Clear Sky Science · zh
StatLLM:用于评估大型语言模型在统计分析中表现的数据集
这对日常数据使用者为何重要
随着基于聊天的人工智能助手成为日常工作的一部分,越来越多的人开始让它们处理数字、运行实验和分析数据。但是当人工智能为一项统计研究编写代码时——例如检验一种新医疗疗法是否有效或探索学校表现数据——我们如何确认其工作是否正确?本文介绍了 StatLLM,这是一个公开数据集,旨在测试大型语言模型处理真实统计分析任务的能力,为研究人员和从业者提供何时可以信任 AI 编写的代码、何时应保持谨慎的更清晰图景。
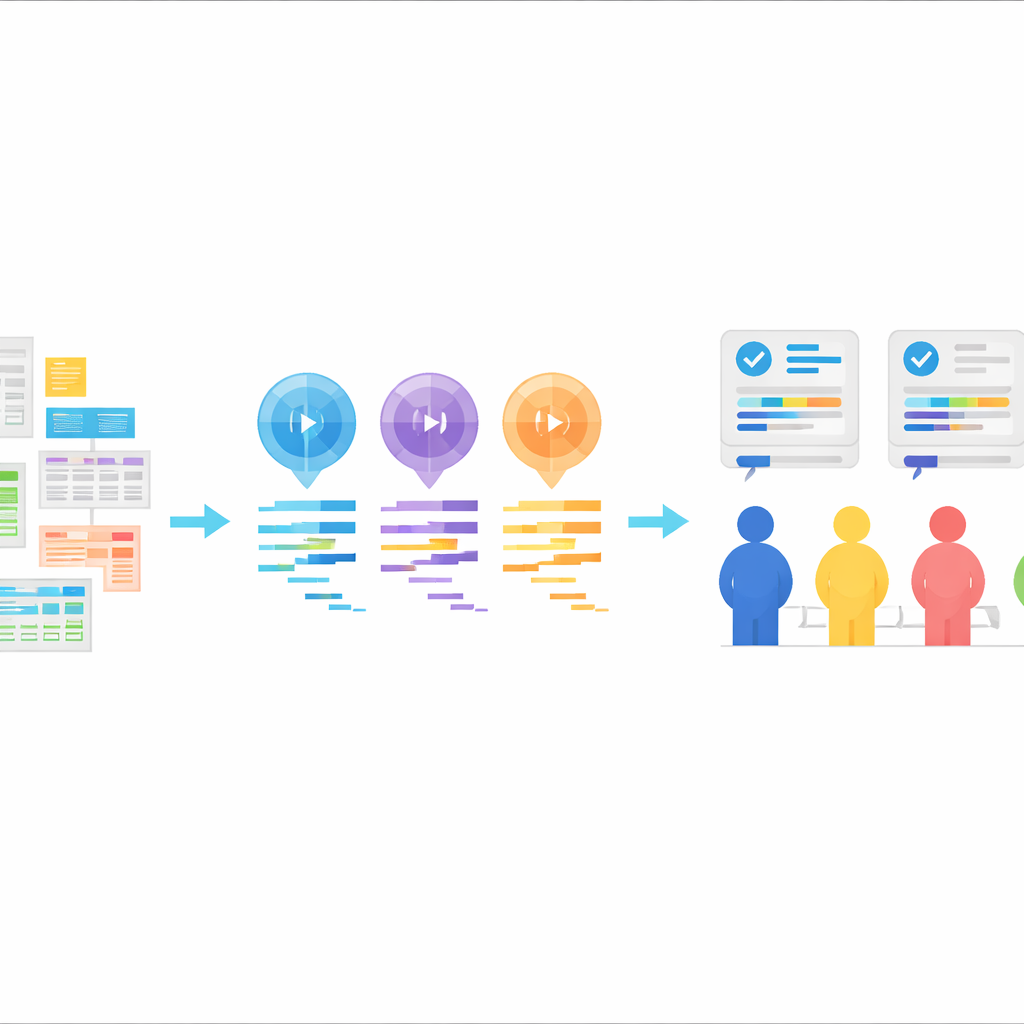
用于 AI 编写统计代码的新测试平台
StatLLM 的核心是一套精心汇编的 207 个统计分析任务,这些任务来自 65 个真实数据集,涵盖教育、医学、商业、金融、工程和体育等领域。每个任务都配有通俗的题目描述、对数据集及其变量的详细说明,以及由人工专家编写并审验过的一小段 SAS 代码。任务范围对应优秀本科生或硕士生可能学到的内容:从简单的数据汇总和图表,到回归、生存分析及更高级的方法。这样就为评估 AI 工具是否能理解实际问题并将其转化为可靠分析步骤提供了现实、类课堂与行业结合的测试场景。
让 AI 编写代码,然后评分其成果
利用这些任务,作者让三种大型语言模型——GPT-3.5、GPT-4 和 Llama‑3.1 70B——生成 SAS 代码。每个模型接收到相同的要素:任务描述、数据集说明、实际数据文件以及明确的生成 SAS 代码的指令。