Clear Sky Science · zh
迈向自动化报告:用于增强多模态大语言模型的支气管镜报告数据集
为肺科医生提供更智能的帮助
当医生使用微型摄像头观察气道时,可以获得关于患者肺部的大量信息——但将所见转化为清晰、详尽的报告需要时间和经验。本研究介绍了一个新的、精心构建的真实支气管镜影像与报告集合,旨在教会先进的人工智能系统如何协助撰写此类报告。对于患者而言,这在未来可能意味着更快速、更一致的报告以及减少遗漏重要细节的机会。
为何观察肺内部很重要
支气管镜检查是一种将带有摄像头的细管引入气道以检查气管及其分支的操作。它帮助医生发现炎症、感染、肿瘤或出血等问题,也可用于指导处理,例如取出异物或置入小支架以维持气道通畅。检查后,医生必须在正式报告中描述所见内容,报告成为患者病历的一部分并指导治疗决策。撰写这些报告是细致且重复的工作,很大程度上依赖医生的培训和记忆。
为何现有数据不够
近年来,能够同时处理图像和文本的强大人工智能模型在解读医学影像和起草报告方面取得了进展。然而,对于支气管镜领域,用于训练此类系统的可用数据往往狭窄且不完整。早期数据集通常只覆盖少数任务——例如发现肿瘤或标注摄像头位置——而忽视了许多医生日常描述的常见发现,如粘液、轻度出血或肿胀。有些数据集还属于私有、规模小或仅关注简单的二元判断,使得它们不能很好地教会需要撰写丰富、类人化描述的人工智能模型。
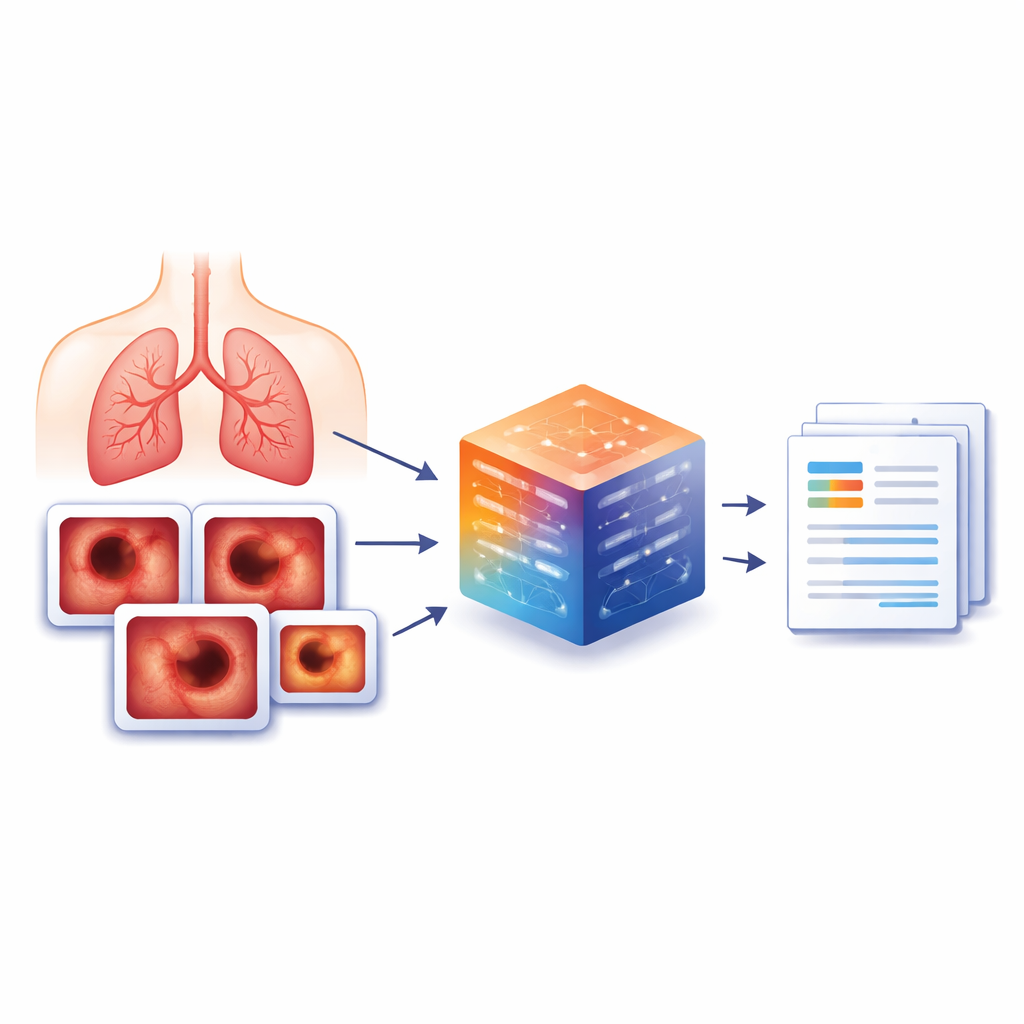
构建更丰富的影像库
为填补这一空白,作者创建了 BERD,这是一个基于中国某大型医院真实操作构建的支气管镜检查报告新数据集。从 2022 至 2023 年间完成的 8,477 次支气管镜检查中,他们挑选出 3,692 例具代表性的患者病例和 6,330 张医生标记为特别有信息量的关键图像。对于每幅图像,受过训练的临床人员将其与精确的书面描述关联,描述内容包括肿瘤、肿胀、沉积物或正常组织等。若图像显示无异常,则使用诸如“正常”之类的标准短语以保持数据一致性。个人信息被移除,原始中文报告通过本地运行的语言模型翻译成英文以保护隐私。
专家与人工智能如何协作
