Clear Sky Science · zh
通过共同责任与社区参与避免蛋白质组学数据的“数字墓地”
为什么你的医学数据不应落入数字墓地
现代医学越来越依赖描述细胞中数千种蛋白的大型数据集。这些文件常常在网上公开共享,承诺其他科学家可以在不做新实验的情况下复核结果或提出新问题。但如果数据以混乱的格式发布、缺少关键细节或依赖专有软件,它们就会成为“数据墓地”:对所有人可见,却实际上无法使用。本文展示了一门大学课程如何让学生成为数据侦探揭露这一隐蔽问题——并提出了可以使共享数据真正可重用的简单改进方法。
通过重做真实研究来学习科学
在赫尔辛基大学,一门质谱蛋白质组学研究生课程要求学生做一件有挑战性的事:从一个大型仓库中挑选真实的、公开可得的蛋白质数据集,尝试复现已发表的结论。学生以小组形式工作,从 ProteomeXchange 网络下载了六个项目,该网络托管来自世界各地许多实验室的质谱结果。使用 R 语言的共享分析流程,学生们遵循与原研究者相同的主要步骤:鉴定蛋白、测量丰度、清理数据,并检验在疾病与健康组织等条件间哪些蛋白发生了变化。
宏大承诺下缺失的指引
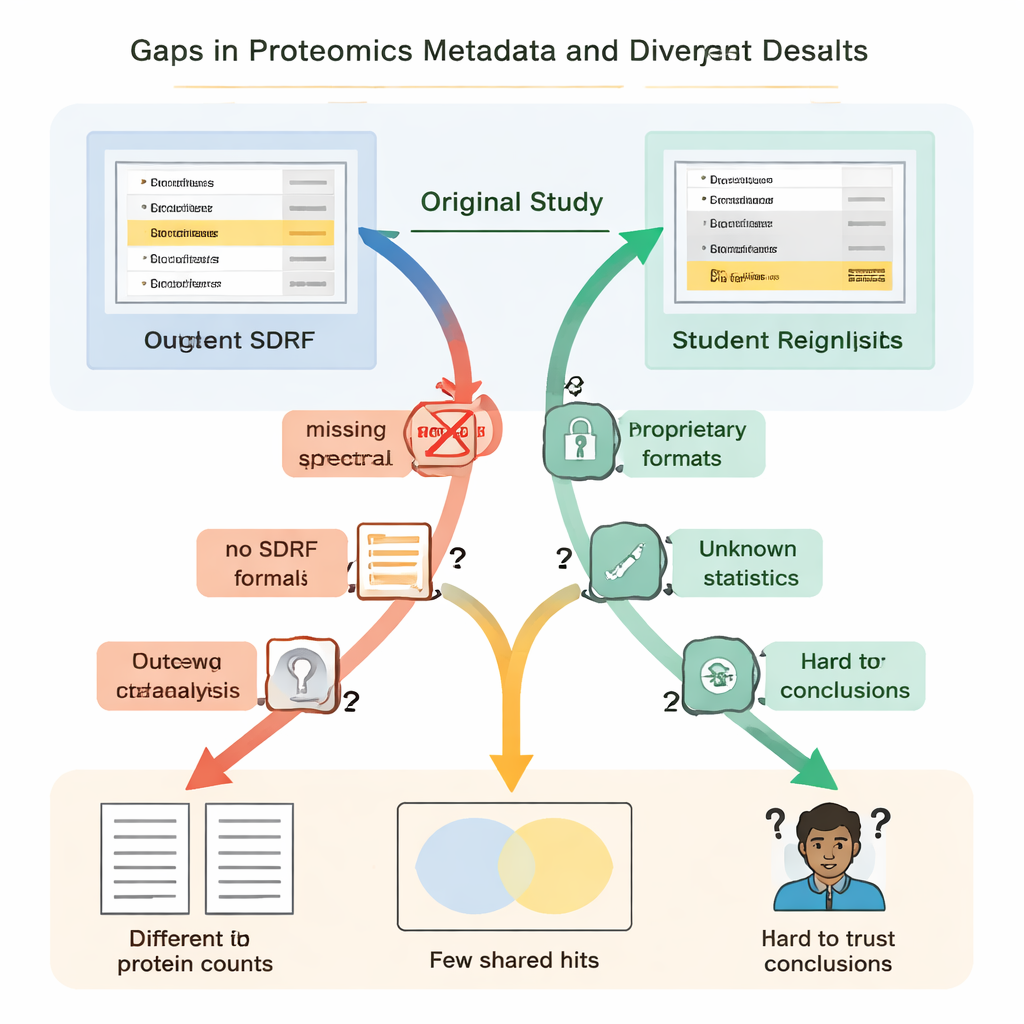
学生很快发现,“开放”并不总等于“可重用”。在每个案例中,关键指示要么缺失、要么难以找到。样本与数据文件之间的关键关联没有以简单、可机器读取的格式描述,因此小组不得不通过阅读论文和破译文件名来猜测哪些原始文件对应哪些生物学分组。关于如何控制假阳性的细节——例如使用特殊“诱饵”蛋白序列——也未说明,导致无法严格评估报告的蛋白列表有多可信。在若干项目中,主要结果被锁在专有文件格式中或依赖商业软件,学生无法获得这些软件,被迫从头重做分析的大部分工作。
小缺失引发的大差异
这些缺失不只是麻烦;它们导致了截然不同的科学结论。在一项肾脏疾病研究中,原作者报告了略低于五千种蛋白,而学生的复分析——使用开放工具和自建的谱库——发现超过一万三千种。在原论文中被强调为特别重要的某个蛋白,在底层鉴定文件中并不令人信服,在学生的流程中根本未被检测到。在另一个案例中,原研究列出在条件间发生变化的蛋白为108种,但学生从相同的原始数据出发、由于缺乏关于原始统计方法的完整信息,只能有把握地标出11种。此外,上载文件中缺少生物学重复样本意味着无法进行适当的统计检验。
