Clear Sky Science · zh
A Large-Scale Peripheral Blood Cell Dataset for Automated Hematological Analysis
血细胞图像为何重要
每次常规血液检查中都隐藏着一个显微镜下的细胞世界,这些细胞能在症状明显出现前就揭示感染、贫血,甚至血液癌症。医生传统上通过显微镜目视检查这些细胞,这是一门谨慎但耗时的技艺。本研究介绍了一个非常大且经过精心标注的血细胞图像集合,旨在教会计算机自动识别这些细胞。目标是通过赋予人工智能所需的视觉经验,使未来的血液检测更快、更一致并更易普及,帮助医生准确阅读血涂片。
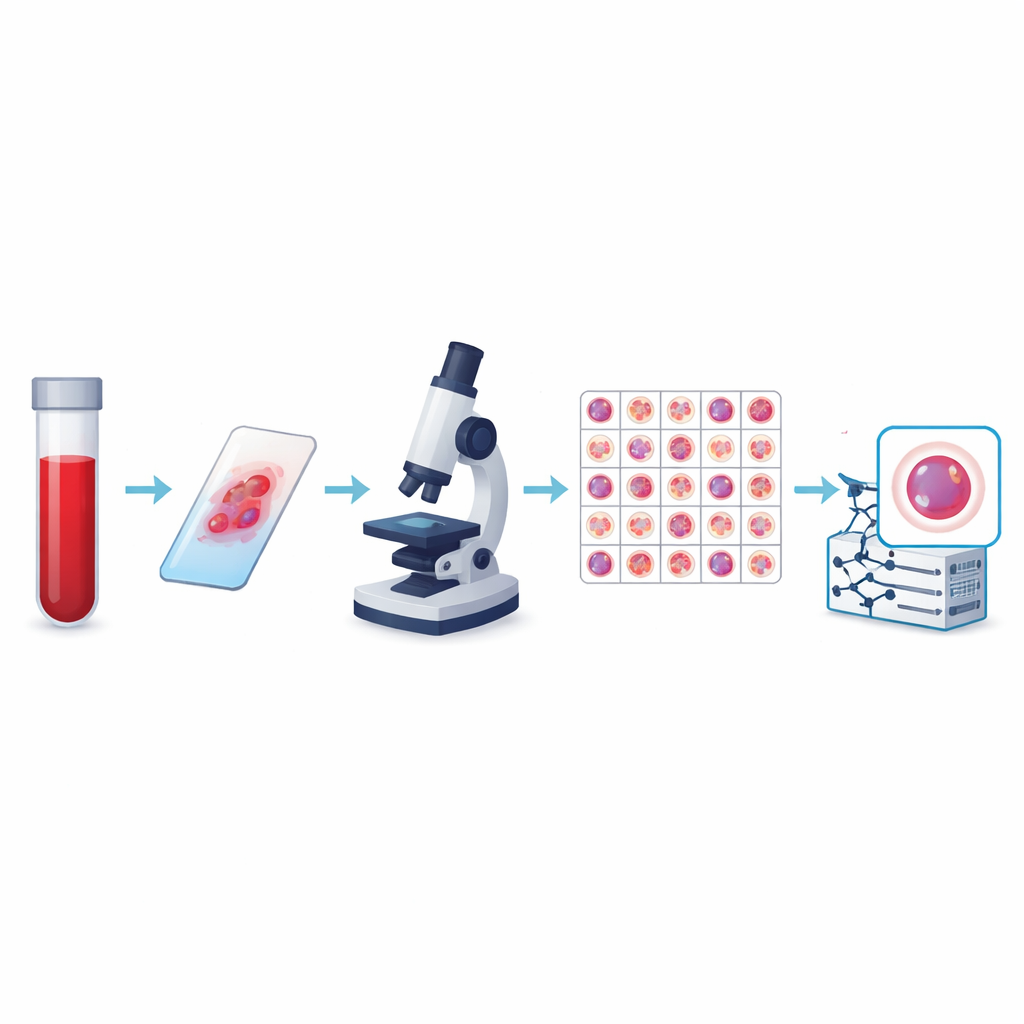
从简单计数到智能成像
白细胞是我们免疫系统的重要防御者,它们的种类构成和形态为健康状况提供关键线索。某些细胞类型的增多可能提示感染或过敏,而未成熟的“原始(blast)”细胞的突然出现则可能预示白血病。实验室已经使用自动化机器计数细胞,但细微的形态变化仍常常需要专家目光。人工审核者之间会有分歧,逐张检查载玻片也很耗时。随着医学更多依赖数字成像与人工智能,越来越需要大型且可信的图像集合来训练计算机像经验丰富的血液学家一样可靠地识别这些特征性细胞模式。
构建庞大的血细胞图书馆
作者创建了目前最大的公开外周血细胞图像集合,称为KU-Optofil PBC数据集。它包含31,489张高分辨率单细胞图片,分布于13个组别,包括常见的防御细胞如淋巴细胞和分叶中性粒细胞,也包括一些罕见但医学上重要的类型,如原始细胞、骨髓细胞和反应性淋巴细胞。所有图像均来自经过标准化条件制备的染色血涂片,且在同一家医院使用相同的成像系统拍摄。这种一致性意味着从数据中学习的计算机看到的是一种稳定且受控的细胞视图,而不是一堆不兼容的拼凑图像。
专家审阅与精心策划