除了简单描述外,团队还希望为每张图像标注一个或多个医学类别——如“肿瘤”、“充血”或“水肿”——以便人工智能模型既能标注也能描述发现。为高效完成此任务,资深支气管镜专家先根据医学指南定义了详细的类别列表。随后,本地部署的语言模型扫描文本说明,建议每张图像适用的类别。人工专家对这些建议进行了仔细核查和修正,始终保留对医学质量的最终控制。结果是一个注释精细的资源,每幅图像都与清晰的描述、解剖位置和专家确认的标签相连接,并以研究人员可以直接使用的简单文件形式组织。
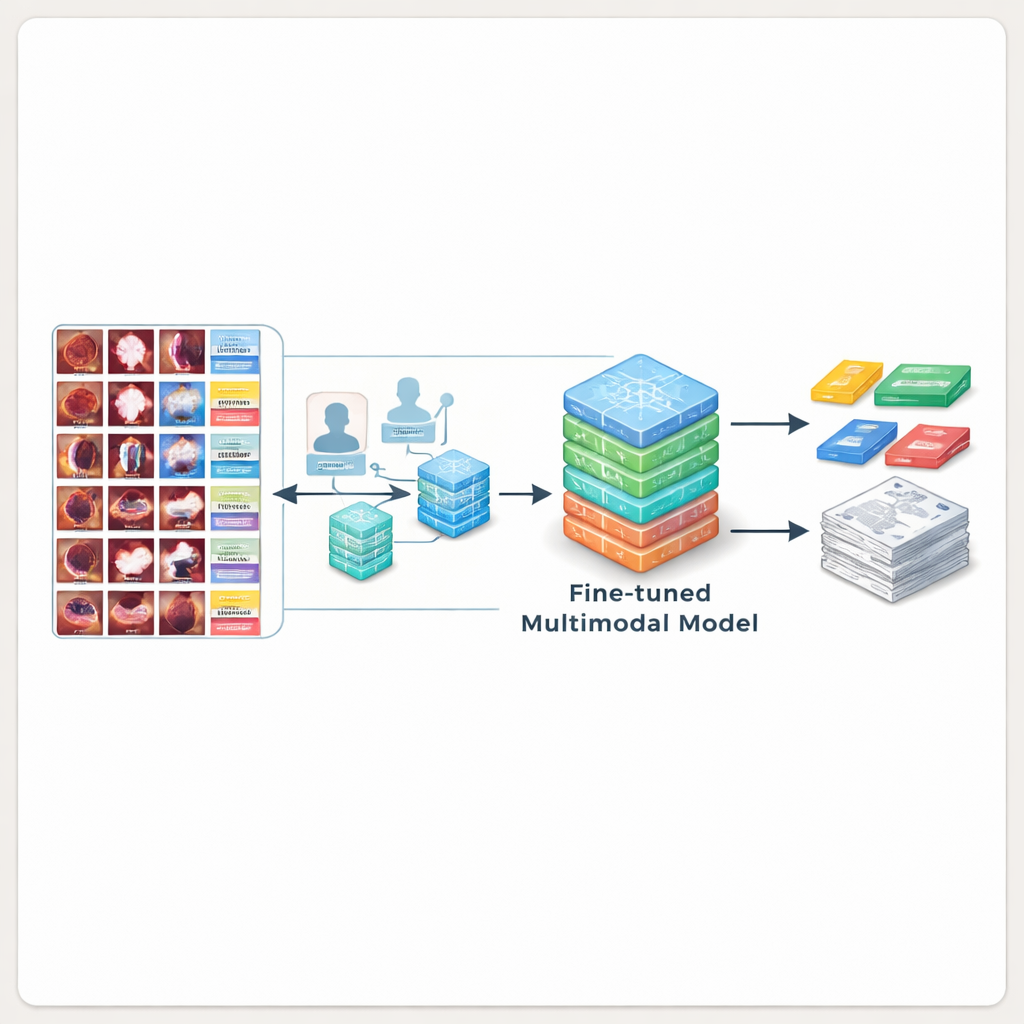
教人工智能写出更好的报告
为证明 BERD 的实际用处,研究人员用它训练了若干领先的多模态人工智能模型。首先,他们测试了从未见过支气管镜图像的一般用途模型和医学模型。这些模型经常误解所见,漏检肿瘤或杜撰细节,与专家撰写的文本相比得分较低。团队随后在 BERD 的图像与说明上微调了开源模型。经过额外训练后,表现最佳的模型生成的描述在措辞上与专家更为接近,且被临床医生判定为可接受的比例超过 80%——这意味着 AI 生成的文本常常可以以最少编辑直接放入真实报告中。
对未来医疗的意义
简而言之,这项工作提供了 AI 系统成为可靠支气管镜报告助手所需的“训练库”。尽管数据来自单一医院且为避免误导模型有意删除了一些数值细节,但该数据集是公开的、文档完善且规模足以为该领域树立新标准。随着研究者在 BERD 基础上继续发展,患者终有可能受益于更快速、更统一的支气管镜报告,从而让医生有更多时间专注于决策与治疗,而非文书工作。
引用: Luo, X., Huang, X., Liang, X. et al. Towards Automated Reporting: A Bronchoscopy Report Dataset for Enhancing Multimodality Large Language Models. Sci Data 13, 339 (2026). https://doi.org/10.1038/s41597-026-06692-8
关键词: 支气管镜, 医学影像, 临床报告, 多模态人工智能, 医学数据集