Clear Sky Science · zh
包含序列、结构与结合亲和力数据的抗体与纳米抗体统一数据集
为何微小免疫工具与大数据重要
抗体及其更小的近亲纳米抗体是机体对抗感染和癌症的精确制导“导弹”。药物开发者现在尝试像工程师设计飞机一样,在计算机上设计这些分子。但直到最近,用于这种人工智能设计的原始材料——关于抗体成分、形状以及它们与靶标结合紧密程度的可靠数据——分散在许多不兼容的数据库中。本文介绍了抗体与纳米抗体设计数据集(ANDD),这是一个统一的公开资源,旨在为研究人员提供清洗过的、全面的数据,帮助他们设计下一代靶向治疗方案。
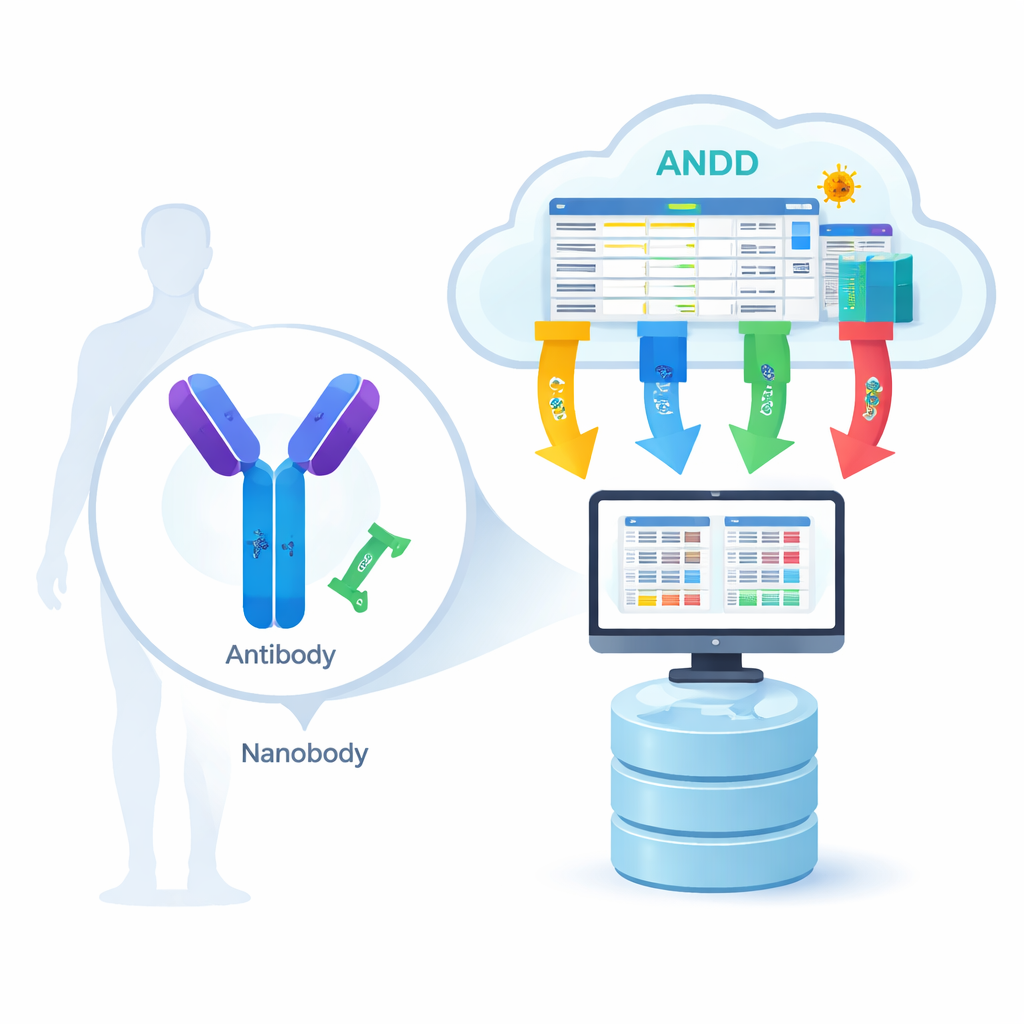
从生物学的锁与钥匙到数字蓝图
抗体是大型的Y形蛋白,而纳米抗体则是更小的单片版本,存在于羊驼和美洲驼等动物中。两者都识别病毒、癌细胞或其他与疾病相关蛋白上的特定“锁”。要让计算模型学习这种识别机制,它们需要大量实例的四类信息:氨基酸序列(零件清单)、三维结构(形状)、抗原(靶标)以及结合强度(两者结合的紧密程度)。直到现在,大多数资源一次只包含其中一两类信息,迫使科学家在多个数据库间切换并手动拼接,既拖慢了进展,也引入了错误。
将分散碎片汇聚成有序的文库
ANDD 团队从15个主要来源收集数据,包括专门的抗体与纳米抗体数据库、通用蛋白质仓库,甚至专利文献。随后,他们将这些原始输入通过精心编排的流水线处理:下载、重格式化为统一模式、交叉核对标识符、去重并统一命名规则。当不同数据库存在分歧时,以经人工策划的来源和直接实验为优先。最终结果是一个单一表格加上一组结构文件,它们在一致的方式下连接序列、结构、靶标和结合信息,并为每条记录打上标签,使用户可以精确追踪数据来源及其处理过程。
为不同研究需求设置分层细节
ANDD 中并非每条条目都同样详尽,因此作者将集合按细节层次组织。最广泛的层次包含 48,683 条具有序列信息的抗体和纳米抗体条目。一个较大的子集增加了三维结构,而更小的子集进一步包含了靶蛋白的序列。最详细的层——数千条条目——则包含测量或预测的结合强度。例如对于抗体,18,464 条记录具有序列信息,同样数量的记录结合了序列与结构,超过 8,000 条还包含抗原序列,7,737 条拥有完整的序列、结构、抗原与亲和力数据。纳米抗体也有相应的层级结构,使实验人员与模型构建者可以灵活选择:他们既可以使用大而简单的数据集,也可以选择更小但信息更丰富的子集。
