Clear Sky Science · zh
基于Transformer的关系抽取与概念规范化:使用经注释的临床试验语料库
帮助医生更快找到合适的患者
每项临床试验都依赖于找到符合长长一列医疗条件、治疗方案和时间窗的患者。如今,医生常常需要手工阅读电子病历和试验说明,这既缓慢又容易出错。本文介绍了一个大规模且经仔细校验的西班牙语临床试验文本集合,并展示了现代人工智能如何将这些非结构化语言转化为有序数据,从而为更快速、更公平、更精准的医学研究铺平道路。
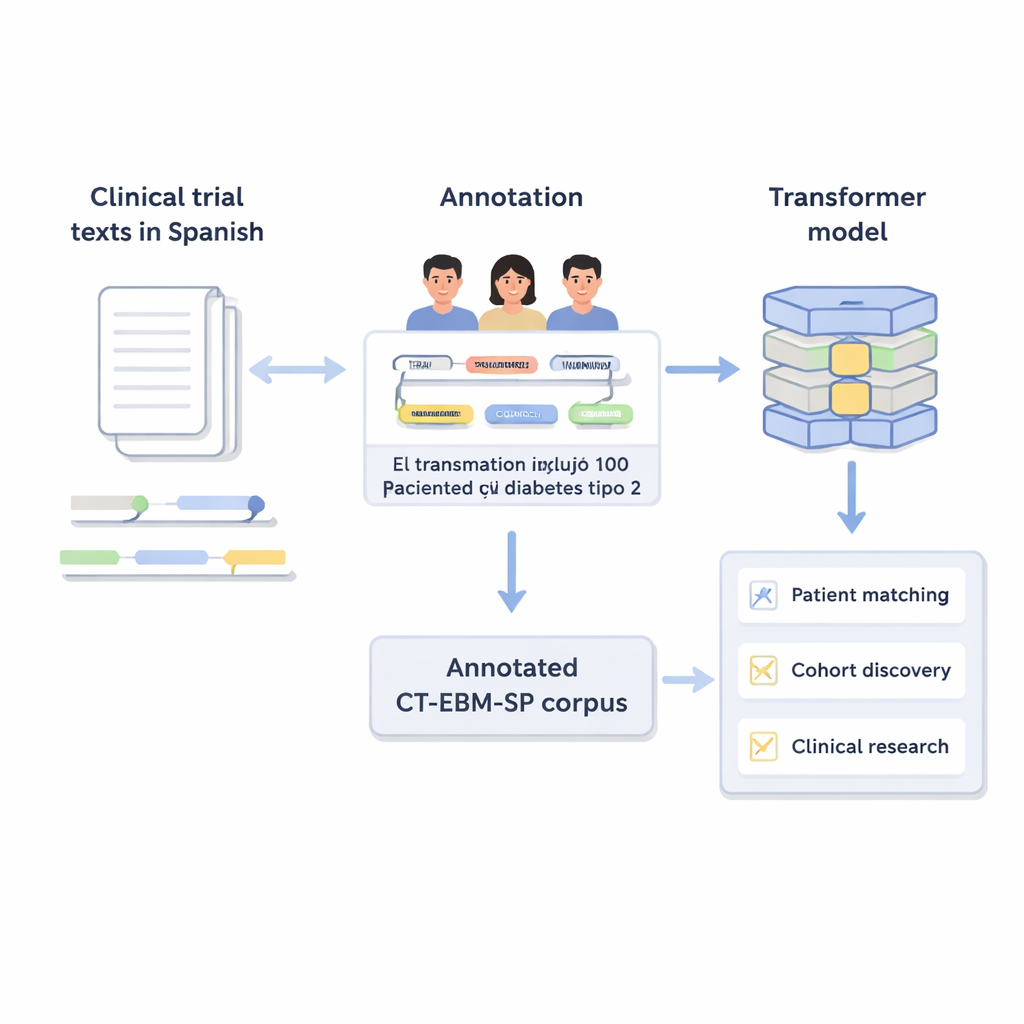
将自由文本变成有组织的信息
临床试验使用通用医疗语言描述谁可以或不可以参与:年龄限制、既往疾病、化验结果和尝试过的治疗等。计算机处理这种自由文本很困难。作者创建了CT‑EBM‑SP语料库的第3版,该数据集包含1200篇西班牙语临床试验文本,近30万词。人工专家对这些文本进行了标注,标出23类医学实体,例如疾病、药物、检验结果和时间表达,以及表示否定(例如“无病史”)和不确定性的线索。他们还标注了11种属性,用来捕捉事件是否发生在过去或将来,以及是发生在患者本人还是家庭成员等细节。
让医学术语说同一种话
医学中的一个主要挑战是同一概念可以有多种书写方式。为了解决这一问题,研究团队将大多数标注的实体链接到统一医学语言系统(UMLS)中的标准化代码——这是一个庞大的多语言医学词典。这个步骤称为概念规范化,意味着不同拼写或措辞都指向相同的唯一标识符。例如,“25‑羟基维生素D”的多种变体都映射到单一的UMLS概念。总体上,语料库包含超过87,000个实体和超过68,000条关系,约有82%的实体成功被规范化。两位专家独立复核了这些链接,达成了很高的一致性,表明注释是可靠的。
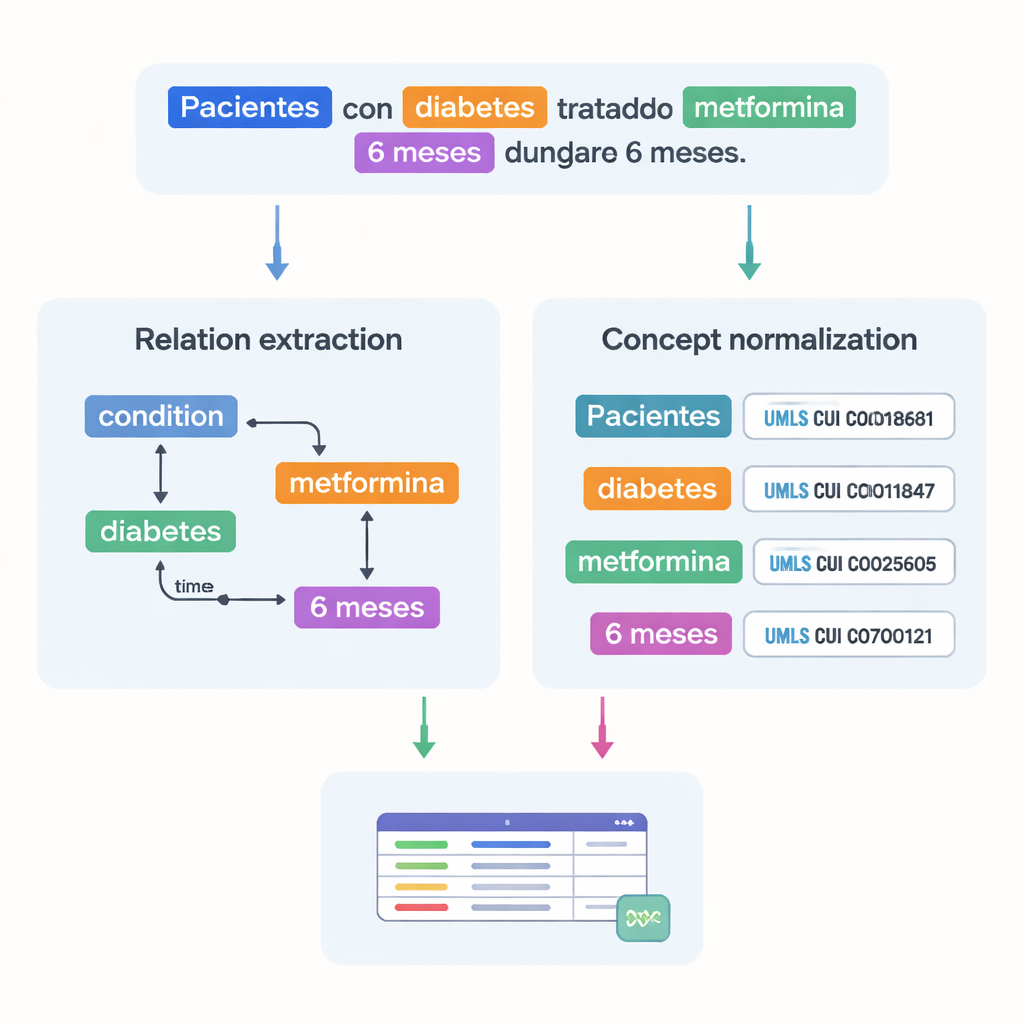
捕捉医学事实之间的相互关系
