Clear Sky Science · zh
美国专利审查意见书中的科学引文数据集
为什么专利引文对日常创新很重要
当你听说一种新型小工具、药物或清洁能源技术时,通常背后都有一条思想的线索。大量线索记录在专利及其所引用的文献中。本文介绍了一个大型新数据集,能够以前所未有的细节揭示专利审查员在决定某项发明是否值得保护时依赖哪些科学研究。通过打开对审查过程的这一隐秘窗口,作者为研究人员、政策制定者,甚至好奇的公众提供了一种新的方式来研究科学知识如何推动现实世界的创新。
专利流程中的一个隐秘层面
大多数关于专利的研究只看已授权专利封面上打印的引文。这些清单看似直接,但它们是申请人和官方审查员之间复杂互动的最终结果。在此过程中,审查员会发出称为审查意见(Office Actions)的正式函件,说明他们为何主张应当批准或拒绝专利,并引用他们认为重要的早期工作。许多被引用的条目,尤其是科学论文,从未出现在最终专利上。直到现在,这些资料难以批量获取,因此研究在很大程度上忽视了这一关于决策如何实际形成的丰富记录。
从审查意见构建一张新地图
作者利用了美国专利商标局发布并托管在 Google Cloud 上的一批审查意见数据。从数以百万计的引用中,他们筛选出约85万条并非指向其他专利、而是指向期刊文章、书籍、网站和产品手册等外部来源的引用。他们设计了一个包含14个日常类别的方案——从图书和会议录到网页和产品文档——然后训练了一个机器学习模型,将每条引文分类到这些类型之一。该模型在使用先进语言系统帮助标注的示例上不断改进,最终对近84.7万条独特的引文字符串进行了分类。
从混乱的参考到干净的研究记录
识别哪些引用是科学性的只是第一步。现实中的引用往往很混乱:标题可能不完整,年份输入错误,页码混乱。为将这些乱序字符串转化为可用数据,团队将原始字符串输入一个专门工具,将其解析为作者、年份、期刊和页码范围等字段,并应用谨慎的清洗规则。然后他们使用两种策略将这些清洗后的记录匹配到 OpenAlex——一个大型开放的研究出版物数据库。当存在标题时,他们通过标题搜索并仅保留高置信度匹配;当没有标题时,则依靠作者姓名、期刊、年份和页码的组合。如果 OpenAlex 找不到匹配,他们会退而求其次使用 Crossref(另一个主要的出版标识符来源),并利用发现的数字对象标识符回到 OpenAlex 进行查证。
这个新数据集有多可靠?
因为该资源旨在为未来研究提供基础,作者投入了大量精力来测试其准确性。他们的分类器总体上约有92%的情况下能正确地将引用分配到正确类型,在期刊文章和专利等最常见的类别上表现尤为出色。对于匹配步骤,人工核查显示基于标题的搜索随着匹配分数的提高而更准确,在最佳组中达到90%以上的准确率,而基于详细元数据的搜索在样本中有99%的正确率。通过 Crossref 恢复的记录的交叉核对也显示出近乎完美的一致性。作者对较弱的部分保持透明——例如论文或技术报告等罕见类别——并鼓励用户在需要时对这些部分进行改进。
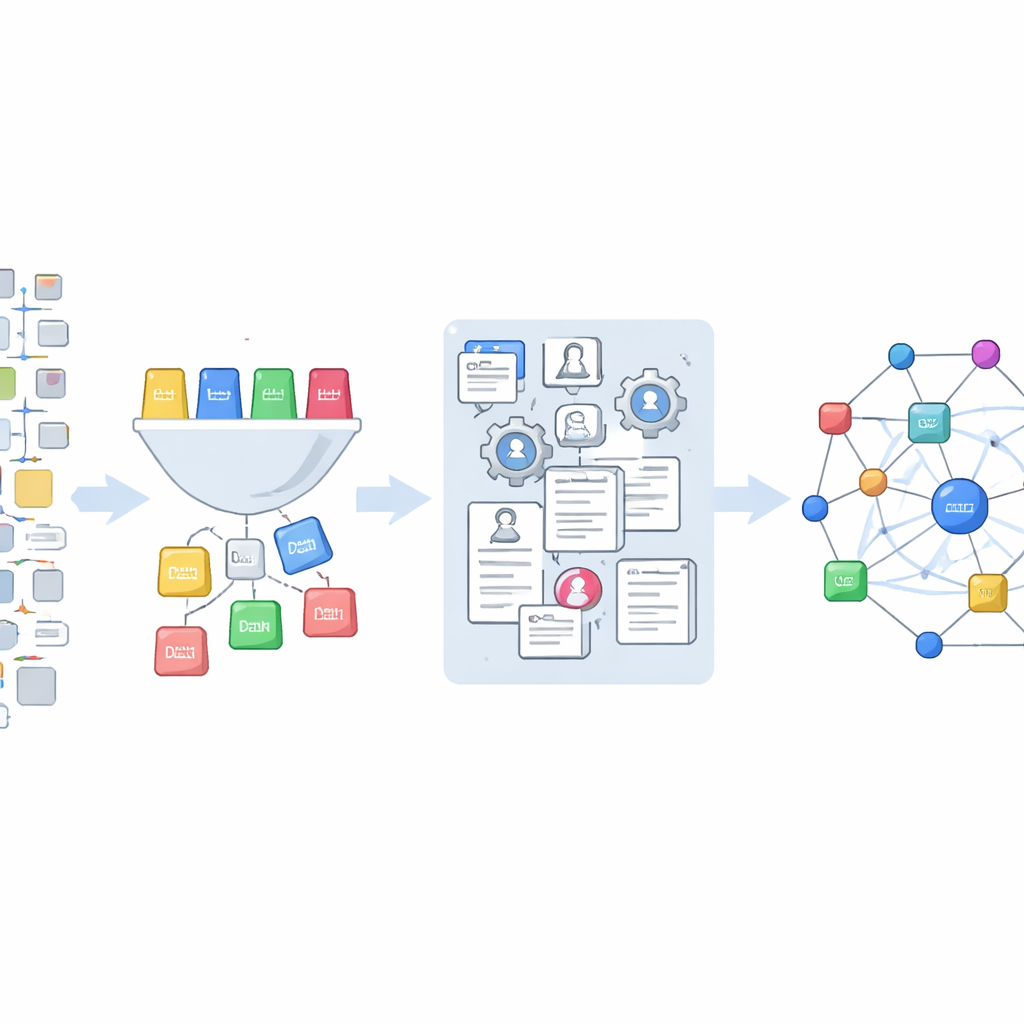
研究科学如何驱动技术的新途径
最终数据集将大约26.5万条来自审查意见的科学引用链接到单个美国专利申请以及 OpenAlex 中详尽的出版记录。这使研究人员能够提出新的问题:不同审查员群体或技术领域在多大程度上依赖科学论文?哪些研究在审查过程中被视为重要但在最终专利中消失?被放弃的专利在利用的科学记录上是否与成功的专利有所不同?因为所有代码和数据都已公开发布,他人可以改编这些工具、扩展覆盖范围并改进分类。简而言之,这项工作将一组晦涩且散乱的法律文档转变为一张清晰、可重复使用的地图,展示科学与技术在专利体系内部如何相遇。
引用: Higham, K., Kotula, H., Scharfmann, E. et al. A dataset of scientific citations in U.S. patent Office Actions. Sci Data 13, 325 (2026). https://doi.org/10.1038/s41597-026-06720-7
关键词: 专利引文, 审查意见书, 科学文献, 创新数据, OpenAlex