学习方法
为什么教计算机“读”皮肤切片很重要
皮肤癌是全球最常见的癌症之一,医生常依赖在显微镜下观察的薄片组织来判断肿瘤的严重程度并决定治疗方案。阅读这些切片既耗时又要求高,且不同专家之间可能存在差异。本研究探讨如何构建能够识别显微镜图像中不同皮肤组织和癌变的计算机系统,更重要的是,这些系统可以随着新类型图像的加入不断改进——类似于一个在职业生涯中持续学习的人类实习者。
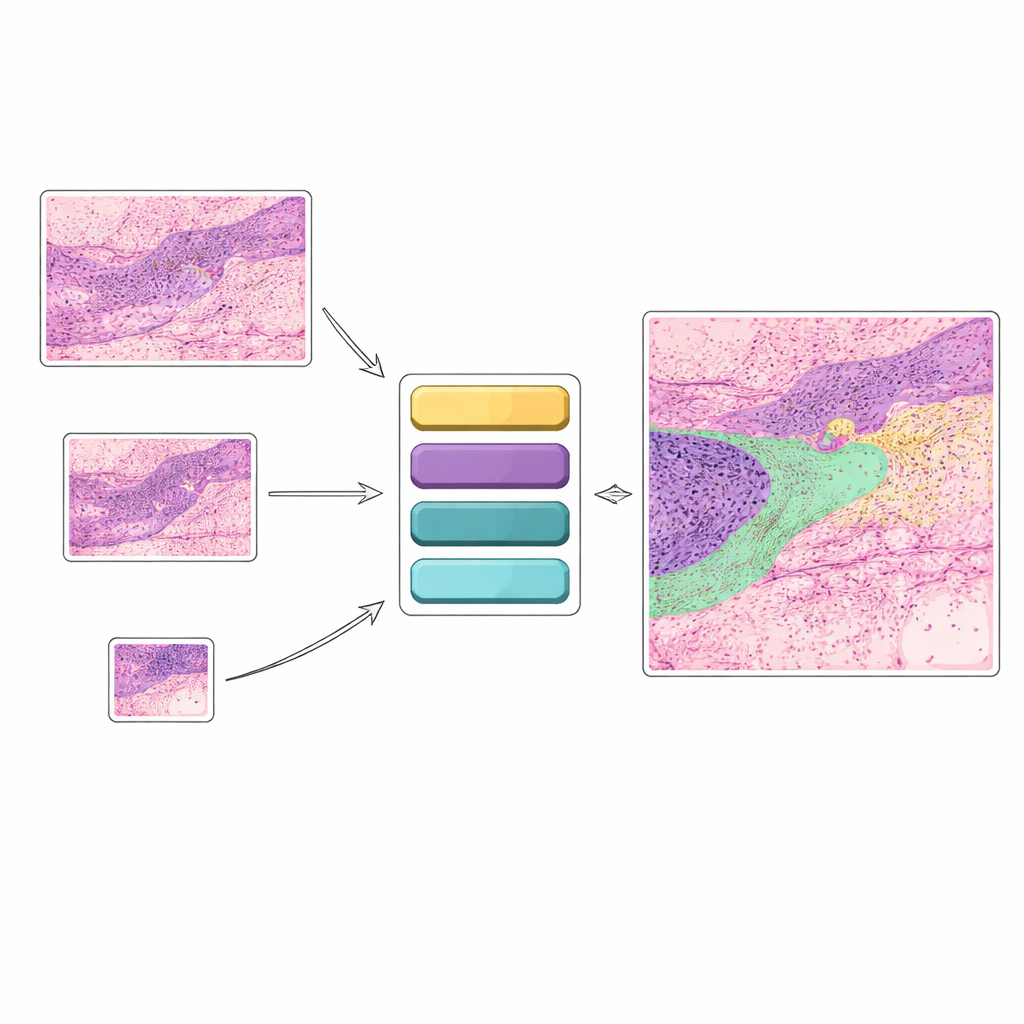
从简单的“是/否”到详尽的组织地图
许多现有的皮肤癌人工智能工具仅对图像给出狭义答案,如“有癌”或“无癌”。虽然有用,但这种二元判断无法反映病理学家所见的丰富细节。临床上,医生关心多种结构:不同类型的癌症、健康的皮肤层、毛囊、腺体、炎性区域等。本研究聚焦于“语义分割”,即为组织学图像中的每个像素分配十二类组织中的一类,从而生成一张彩色编码的地图,精确显示不同癌变和正常组织的位置,为诊断和治疗规划提供更清晰的依据。
为何现有智能系统难以适应变化
当今强大的深度学习模型通常假设所有训练数据一次性可得。训练完成后,它们往往会“锁定”已有知识。如果后来引入具有不同特性的新增数据——例如不同放大倍数的图像——最稳妥的做法常常是从头重新训练整个模型。这既昂贵又耗时,而且更糟的是,新增信息可能导致“灾难性遗忘”,即模型在早期任务上的表现悄然下降。然而在临床环境中,随着扫描仪升级、成像设置变化以及医院收集新类型样本,数据持续演变。无法平滑吸收此类变化的 AI 工具在日常实践中难以令人信任。