模型以“零样本(zero-shot)”方式使用,意味着在此之前没有向它们展示正确的 SAS 代码示例。模型的回复被清理,只保留代码,不含解释。该设置模拟了一种常见的现实模式:用户描述他们想要的内容,AI 返回代码,然后在统计软件中运行该代码。
以人类专家作为金标准
为了评估 AI 编写代码的真实水平,团队组织了严格的人类审查。九位有经验的 SAS 使用者组成三组,每组关注性能的一个方面:代码本身是否逻辑正确且可读,代码是否能实际运行而不报错,以及生成的输出是否清晰、准确地回答了原始问题。对于每个任务,来自三种模型的 SAS 程序会被打乱顺序,使评分者无法知道哪份代码来自哪个模型。评分采用五分制并汇总为总体得分,对数百个模型—任务组合的强项与弱项提供了细致视角。这些专家评分现在与 StatLLM 数据集中的所有代码和任务一并公开。
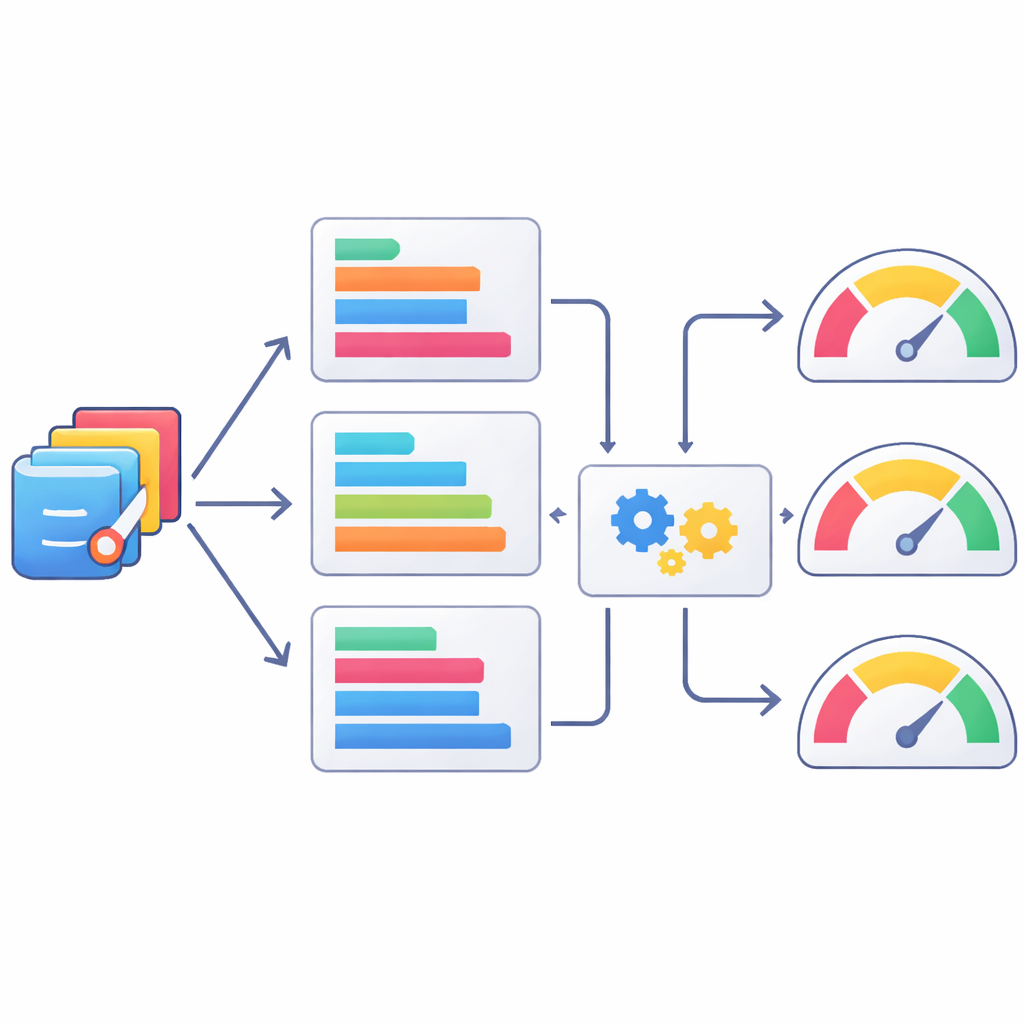
教机器像人一样评判代码
由于人工审查既慢又成本高,作者还探讨了基于文本的自动评估指标在多大程度上可以作为统计代码质量的粗略评判。他们使用一套常见的自然语言处理评分,将 AI 生成的 SAS 程序与人类验证版本进行比较,然后检查这些分数与人工评分的一致性。有些指标(如追踪短序列令牌重叠的 ROUGE 变体)与人工判断的相关性优于其他指标,但总体上相关性只是中等程度。团队进一步训练了机器学习模型,基于这些指标的组合作为输入来预测人工评分。像 XGBoost 之类的方法能提升与人工评分的匹配度,但仍远未能完美捕捉专家判断,这强调了自动分数最多只能作为部分代理。
为未来的 AI 驱动统计工具构建基础