填补结合强度数据的空白
结合强度对药物设计至关重要,但实验值稀少且报告不均。为在不模糊数据与预测界限的前提下弥补这一空白,作者使用了一种专门的深度学习工具 ANTIPASTI,仅对那些具有结构但缺乏实测值的条目估算结合强度。这些 2,271 个预测值被明确标记并与约 7,000 个实验测得值分开保存。团队随后使用另一个模型 AlphaBind 以及对数学相关的结合度量进行比较来检查整体一致性。较强的相关性与较低的误差表明,人工整理的实验值是可靠的,而预测值遵循合理趋势,但不应被视为最终真值。
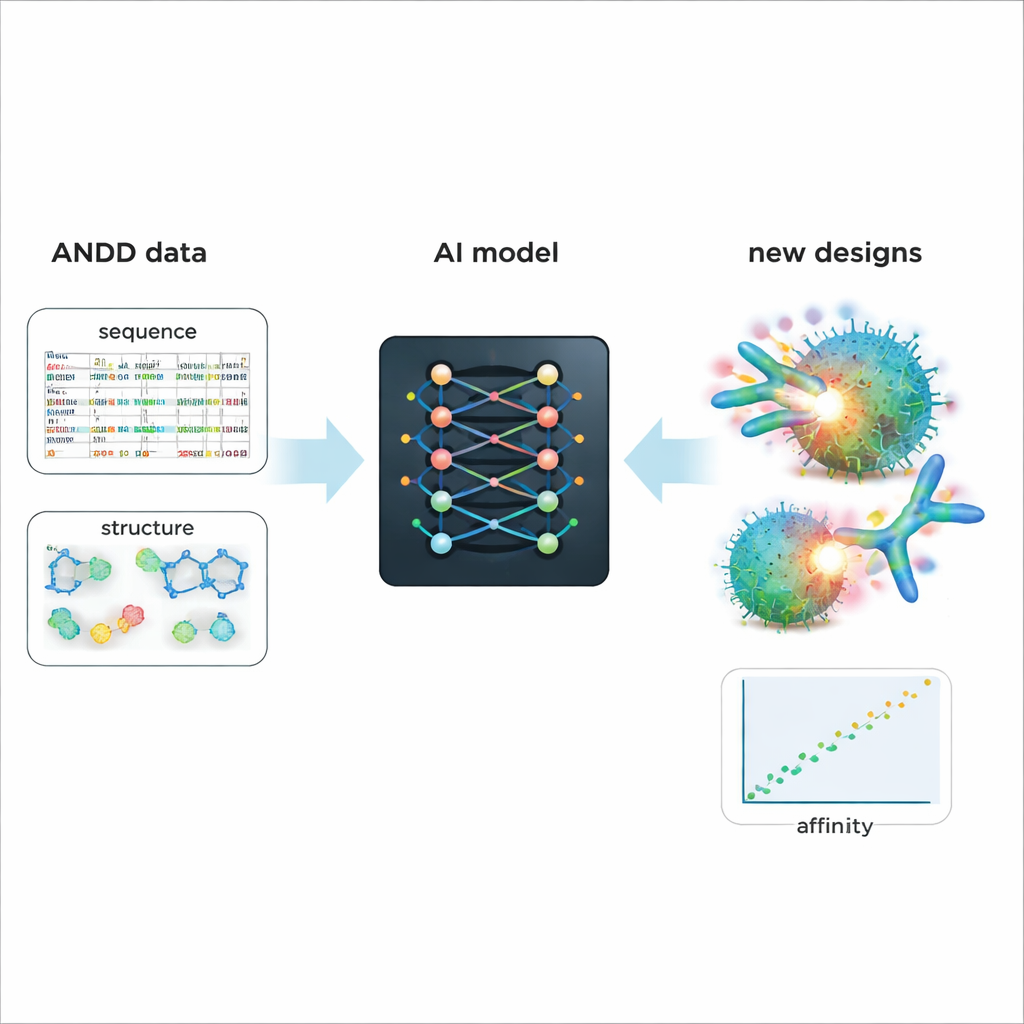
为更聪明的未来药物设计提供动力
为展示 ANDD 的实际价值,作者微调了一个现有的生成式 AI 模型,用于设计抗体与纳米抗体。在 ANDD 的序列、结构、靶标与亲和力信息上训练后,生成的分子在预测结合能力和形状真实性方面均优于以更老、更简单数据训练的基线模型。除了该案例研究外,ANDD 以宽松许可公开提供,附带完整文档和可复现的构建流水线,并设计为定期更新。对于非专业读者,关键信息是:ANDD 将零散混乱的抗体数据整合为一个连贯且可信的文库——为 AI 工具提供了更好的出发点,以设计更精确、更有效的生物制剂药物。
引用: Wu, Y., Liu, X., Hrovatin, K. et al. A Unified Dataset for Antibody and Nanobody Design Including Sequence, Structure, and Binding Affinity Data. Sci Data 13, 295 (2026). https://doi.org/10.1038/s41597-026-06878-0
关键词: 抗体设计, 纳米抗体, 结合亲和力, 生物制剂治疗, AI 药物发现