受人类学习方式启发的分步学习策略
作者以一种现代视觉变换器架构 SegFormer 为基础,将其改造成用于非黑色素瘤性皮肤癌的“增量学习”系统。模型不是一次性看到所有数据,而是分阶段训练,使用来自昆士兰大学公开数据集的组织学切片。首先从高倍(10×)图像学习,细节清晰;随后加入 5×、再到 2× 放大图像,同时保留部分早期的高细节数据。特殊的损失函数帮助新模型在适应更粗、更广视角图像时保留先前关于组织模式的知识。这种“学习而不遗忘”由知识蒸馏技术引导:早期模型充当新模型的教师,另有一个互相蒸馏项推动新旧表示保持一致与和谐。
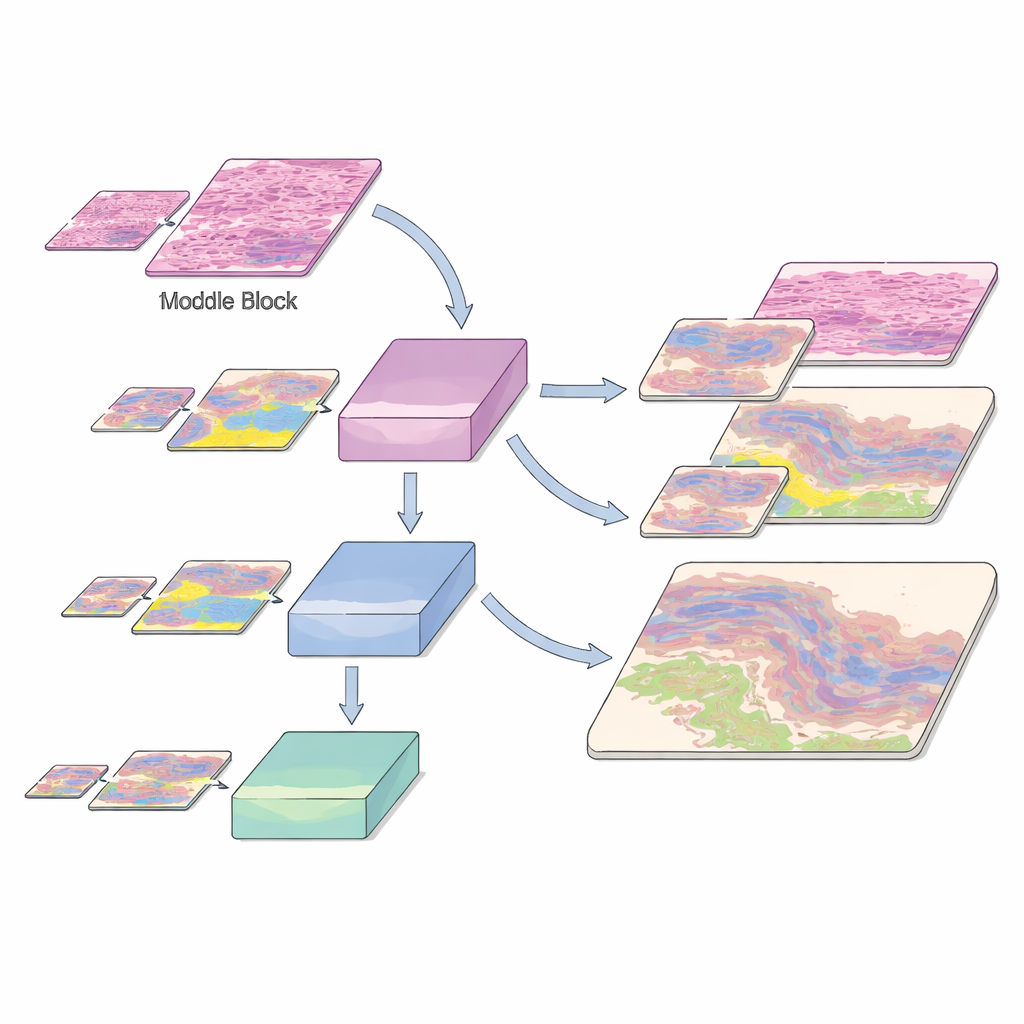
跨放大倍数与稀有组织类型的学习
组织学图像的挑战不仅在于组织类型众多,还在于一些关键结构非常稀少。该数据集包含常见癌种,如基底细胞癌和鳞状细胞癌,以及正常和炎性皮肤层,这些均由专家逐像素注释——一个耗时数百小时的细致过程。作者将巨幅切片切成小补丁,并在训练、验证与测试集之间进行了谨慎划分,保留了各放大倍数下组织类别的分布。为帮助系统识别稀少但临床关键的区域,他们通过旋转补丁并在多个放大级别上展示这些组织来扩充弱势类别。多分辨率的暴露使 AI 无论在清晰的特写还是较模糊的远视图中都能识别相同的生物结构。
与早期方法相比模型的表现