除基准测试外,作者展示了 StatLLM 如何支持新的工具和研究方向。由于每个任务以通用术语描述,同样的问题可用于测试其他语言(如 R 或 Python)的代码生成,甚至可用于将多种语言的代码组合起来。论文强调了可通过混合不同 AI 生成方案以提高可靠性的集合方法,并演示了一个原型 R Shiny 应用,用户可以上传数据集和任务描述,AI 系统自动生成并运行 R 代码。StatLLM 还为设计和测试下一代统计软件提供了平台,使其在理解自然语言指令的同时,能够被明确且可衡量的标准所约束。
这对在数据分析中使用 AI 意味着什么
对非专业人士而言,主要结论是:AI 已能编写短小的统计代码片段——但其可靠性远非万无一失,尤其是在超出简单示例的任务上。StatLLM 提供了一种透明、可重复使用的方式来查看不同模型的表现、改进对其工作的自动检查,以及设计更安全、更稳健的数据分析工具。随着更新的语言模型出现,它们可以被接入到这个持续更新的基准中,从而让该领域对 AI 在严肃统计工作中能做与不能做的事情保持诚实的评估。
引用: Song, X., Lee, L., Xie, K. et al. StatLLM: A Dataset for Evaluating the Performance of Large Language Models in Statistical Analysis. Sci Data 13, 369 (2026). https://doi.org/10.1038/s41597-026-06731-4
关键词: 大型语言模型, 统计分析, 代码评估, 基准数据集, SAS 编程