一个“可重用”数据集应包含的内容
从这六个案例中浮现出一个清晰模式:可重复性的主要障碍并非质谱仪本身,而是结果的打包与共享方式。作者认为,每个蛋白质组学数据集都应附带一个最小的可再分析包。该包包括原始数据以及开放、社区标准的结果格式;将每个样本与其实验条件关联的标准化表格;基本的质量控制摘要;任何为重复检索所需的谱库或蛋白序列文件;以及完整的分析参数和代码,最好与有版本控制的软件容器一同存储。数据仓库、期刊和审稿人可以通过推动或要求提交者事先提供这一捆绑包来助力,使其他人无需从零散线索重建工作流程。
在修复系统的同时培养科学家
这门课程本身具有双重目的。对学生来说,它提供了一个动手掌握复杂蛋白质组学方法、统计学与编程的途径,同时揭示了当文档不完整时已发表结论的脆弱性。对更广泛的社区而言,学生的努力成为当前数据共享实践的压力测试,准确地暴露出元数据和分析记录的不足之处。作者建议可以在其他地方开设类似课程,将课堂变成持续推动更清晰、更透明数据的质量控制引擎。
从数据墓地走向活跃资源
简而言之,文章得出结论:许多当前存放在公共仓库中的蛋白质数据集有成为数字墓地的风险——这些昂贵的实验结果无法被可靠地检验或扩展。然而解决办法相对直接:将元数据、开放格式和可共享代码视为实验的组成部分,而非事后补充。如果研究者、审稿人和仓库共同坚持在共享蛋白质组学数据时提供一个简单且良好记录的包,这些数据集就能保持“活跃”:随时可被重新分析、与新研究合并,并用于强化生物医学发现背后的证据。
引用: Vadadokhau, U., Soliman, M., Castillon, L. et al. Preventing Proteomics Data Tombs Through Collective Responsibility and Community Engagement. Sci Data 13, 287 (2026). https://doi.org/10.1038/s41597-026-06614-8
关键词: 蛋白质组学, 数据可重复性, 开放科学, 质谱, 研究数据共享