单独在每个放大倍数上训练的 SegFormer 模型在许多组织类别上已优于早期卷积设计(如 U-Net)。但当应用增量学习方案——先在 10× 上训练,然后在 10× 与 5× 上联合训练,最后在 10×、5× 与 2× 上一起训练——收益尤为显著。总体准确率从仅使用 10× 时约 89% 提升到包含三种放大倍数后超过 95%。预测与真实区域的重叠度量也稳步提高,对基底细胞癌、鳞状细胞癌以及表皮和乳头真皮等关键正常层的表现均超出竞争方法。重要的是,随着每个新放大级别的加入,模型并未遗忘先前学到的内容;相反,其对组织结构的理解变得更稳健、更具普适性。
这项工作如何推动 AI 辅助诊断走近临床
对非专业读者来说,主要结论是作者构建了一个能持续学习新图像而不丧失旧技能的皮肤组织“制图器”。通过精心设计分阶段的学习流程以及模型如何重用自身早期知识,他们展示了构建能够随着医学影像实践演变而自我适应的 AI 工具是可行的。尽管仍需在不同医院和疾病类型上做更多验证,这种基于变换器的增量方法指向了可以随数据变化保持最新、提供详细可视化癌变位置并最终帮助病理学家做出更自信且一致诊断决策的 AI 系统。
引用: Fatima, S., Salam, A.A., Akram, M.U. et al. Incremental learning approach for semantic segmentation of skin histology images. Sci Rep 16, 9593 (2026). https://doi.org/10.1038/s41598-025-31553-6
关键词: 皮肤癌, 组织学图像, 语义分割, 增量学习, 深度学习变换器