为了使数据集值得信赖,每张图像由两名经验丰富的实验室技术员独立标注,任何分歧由第三位专家仲裁。统计检验显示,对每类主要细胞类型,审核者间的一致性都非常高,某些类型甚至达到完全一致。团队还制定了严格规则来决定保留哪些图像,剔除了模糊、重叠或染色不良的细胞。最终图像均为相同尺寸和颜色格式,并按训练、验证和测试文件夹组织,便于其他研究者公平比较算法。附加文件将每张图像与匿名患者关联,便于研究模型是否真正能从一人推广到另一人。
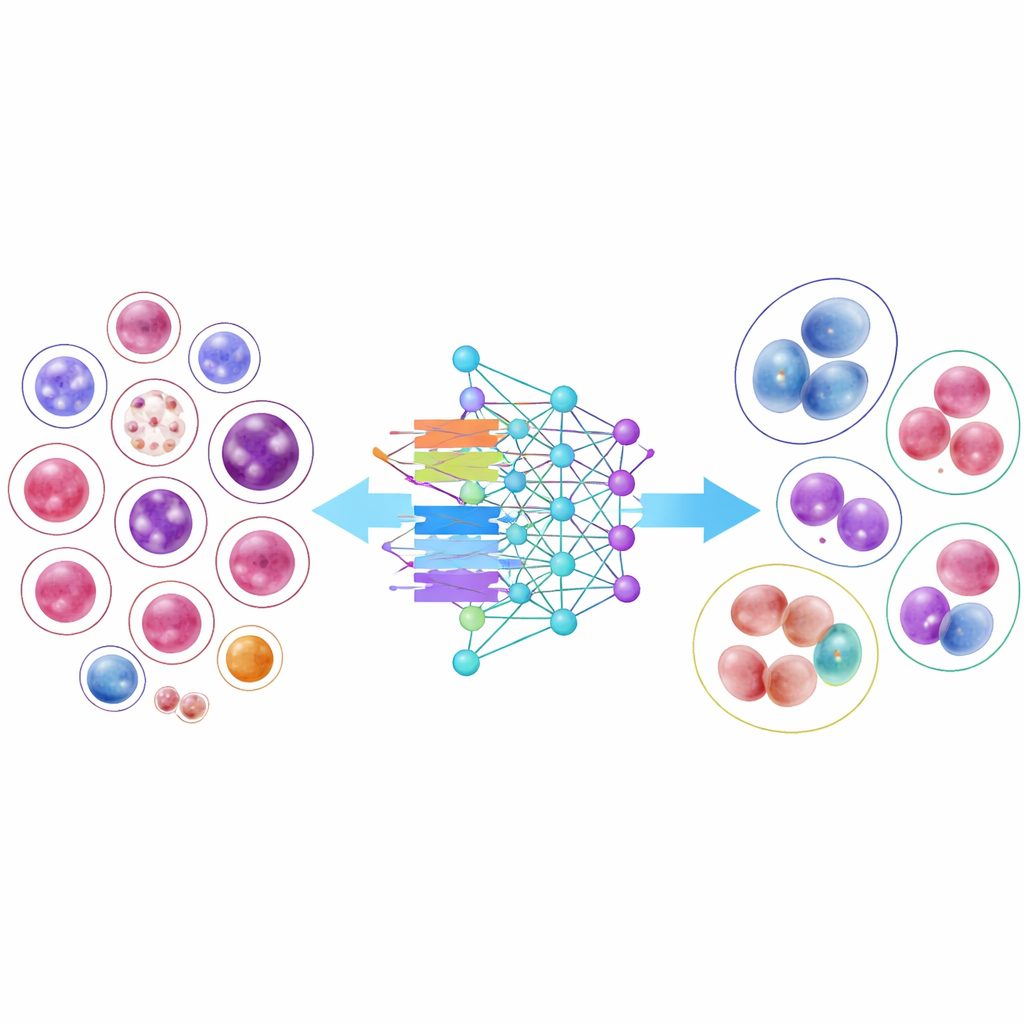
让AI模型接受考验
为展示该图书馆的实用性,研究者训练了14种现代图像识别模型,从经典卷积神经网络到新兴的基于变换器(transformer)的设计。若干紧凑且高效的模型表现出乎意料地好,其中一种架构DenseNet-121在平均上超过95%的时间正确分类。然而,结果也凸显了一个重要的现实难题:拥有数千张样本的常见细胞类型几乎可以被完美识别,而只有几十张图像的极其稀有细胞则仍然难以分类。即便研究者调整训练以“更多关注”这些稀少类别,总体准确率也下降,对稀有类型的改善有限,凸显了从有限样本中学习的挑战。
这对未来血液检测意味着什么
对非专业读者来说,关键信息是这项工作提供了计算机系统成为可信伙伴——协助阅读血涂片——所需的原始视觉经验。通过汇集一个大规模、多样且经严格检查的血细胞图像库,并展示多种不同的AI模型都能从中学习,作者为能加速诊断、减少人为错误并将专家级分析扩展到缺乏专科医生的诊所的工具奠定了基础。与此同时,关于稀有细胞类型的混合结果提醒我们,即便是大型数据集也有盲点,要改善对罕见或早期疾病患者的护理,还需进一步扩展和精炼这些图像集合。
引用: Yarıkan, A.E., Örer, C., Akyıldız, V. et al. A Large-Scale Peripheral Blood Cell Dataset for Automated Hematological Analysis. Sci Data 13, 417 (2026). https://doi.org/10.1038/s41597-026-06761-y
关键词: blood cell imaging, medical AI, hematology, deep learning, medical datasets