Clear Sky Science · zh
生物医学数据清单:一种轻量级数据文档映射以提升 AI/ML 的透明性
更智能的数据说明为何与您的健康息息相关
随着医院和研究人员争相利用人工智能来预测疾病和指导治疗,喂养这些工具的数据质量在悄然决定谁会受益——以及谁可能被忽视。本文提出了一种实用方法,用于为生物医学数据集“标注盒子”,让任何构建 AI 系统的人都能快速看到数据来源、代表哪些人群以及应当如何(或不应当)使用。通过简化此类文档,作者旨在让医学 AI 更公平、更安全、也更值得信赖。
医学数据中隐藏的故事
大多数大型生物医学数据集——包括化验结果、影像或治疗结局的集合——最初并非为 AI 而创建。它们常常缺乏关于数据如何收集、包含了哪些患者或随时间有哪些变动的清晰记录。这些缺失的细节可能掩盖偏差,例如某些群体被代表不足或关键信息记录不一致。当此类数据用于训练机器学习系统时,所得工具可能对部分患者有效,但对其他患者效果不佳,从而加剧现有的护理差距。作者认为,更好且标准化的文档对于在算法部署前揭示和管理这些风险至关重要。
将最佳思路合并为一份简明指南
在 AI 社区中已有若干“事实表”式的数据文档方法,例如 Datasheets for Datasets、Data Cards 和 HealthSheets。每种方法都提供关于数据集目的、内容、收集方式和局限性的结构化问题。然而,它们大多由计算机科学家为 AI 特定数据集设计,对于繁忙的生物医学研究人员来说可能冗长且难以完成。为避免重复造轮子,团队首先映射并协调了四个广泛引用模板中的字段,构建了包含 136 个问题的合并清单,以捕捉最重要的概念并消除重叠。随后,他们将该清单精炼为 100 个字段,分为七个直观类别,涵盖从基本信息和数据用途到伦理、法律约束以及标签如何创建等问题。
倾听使用与创建数据的人的声音
接着,研究人员邀请现实世界的生物医学利益相关者——包括临床医师、实验室科学家、数据管理者和计算专家——对每个文档字段对其工作的必要性进行评分。来自一个多中心癌症研究网络的 23 名参与者完成了调查。团队将受访者分为两类“角色画像”:更接近试验台或床边收集数据的人,以及主要负责管理、整理或分析数据的人。这揭示出明显的优先级差异。例如,两组都非常重视知道数据集的最后更新时间以及何时可能再次变更。但只有数据管理者和计算专家强烈强调有关标签如何分配或未来更新将如何进行的详细信息,而临床医师和实验室科学家则更强调数据的预期用途和不适用情况。