数据集不仅列出医学术语,还记录它们之间如何相互关联。作者设计了18类关系来捕获在试验中重要的模式,例如哪个剂量属于哪个药物、治疗持续多长时间或患者经历了哪种病症。时序关系显示一个事件是在另一个事件之前还是之后,其他链接则标示疾病发生在身体哪个部位,或短语是否表达否定或推测。综合这些关系,计算机可以构建患者情境的图谱——谁是患者、他们有什么病、接受何种治疗、以及时间安排——而不仅仅是识别孤立的词项。
训练与测试现代人工智能模型
为证明该语料库在实际中的可用性,作者微调了多种基于Transformer的AI模型,包括多语言版本的BERT和RoBERTa。他们在两个任务上训练这些模型:关系抽取(学习恢复实体之间的链接)和医学概念规范化(将文本映射到UMLS代码)。在关系抽取任务中,表现最好的模型取得了接近0.88的F1分数,意味着它在较少错误的情况下正确识别了大多数关系。对于概念规范化,一个名为SapBERT的多语言模型在未额外训练的情况下,首次预测即正确的比例接近90%。这些结果表明,即便没有大规模通用语言系统,经过良好注释的中等规模数据集也能驱动准确且高效的模型。
该资源对未来医疗为何重要
CT‑EBM‑SP语料库及其相关模型为能够自动解析西班牙语临床试验文本、将其与患者记录比对并支持医院队列发现的工具提供了基础。由于数据与国际医学标准对齐并由专家细致校验,它们也有助于为数字工具较少的其他语言开发类似资源。通俗地说,这项工作旨在让合适的患者更容易、更安全地被推荐参加合适的试验,加速医学发现,同时减轻医疗人员的负担。
引用: Campillos-Llanos, L., Valverde-Mateos, A., Capllonch-Carrión, A. et al. Transformer-based relation extraction and concept normalization using an annotated clinical trials corpus. Sci Data 13, 280 (2026). https://doi.org/10.1038/s41597-026-06608-6
关键词: 临床试验, 医学文本挖掘, 西班牙语医疗, Transformer模型, 循证医学