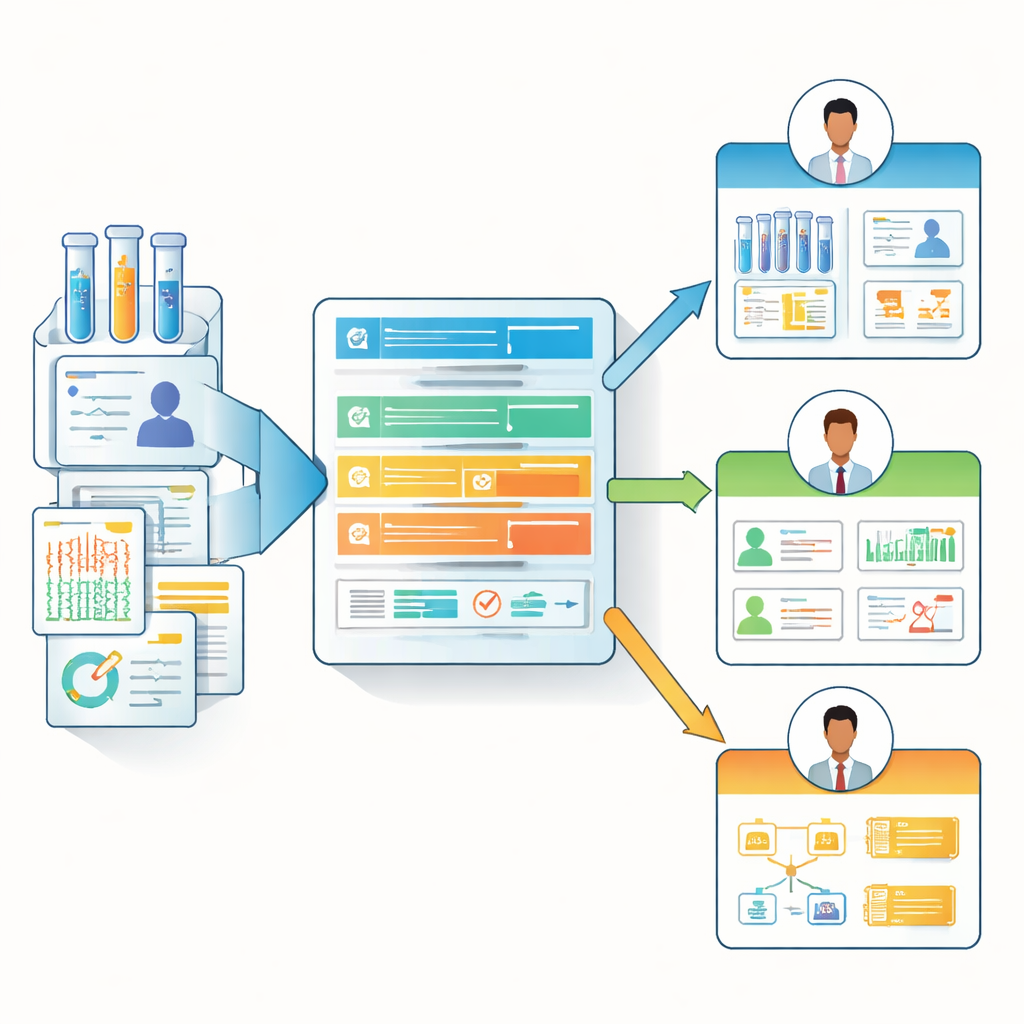
从一刀切到角色感知的数据说明
基于这些调查洞见,作者设计了“生物医学数据清单”,这是一种轻量的基于网络的文档模板,可适应不同角色。与其强制每位贡献者填写庞大清单,清单采用核心问题与可选详细问题的分层结构。它可以为不同角色突出最相关的字段——例如,为分析人员呈现数据来源和更新细节,而为前线研究人员和临床医师强调临床背景和约束。团队提供了现成可用的表单(例如 Microsoft Forms)、一个 HTML 展示模板,以及一个名为 BioDataManifest 的开源 R 包。该软件可以自动将调查响应转换为清晰的清单页面,甚至从基因组数据共享中心(Genomic Data Commons)和 dbGaP 等主要公共资源拉取信息,为现有数据集创建部分清单。
这对未来医学 AI 的意义
归根结底,生物医学数据清单是一种实用工具,使生物医学数据集的“细则”更易创建、共享和理解。通过将有关数据的文档与针对具体 AI 模型的文档分离,并根据不同用户角色定制展示内容,该框架降低了研究人员的负担,同时为下游用户提供判断数据集是否适用于特定目的所需的背景信息。通俗地说,它把不透明的医学数据集变成清晰标注的包裹,帮助 AI 开发者在影响患者之前发现局限性和潜在偏差。如果被广泛采纳,这种角色感知且可复用的文档可能使生物医学 AI 更透明、可复现且更具公平性。
引用: Bottomly, D., Suciu, C.G., Cordier, B. et al. Biomedical Data Manifest: A lightweight data documentation mapping to increase transparency for AI/ML. Sci Data 13, 414 (2026). https://doi.org/10.1038/s41597-026-06670-0
关键词: 生物医学数据文档, 医学中的负责任 AI, 数据集透明性, 机器学习偏差, 数据治理